| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

|
|
| GENERICS | |
|
LAMBDAS |
|
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
The Lambda Tutorial is available in PDF format (330KB)
The Lambda Reference (note: it is an incomplete draft version) is available in PDF format (1200KB)
Keep in mind that part of the Lambda/Streams Tutorial & References is still in draft version.
![]()
Lambda Expressions
Background and a Bit of Trivia
What are Lambda Expressions?
Merely looking at it tells that a lambda expression is something like a method without a name. It has everything that a method has: an argument list, which is the (int x) part of the sample lambda, and a body, which is the { return x+1; } part after the arrow symbol. Compared to a method a lambda definition lacks a return type, a throws clause, and a name. Return type and exceptions are inferred by the compiler from the lambda body; in our example the return type is int and the throws clause is empty. The only thing that is really missing is the name. In this sense, a lambda is a kind of anonymous method. ad-hoc functionality
Lambda Expressions vs. Anonymous Inner Classes
File f = new File(s, this);
if ((filter == null) || filter.accept(f))
files.add(f);
}
return files.toArray(new File[files.size()]);
}
The listFiles(FileFilter) method takes a piece of functionality as an argument. The required functionality must be an implementation of the FileFilter interface:
public interface FileFilter {
boolean accept(File pathname);
}
A file filter is a piece of functionality that takes a File object and returns a boolean value. The listFiles method applies the filter that it receives as an argument to all File objects in the directory and returns an array containing all those File objects for which the filter returned true .
For invocation of the listFiles method we must supply the file filter functionality, i.e. an implementation of the FileFilter interface. Traditionally, anonymous inner classes have been used to provide ad hoc implementations of interfaces such as FileFilter .
Using an anonymous inner class the invocation of the listFiles method looks like this:
File myDir = new File("\\user\\admin\\deploy");
if (myDir.isDirectory()) {
File[] files = myDir.listFiles(
new FileFilter() {
public boolean accept(File f) { return f.isFile(); }
}
);
}
Using a lambda expression it looks like this:
File myDir = new File("\\user\\admin\\deploy");
if (myDir.isDirectory()) {
File[] files = myDir.listFiles(
(File f) -> { return f.isFile(); }
);
}
The example illustrates a typical use of lambdas. We need to define functionality on the fly for the purpose of passing it to a method. Traditionally, we used anonymous inner classes in such situations, which means: a class is defined, an instance of the class is created and passed to the method. Since Java 8, we can use lambda expressions instead of anonymous inner classes. In both cases we pass functionality to a method like we usually pass objects to methods: This concept is known as "code-as-data", i.e. we use code like we usually use data. Using anonymous inner classes, we do in fact pass an object to the method. Using lambda expressions object creation is no longer required [4] ; we just pass the lambda to the method. That is, with lambda expression we really use "code-as-data".
In addition to getting rid of instance creation, lambda expressions are more convenient. Compare the alternatives:
Using an anonymous inner class it looks like this:
File[] files = myDir.listFiles(
new FileFilter() {
public boolean accept(File f) { return f.isFile(); }
}
);
Using a lambda expression it looks like this:
File[] files = myDir.listFiles(
(File f) -> { return f.isFile(); }
);
We will later [5] see, that in addition to lambda expressions there is a feature called method references . They can be used similar to lambdas. With a method reference the example looks even simpler.
Using a method reference it looks like this:
File[] files = myDir.listFiles(
File::isFile
);
Clearly, use of a lambda expression or a method reference reduces the file filter to its essentials and much of the syntactic overhead that definition of an anonymous inner class requires is no longer needed. method & function difference
Methods vs. Functions
Functional languages are declarative as opposed to imperative . They describe what a program should accomplish, rather than describing how to go about accomplishing it. In a declarative language the programmer does not dictate which steps must be performed in which order. Instead, there is a clear separation between what is done (this is what the programmer declares) and how it is done (this is determined elsewhere, by the language or the implementation). In pure functional languages such as Haskell the functions do not have any side effects. In particular, they do not modify data or objects. If no side effects occur, order does not matter. Consequently it is easy to achieve a clear separation between "how" and "what" is done.
