| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
Programmieren mit C++ Templates
ObjektSPEKTRUM, März 2003
Klaus Kreft & Angelika Langer
![]()
Abstract
Templates gibt es in C++ bereits seit mehr als 10 Jahren, benutzt werden sie in der Praxis jedoch eher selten. In diesem Artikel wird besprochen, warum das so ist, warum es sich in der Zukunft rasch ändern könnte und wofür Templates in der Praxis nützlich sind.Templates Gestern und Heute
Beim Stichwort „Templates“ denken die meisten C++-Programmierer
an parametrisierte Container-Klassen wie zum Beispiel ein Klassen-Template
für eine Liste, aus dem Klassen für verschiedene Elementtypen
wie list<int>, list<string>, usw. generiert werden können.
In der Tat sind Templates in die Sprache eingeführt worden, um solche
Container-Klassen effizient implementieren zu können. Die C++
Standard-Bibliothek ist eine typische Anwendung dieses Sprachmittels. Sie
ist eine Template-Bibliothek, die bisweilen auch verkürzt als STL
= Standard Template Library bezeichnet wird. Die Verwendung der Templates
aus der Standard-Bibliothek ist vielen C++-Programmierer durchaus
geläufig. Wenige C++-Programmierer verwenden das Template-Sprachmittel
jedoch für die Implementierung eigener Klassen und Funktionen.
Und das ist schade, weil ein großer Fundus an nützlichen Techniken
einfach brach liegt und gar nicht genutzt wird. Diese Zurückhaltung
hat allerdings ihre Gründe.
Code Bloat
Zu den Gründen gehört sicherlich die Tatsache, daß frühe Implementierungen des Template-Sprachmittels den Templates einen schlechten Ruf eingebracht haben. Hartnäckig hält sich das Gerücht, daß die Benutzung von Templates zwangsläufig zu größerem Binärcode (Code-Bloat) führt. Das war in frühen Compiler-Implementierungen auch in der Tat häufig der Fall, weil die Compiler bei der Template-Instanziierung Code erzeugt haben, der gar nicht gebraucht wurde. Moderne Compiler tun das nicht mehr und dürfen es auch gar nicht, wenn sie standardkonform sein wollen. Der Sprachstandard schreibt nämlich vor, dass ein Compiler bei der Generierung einer Klasse aus einem Klassentemplate nur diejenigen Memberfunktionen erzeugen darf, die auch tatsächlich aufgerufen werden. Alle nicht verwendeten Memberfunktionen dürfen im Binärcode gar nicht auftauchen. Damit wird genau der Code generiert, der auch tatsächlich gebraucht wird – nicht mehr und nicht weniger. Das war früher (vor der Standardisierung von C++) anders. Da wurde von den Compilern mitunter hemmungslos Code für Funktionen generiert, die nirgendwo aufgerufen wurden. Das hat natürlich zu Binärcodegrößen geführt, die nicht nötig gewesen wären.
Zur Ehrenrettung der Compilerhersteller muß man sagen, daß
nicht jeder Code-Bloat auf das Konto des Compilers geht. Man kann
auch durch ungeschicktes Programmier selber zum Aufblähen des erzeugten
Binärcode beitragen, zum Beispiel indem man Funktionalität und
Daten, die nicht vom Template-Parameter abhängen, trotzdem im Template
definiert. Solcher Code und solche Daten werden dann natürlich
vom Compiler bei jeder Instanziierung dupliziert. Solche Fehler kann man
aber vermeiden, so daß bei geschickter Programmierung mit einem modernen
Compiler der berüchtigte Code-Bloat der Vergangenheit angehören
dürfte.
Portabilität
Es gibt aber noch ein weiteres Problem, daß zur eher spärlichen Verwendung von Templates in der Praxis geführt hat. Im Zuge der Standardisierung von C++ (1989-1998) wurden der Sprache zahlreiche neue Template-Sprachmittel hinzugefügt. Dazu gehören Feature wie Member-Templates, Template-Spezialisierung, Template-Template-Argumente und einige andere. Diese Sprachmittel werden zum Teil für die Implementierung und Benutzung der Standard-Bibliothek gebraucht. Die Compilerhersteller haben diese neuen Sprachmittel peu à peu in die Compiler eingebaut, was dazu geführt hat, daß für eine ganze Weile (ca. Mitte bis Ende der 90er Jahre) jeder Compiler Templates in unterschiedlichem Umfang unterstützt hat. Für Programmierer, die zu jener Zeit portable C++-Programme schreiben wollten, war das ein Albtraum. Templates hat man daher in Programmen mit Portabilitätsanforderung tunlichst vermieden.Leider hat sich an dieser traurigen Situation bis heute wenig geändert. Zwar unterstützen heute zahlreiche Compiler-Hersteller fast den gesamten Sprachumfang der C++-Templates, aber ausgerechnet einer der populärste C++-Compiler, Microsoft’s Visual C++ 6.0, unterstützt Templates nur rudimentär. Vollkommen korrekte C++-Programme führen zu Compiler-Abstürzen mit der Fehlermeldung INTERNAL COMPILER ERROR und es kommt auch vor, dass MVC 6.0 gar nichts meldet und einfach inkorrekten Binärcode generiert. Mit anderen Worten, von Templates läßt man besser die Finger, wenn man sein Programm mit MVC 6.0 übersetzen will. Die Version 7.0 ist dem Vernehmen nach kaum besser, aber wir haben das selbst nicht verifiziert.