Hence there are the following differences
between the concept of methods and pure functions :
|
|
Method
|
Pure
Function
|
|
Mutation
|
A
method
mutates
,
i.e., it modifies data and produces other changes and side effects.
|
A
pure function
does not mutate
;
i.e., it just inspects data and produces results in form of new data.
|
|
How
vs. What
|
Methods
describe
how
things
are done.
|
Pure
functions
describe
what
is
done rather than how it is done.
|
|
Invocation
Order
|
Methods
are used
imperatively
,
i.e., order of invocation matters.
|
Pure
functions are used
declaratively
;
i.e., order of invocation does not matter.
|
|
Code
vs. Data
|
Methods
are
code
,
i.e., they are invoked and executed.
|
Functions
are
code-as-data
;
i.e., they are not only executable, but are also passed around like data.
|
The bottom line is:
• We can express methods in Java. These are the methods of Java classes that we are familiar with. They are executed, they may mutate data, the order of their invocation matters, and they describe how things are done.
•
We
can express
pure
functions
in Java. Traditionally, functions
were expressed as anonymous inner classes and now can be expressed as lambda
expressions. Lambdas and anonymous classes are passed around like data,
typically as arguments to a method. If they do not modify data they are
pure
functions.
In this case their invocation order does not matter and they describe what
is done rather than how it is done.
Since Java is a hybrid language (object-oriented with functional elements), the concepts are blurred. For instance, a method in Java need not be a mutator. If it does not modify anything, but purely inspects data, then it has properties of a function. Conversely, a function in Java (i.e., an anonymous inner class or lambda expression) need not be pure. It may modify data or produce other side effects, in which case it has properties of a method. Despite of the fuzziness in practice, it may be helpful to keep the concepts of "method" and "function" in mind.
Let us revisit the previous example of a file filter to check what the concepts look like in practice:
File myDir = new File("\\user\\admin\\deploy");
if (myDir.isDirectory()) {
File[] files = myDir.listFiles(
(File f) -> { return f.isFile(); }
);
}
The listFiles method of class java.io.File is a method . It operates on the static and non-static data of the File object it is invoked on. A File object contains fields that give access to properties of the file system element it represents, e.g. its pathname, whether it is a file or a directory, which other elements it contains, etc. These fields are accessed by the listFiles method.
The listFiles method takes a file filter as an argument. The file filter is a function , here expressed as a lambda expression. It is passed to the listFiles method which then applies it to all files and directories in myDir . The example illustrates the code-as-data principle: the function (i.e. the file filter lambda) is passed to an operation (i.e. the listFiles method). It also illustrates the separation between "what" and "how": the function describes "what" is supposed to be applied to all files and directory and the receiving method controls "how" the filter is applied, e.g. in which order. In addition, the example illustrates the principle of a pure function: the file filter does not produce side effects; it just takes a File and returns a boolean .
In contrast, here is an example of an impure function:
File myDir = new File("\\user\\admin\\deploy");
final LongAdder dirCount = new LongAdder();
final LongAdder filCount = new LongAdder();
if (myDir.isDirectory()) {
myDir.listFiles( (File f) -> {
if (f.isDirectory()) {
dirCount .increment();
return false;
}
if (f.isFile()) {
filCount .increment();
return true;
}
return false;
}
);
}
The file filter is again expressed as a lambda, but this time it produces side effects, namely incrementing two counters.
After this excursion into the realm of programming language principles, we know that lambda expressions in Java denote (pure or impure) functions. As Java is an object-oriented and not a functional programming language the question is: How are lambdas aka functions integrated into the Java programming language? runtime representation
Representation of Lambda Expressions
}
Here is the receiving side, i.e., the implementation of the listFiles method from class java.io.File :
public File[] listFiles( FileFilter filter ) {
String ss[] = list();
if (ss == null) return null;
ArrayList<File> files = new ArrayList<>();
for (String s : ss) {
File f = new File(s, this);
if ((filter == null) || filter.accept (f))
files.add(f);
}
return files.toArray(new File[files.size()]);
}
The listFiles method take a FileFilter object and invokes its accept method.
The example demonstrates that a lambda expression has properties in common with functions and objects, depending on the point of view.
• Conceptually, a lambda expression is a function . It is an unnamed piece of reusable functionality. It has a signature and a body, but no name. It may or may not be pure, i.e., may or may not have side effects. We pass it around as an argument to a method or as a return value from a method.
•
When
a lambda expression is passed as an argument to a method the receiving
method treats it like an
object
. In the example the lambda expression
(or more precisely, a reference to the lambda expression) is received
as the argument of the
listFiles
method. Inside the
listFiles
method the lambda expression is a reference to an object of a subtype of
the
FileFilter
interface.
This
lambda object
is a regular object; e.g. it has an address and
a type.
Basically, you think in terms of a function when you define a lambda expression and in terms of a method when you use it. The lambda object that links definition and use together is taken care of by the compiler and the runtime system. We as users need not know much about it.
Practically all decisions regarding the representation and creation of the lambda object (short for: the object that represents a lambda expression at runtime) are made by the compiler and the runtime system. This is good, because it enables optimizations under the hood that we as users neither want to deal with nor care about. For instance, from the context in which the lambda expression is defined the compiler captures all information that is needed to create a synthetic type for a lambda object, but the compiler does not yet create that type; it just prepares the type generation. The actual creation of the lambda object's synthetic type and the creation of the lambda object itself are done dynamically at runtime by the virtual machine. For this dynamic creation of the synthetic lambda type and the lambda object the invokedynamic byte code is used, which was added to Java in release 7. Using these dynamic features it is possible to delay the creation until first use, which is an optimization: if you just define, but never use, the lambda expression then neither its type nor the lambda object will ever be created. [6] type of lambda expression target type functional interface
Functional Interfaces
void run()
. There are many
more:
Readable
,
Callable
,
Iterable
,
Closeable
,
Flushable
,
Formattable
,
Comparable
,
Comparator
,
or the
FileFilter
interface, which
we have been using in the previous example.
As functional interfaces and lambda expressions both deal with a single method, the language designers decided that the compiler would convert each lambda expression to a matching functional interface type. This conversion usually happens automatically, because lambda expressions may only appear in a context where such a conversion is feasible.
Let us reconsider the previous example:
File[] files = myDir.listFiles(
(File f) -> { return f.isFile(); }
);
The high-lighted part is the lambda expression. It appears as the argument to the invocation of the listFiles method of class java.io.File . The compiler knows the signature of method listFiles and finds that the method declares java.io.FileFilter as its parameter type. Hence the required type in this particular context is FileFilter .
Here is what the FileFilter interface looks like:
public interface FileFilter { boolean accept(File
pathname); }
FileFilter requires exactly one method and for this reason is a functional interface type. Our lambda expression has a matching signature: it takes a File argument, returns a boolean value and throws no checked exception. Hence the compiler converts the lambda expression to the functional interface type FileFilter . Inside the listFiles method the lambda is then indistinguishable from an object of type FileFilter . Here is the implementation of method File.listFiles :
public File[] listFiles( FileFilter filter ) {
String ss[] = list();
if (ss == null) return null;
ArrayList<File> files = new ArrayList<>();
for (String s : ss) {
File f = new File(s, this);
if ((filter == null) || filter.accept(f) )
files.add(f);
}
return files.toArray(new File[files.size()]);
}
Inside this method the lambda is bound to the filter argument. The lambda's functionality is triggered when the functional interface's method is invoked, i.e. when filter.accept() is called.
The conversion to a functional interface can have funny effects, demonstrated in the following example:
Say, we have two functional interfaces:
public interface FileFilter { boolean accept(File
pathname); }
and
public interface Predicate<T> { boolean test(T
t); }
Our lambda is convertible to both functional interface types [8] :
FileFilter filter = (File f) -> { return f.isFile(); };
Predicate<File> predicate = (File f) -> { return
f.isFile(); };
filter = predicate; // << error: incompatible types
If, however, we try to assign the two resulting variables to each other the compiler would flag it as an error, although the two variables represent the same lambda expression. The reason is that the two variables to which the lambda is bound are of two different, incompatible types.
Also, there might occasionally be situations in which the compiler cannot figure out a matching functional interface type, like in this example:
Object ref = (File f) -> { return f.isFile(); };
The assignment context does not provide enough information for a functional type conversion and the compiler reports an error. Adding a type cast easily solves the problem:
Object ref =
(FileFilter)
(File f) -> { return f.isFile(); };
By and large, functional interface conversion is a way to keep matters simple and avoid the addition of function types to Java's type system. [9]
Comparing Lambdas to Anonymous Inner Classes
Syntax
Lambda expression in various forms including method reference:
File[] files = myDir.listFiles( (File f) -> {return f.isFile(); } );
File[] files = myDir.listFiles( f -> f.isFile() );
File[] files = myDir.listFiles( File::isFile );
Runtime Overhead
A lambda expression needs functional interface conversion and eventually invocation. The type inference required for the functional interface conversion is a pure compile-time activity and incurs no cost at runtime. As mentioned earlier, the creation of the lambda object and its synthetic type is performed via the invokedynamic byte code. This allows to defer all decisions regarding type representation, the instance creation, and the actual invocation strategy to runtime. This way the JVM can choose the optimal translation strategy. For instance, the JVM can reduce the effort to the invocation of a constant static method in a constant pool, which eliminates the need for a new class and/or a new object entirely.
The bottom line is that lambda expressions have the potential for optimizations and reduced runtime overhead compared to anonymous inner classes. [10] variable binding
Variable Binding
Runnable r = new Runnable() {
public void run() {
System.out.println("count: " + cnt );
}
};
Thread t = new Thread(r);
t.start();
cnt ++; // error: cnt is final
}
The anonymous inner class that implements the Runnable interface accesses the cnt variable of the enclosing method. It may do so, because the cnt variable is declared as final . Of course, the final cnt variable cannot be modified.
Lambda expressions, too, support variable binding. Here is the same example using a lambda expression:
void method() {
int
cnt
= 16;
Runnable r = () -> { System.out.println("count:
" +
cnt
); };
Thread t = new Thread(r);
t.start();
cnt ++; // error: cnt is implicitly final
}
The difference is that the cnt variable need not be declared as final in the enclosing context. The compiler automatically treats it as final as soon as it is used inside a lambda expression. In other words, variables from the enclosing context that are used inside a lambda expression are implicitly final (or effectively final ). Naturally, you can add an explicit final declaration, but you do not have to; the compiler will automatically add it for you.
Note, since Java 8, the explicit final declaration is no longer needed for anonymous inner classes as well. Since Java 8, both lambda expressions and anonymous inner classes are treated the same regarding variable binding. Both can access all effectively final variables of their respective enclosing context. lexical scoping meaning of this/super
Scoping
};
...
}
Lambda expression:
void method() {
int cnt = 16;
Runnable r = () -> { int cnt = 0; // error: cnt has already been defined
System.out.println("cnt is: " + cnt );
};
...
}
Both the anonymous class and the lambda define a variable named cnt while there already is a variable with this name defined in the enclosing method. Since the anonymous class establishes a scope of it own it may define a second cnt variable which is tied to the scope of the inner class. The lambda, in contrast, is part of the enclosing scope and the compiler considers the definition of a cnt variable in the lambda body a colliding variable definition. In the scope of the enclosing context there already is a definition of a cnt variable and the lambda must not define an additional cnt variable of its own.
Similarly, the different scoping rules have an impact on the meaning of keywords such as this and super when used inside an anonymous class or a lambda expression. In an anonymous class this denotes the reference to the object of the inner class type and super refers to the anonymous class's super class. In a lambda expression this and super mean whatever they mean in the enclosing context; usually this will refer to the object of the enclosing type and super will refer to the enclosing class's super class. Essentially it means, that it might not always be trivial to replace an anonymous class by a lambda expression. IDEs might help and offer functionality that refactors anonymous classes into lambda expressions. collection framework extension bulk operations
Why do we need lambdas?
Internal vs. External Iteration
We iterate over a list of bank accounts using a for-each loop:
private static void checkBalance(List<Account> accList) {
for (Account a : accList)
if (a.balance() < a.threshold) a.alert();
}
The for-each-loop internally uses an iterator and basically looks like this:
Iterator iter = accList.iterator();
while (iter.hasNext()) {
Account a = iter.next();
if (a.balance() < a.threshold) a.alert();
}
This loop has potential for improvement in several areas:
• The logic of traversing the sequence is intermingled with the functionality that is applied to each element in the sequence. Separating the concerns would allow for optimizations regarding how the elements are accessed.
• The execution is single-threaded. Multi-threaded execution is possible by means of the fork-join thread pool, but it would be substantially more complex.
•
There
is a certain amount of redundancy. The iterator's
hasNext
and
next
method have overlap; they
both figure out whether there is a next element. The overhead could be
eliminated.
The traditional access to elements in a sequence via an iterator is known as external iteration in contrast to internal iteration .
The idea of internal iteration is: the sequence itself determines how elements in a sequence are accessed and the sequence's user is only responsible for specifying what has to be applied to each element in the sequence. While the external iteration intermingles the logic of sequence traversal with the functionality applied to each of the sequence elements, internal iteration separates the concerns. Here is what internal iteration might look like. Since Java 8, a collection has a forEach method that looks like this:
public void forEach(Consumer<? super E> consumer);
It uses the Consumer interface, which looks like this:
public interface Consumer<T> { public void accept(T
t); }
Given this forEach method the sequence's user only has to supply the functionality that is to be applied to each element in the sequence.
private static void checkBalance(List<Account> accList) {
accList. forEach (
(Account a) -> { if (a.balance() < a.threshold)
a.alert();
}
);
}
Now the concerns are separated: the collection is responsible for figuring out how to access all elements and how to apply the specified functionality to them. The user is responsible for supply of a reasonable functionality to be applied to the sequence elements. Given this separation, the implementation of the collection and its forEach method have the liberty to optimize away the overhead of the iterator's hasNext and next method, to split the task into subtasks and execute them in parallel, and several further optimizations such as lazy evaluation, pipeline optimizations for consecutive operations, or out-of-order execution. The traditional intermingled external iteration prevents all of these optimizations.
Given the separation of concerns it is now easy to have the loop executed in parallel by multiple threads. Since Java 8, collections can be turned into so-called streams , of which there is a sequential and a parallel variety. The parallel version of the example above would look like this:
private static void checkBalance(List<Account> accList) {
accList. parallelStream() . forEach (
(Account a) -> { if (a.balance() < a.threshold) a.alert(); }
);
}
In the following section we take a closer look at streams, their relationship to collections, and their support for bulk operations via internal iteration. filter-map-reduce streams
Streams and Bulk Operations
Using method stream() , we create a stream on top of a collection. Different from a collection a stream does not contain any elements. Instead it is a view to a collection that gives access to all elements in the collection by means of bulk operations with internal iteration. A stream has operations such filter() , map() and forEach() , as illustrated in the code snippet above.
The filter() method takes a predicate, which is a function that takes an element from the sequence and returns a boolean value. In our example the predicate is the lambda expression a->a.balance()>1_000_000_00 . This predicate is applied to all elements in the sequence and only the "good" elements, i.e. those for which the predicate returns true , appear in the resulting stream.
The map() method takes a mapper, which is a function that takes an element from the sequence and returns something else. In our example the mapper maps the accounts to their respective balance using the balance() method of class Account . The result is a stream of long values.
The forEach() method takes an arbitrary function, which receives an element from the sequence as an argument and is not supposed to return anything. In our example it prints the element.
Some of these methods ( filter() and map() in the example) return a stream; other ones ( forEach() in our example) do not. The methods that return streams are intermediate (aka lazy ) operations, which means that they are not immediately executed, but delayed until a terminal (aka eager ) operation is applied. In the example above, each bank account in the list is accessed only once, namely when the terminal forEach operation is executed. For each bank account the sequence of operations, i.e., filtering, mapping, and printing, is applied.
So far, the sequence of filter-map-forEach is executed sequentially, but it is easy to enable parallel execution. We simply need to create a parallel stream. Compare the sequential to the parallel version:
Sequential execution:
List<Account> accountCol = … ;
accountCol
. stream ()
.filter( a -> a.balance() > 1_000_000_00 ) // intermediate
.map(Account::balance) // intermediate
.forEach(b -> {System.out.format("%d\t",b);});
//
terminal
Parallel execution:
List<Account> accountCol = … ;
accountCol
. parallelStream ()
.filter( a -> a.balance() > 1_000_000_00 ) // intermediate
.map(Account::balance) // intermediate
.forEach(b -> {System.out.format("%d\t",b);});
//
terminal
We create a parallel stream via the collection's parallelStream() method. This is all we need to say and the rest is taken care of by the implementation of the stream abstraction.
The extended collections framework with its streams and bulk operations as outlined above is just one area of Java and its JDK where lambda expressions are helpful and convenient. Independently of the JDK, lambdas can be useful for our own purposes. Before we explore a couple of "functional patterns" that necessitate lambdas we take a closer look at the lambda language feature, its syntax and its properties.
Programming with Lambdas
Fluent Programming
public interface Employee extends Person {
public long getSalary();
}
public interface Manager extends Employee {
}
public interface Department {
public enum Kind {SALES, DEVELOPMENT, ACCOUNTING,
HUMAN_RESOURCES}
public Department.Kind getKind();
public String getName();
public Manager getManager();
public Set<Employee> getEmployees();
}
public interface Corporation {
public Set<Department> getDepartments();
}
For illustration we want to retrieve all managers of all departments in a corporation that have an employee older than 65.
Imperative Approach
Here is the traditional imperative approach:/*
* find all managers of all departments with an employee older than 65
*/
Manager[] find(Corporation c) {
List<Manager> result = new ArrayList<>();
for (Department d : c.getDepartments()) {
for (Employee e : d.getEmployees()) {
if (e.getAge() > 65) {
result.add(d.getManager());
}
}
}
return result.toArray(new Manager[0]);
}
The implementation is straight forward. We retrieve all departments from the corporation, then retrieve all employees per department, if we find an employee older than 65 we retrieve the department's manager, and add it to a result collection, which we eventually convert in the array that is returned. declarative programming
Declarative Approach
Using streams and lambdas it would look like this:/*
* find all managers of all departments with an employee older than 65
*/
Manager[] find(Corporation c) {
return
c.getDepartments().stream() // 1
.filter(d -> d.getEmployees().stream() // 2
.map(Employee::getAge) // 3
.anyMatch(a -> a>65)) // 4
.map(Department::getManager) // 5
.toArray(Manager[]::new) // 6
}
In line //1 , we retrieve all departments of the corporation via the getDepartments method. The method yields a collection of Department references, which we turn into a stream (of Department references).
In line //2 , we use the filter operation on the stream of departments. The filter operation needs a predicate. A predicate is a function that takes an element from the stream (a Department in our example) and returns a boolean value. The map operation applies the predicate to each element in the stream and suppresses all elements for which the predicate returns false . In other words, the stream returned from the map operation only contains those elements for which the filter has been returning true .
In our example we need a filter predicate that returns true if the department has an employee older than 65. We provide the predicate as a lambda expression. The lambda expression is fairly ambitious; it takes a Department d , retrieves all employees of that department via the getEmployees method, turns the resulting collection of employees into a stream, maps each employee to its age, and eventually applies the anyMatch operation.
In line //3 , we use the map operation on the stream of employees. The map operation needs a function that takes an element from the stream (an Employee in that case) and returns another object of a potentially different type (the age in our example). The mapper function is provided as the method reference Employee::getAge . because the getAge method does exactly what we need: it maps an employee to its age.
In line //4 , we use the anyMatch operation of the stream of age values return from the preceding map operation. The anyMatch operation takes elements from the stream, applies a predicate to each element, and stops as soon as an element is found for which the predicate returns true . We supply the required predicate as another lambda that takes the age and returns true if the age is greater than 65.
The result of the filter operation and the lengthy lambda expression in line //2 to //4 is the stream of all departments with an employee older than 65.
In line //5 , we map each department to its respective manager. As the mapper function we use the method reference Department::getManager . The result is the stream of all managers of all departments with an employee older than 65.
So far, none of the lambdas or referenced methods have been executed because filter and map are intermediate operations.
In line //6 , we convert the manager list into an array via the stream's toArray method. The toArray method needs a generator, which takes a size value and returns an array of the requested size. The generator in our example is a constructor reference, namely the reference to the constructor of manager arrays: Manager[]::new .
The two approaches look very different. The imperative style intermingles the logic of iterating (the various nested loops) and the application of functionality (retrieval of departments and employees, evaluation of age values, collecting results). The declarative style, in contrast, separates concerns. It describes which functionality is supposed to be applied and leaves the details of how the functions are executed to the various operations such as filter , map , anyMatch , and toArray . pipelining
Fluent Programming
.forEach(l
-> System.out.println(l));
In the code snippet we take a string array, turn it into a stream, pick all strings longer than 3 characters, and map them to their length.
The source code suggests that first the filter
is applied to all elements in the stream and then the mapper is applied
to all elements in a second pass over the stream. In reality, the chain
of filter and map operation is postponed until the terminal
forEach
operation is executed. The terminal operation triggers only a single
pass over the sequence during which both the filter and the mapper are
applied to each element.
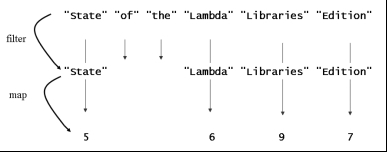
Diagram: Pipelined Execution of filter - map Chain
Creating such a pipeline per element does not only reduce multiple passes over the sequence to a single pass, but also allows further optimizations. For instance, the length method need not be invoked twice per string; the repeated call can be eliminated by the JIT compiler.
Which style looks more pleasant and understandable is to the eye of the beholder. Certainly the declarative code looks alien to Java programmer unfamiliar with the declarative or fluent programming. After getting accustomed to the declarative style it will probably appear equally pleasant and understandable. execute-around-method
Execute-Around-Method Pattern
public void someMethod() {
lock.lock();
try {
... critical region ...
} finally {
lock.unlock();
}
}
}
In all places where we need to acquire and release the lock the same boilerplate code of "lock-try-finally-unlock" appears. Following the Execute-Around-Method pattern we would factor out the boilerplate code into a helper method:
class Utilities {
public static void withLock(Lock lock, CriticalRegion cr) {
lock.lock();
try {
cr.apply();
} finally {
lock.unlock();
}
}
}
The helper method withLock takes the variable code as a method argument of type CriticalRegion :
@FunctionalInterface
public interface CriticalRegion {
void apply();
}
Note that
CriticalRegion
is a functional interface and hence a lambda expression can be used to
provide an implementation of the
CriticalRegion
interface. Here is a piece of code that uses the helper method
withLock:
private class MyIntStack {
private Lock lock = new ReentrantLock();
private int[] array = new int[16];
private int sp = -1;
public void push(int e) {
withLock(lock, () -> {
if (++sp >= array.length)
resize();
array[sp] = e;
});
}
...
}
The boilerplate code is reduced to invocation of the withLock helper method and the critical region is provided as a lambda expression. While the suggested withLock method indeed aids elimination of code duplication it is by no means sufficient.
Let us consider another method of our sample class MyIntStack : the pop method, which returns an element from the stack and throws a NoSuchElementException exception if the stack is empty. While the push method did neither return nor throw anything the pop method has to return a value and throws an exception. Neither is allowed by the CriticalRegion 's apply method: it has a void return type and no throws clause. The exception raised in the critical region of the pop method does not cause any serious trouble; it is unchecked and need not be declared in a throws clause. The lambda that we need for implementing the pop method can throw it anyway. The return type, in contrast, causes trouble. In order to allow for lambda expressions with a return type different from void we need an additional CriticalRegion interface with an apply method that returns a result. This way we end up with two interfaces:
@FunctionalInterface
public interface VoidCriticalRegion {
void apply();
}
@FunctionalInterface
public interface IntCriticalRegion {
int apply();
}
Inevitably, we also need additional helper methods.
class Utilities {
public static void withLock(Lock lock,VoidCriticalRegion cr) {
lock.lock();
try {
cr.apply();
} finally {
lock.unlock();
}
}
public static int withLock(Lock lock, IntCriticalRegion cr) {
lock.lock();
try {
return cr.apply();
} finally {
lock.unlock();
}
}
}
Given the additional helper method and functional interface the pop method can be implemented like this:
private class MyIntStack {
...
public int pop() {
return withLock(lock, () -> {
if (sp < 0)
throw new NoSuchElementException();
else
return array[sp--];
});
}
}
In analogy to the return type you might wonder whether we need additional functional interfaces for critical regions with different argument lists. It turns out that arguments to the critical region are usually not an issue. The lambda expression, which implements the critical region interface, can access (implicitly) final variable of the enclosing context. Consider the push method again; it takes an argument.
private class MyIntStack {
private Lock lock = new ReentrantLock();
private int[] array = new int[16];
private int sp = -1;
public void push( final int e ) {
withLock(lock, () -> {
if (++sp >= array.length)
resize();
array[sp] = e ;
});
}
...
}
The critical region lambda accesses the push method's argument, which is either explicitly declared final or implicitly treated as such. As long as the critical region only reads the argument and does not modify it there is no need for additional helper methods or functional interfaces.
Wrap-Up
Programming with lambda expressions has two aspects:• Using lambdas to define ad-hoc functionality that is passed to existing operations, such as calling the streams' forEach , filter , map , and reduce operations.
•
Designing
functional APIs
that take lambda expressions as arguments. At the heart
of designing such APIs is the execute-around pattern. Even the streams'
forEach
,
filter
,
map
,
and
reduce
operations
are example of execute-around: they are loops that execute around the lambda
that we pass in.
CONTENT