Das Compiler-Defizit im Bereich der Template-Sprachmittel wird in Kürze
der Vergangenheit angehören. Im November 2002 hat Microsoft
den C++-Compiler Visual Studio C++ .NET 2003 angekündigt (siehe /
MVC
/),
der nun endlich einen großen Teil der Template-Sprachmittel unterstützen
wird. Damit entfällt auch diese Hürden für die Benutzung
von Templates in der industriellen C++-Programmierung.
Knowhow und Praxis
Ein letztes Problem bleibt allerdings. Das Programmieren mit Templates muß erst einmal erlernt werden. Zwar sind praktisch alle C++-Programmierer in der Lage, Templates zu instanziieiren, also z.B. eine list<int> zu benutzen. Aber vor dem Implementieren eigener Templates schrecken viele C++-Programmierer oft zurück. Wenn man nachfragt, warum das so ist, hört man Antworten wie „kann ich nicht“, „brauch’ ich nicht“, „habe ich noch nie benutzt“.Gegen „kann ich nicht“ kann man natürlich was tun. In einer entsprechenden Schulung sind die Grundlagen der Template-Programmierung in 2-3 Tagen erlernt und für das Selbststudium steht ebenfalls ein Fachbuch zur Verfügung (siehe / VAN /), dessen Erscheinen für das Frühjahr 2003 angekündigt ist. Das Buch ist sehr ambitioniert und wendet sich nicht nur an den Template-Anfänger, sondern bespricht nahezu alles, was es derzeit über Templates zu sagen und zu wissen gibt. Für den Neuling wird es wohl eher schwer verdaulich sein, aber es hat ein brauchbares Tutorial, das auch dem Anfänger Hilfestellungen bietet. Aus diesem Grunde wird das Buch am Ende dieses Artikel näher vorgestellt.
Das „brauch ich nicht“-Argument wirkt auf den ersten Blick überzeugend.
Viele Programmierer sagen: „Templates brauche ich nicht, weil ich keine
Container-Klassen implementieren will.“ Und moderne Template-Programmiertechniken
wie generisches Programmieren oder Template-Meta-Programmierung erscheinen
einigen C++-Praktikern reichlich akademisch und unbrauchbar für die
industrielle C++-Programmierung. Das ist auch so oder kann zumindest
so gesehen werden. Was viele C++-Programmierer jedoch unterschätzen,
ist die Nützlichkeit der Templates in ganz alltäglichen Situationen
zur Lösung völlig normaler Programmieraufgaben. Beispiele
solcher Anwendungen von Templates in der alltäglichen Praxis wollen
wir uns im Folgenden ansehen.
Template-Programmierung in der Praxis
Beide Beispiel sind realen Programmierproblemen nachempfunden, aber
für die Besprechung im Rahmen dieses Artikels stark verkürzt
und vereinfacht, damit man die eigentliche Idee der jeweiligen Implementierungstechnik
mit Templates auch sehen kann.
Read / Write Iterator
Betrachten wir das Beispiel einer Klasse, die eine Sequenz
von Elementen eines Typs Data repräsentiert und Zugriff auf die Elemente
der Sequenz über einen Iterator gibt:
class Sequence
{
public:
class Iterator
{
public:
Iterator (Data* base, size_t size)
: pIter(base), lenIter(size), current(0)
{}
Data* next()
{ if (current < lenIter)
return pIter+(current++);
else
return 0;
}
private:
Data* pIter;
size_t lenIter;
size_t current;
};
Sequence() : p(new Data[SIZ]), len(SIZ) {}
Sequence(unsigned int i) : p(new Data[i]), len(i) {}
virtual ~Sequence() { delete [] p; }
Iterator makeIterator() const
{ return Iterator(p,len); }
// some other member functions,
// assignment, copy constructor, operator[], ...
private:
enum { SIZ = 5 };
Data* p;
size_t len;
};
Bei näherer Analyse der Klasse stellt man fest, daß die Klasse nicht ganz in Ordnung ist. Selbst wenn eine Sequenz als unveränderlich deklariert ist, wie zum Beispiel im Kontext einer Funktion (siehe someFunction() unten), der sie als const Sequence& übergeben wird, kann die Sequenz verändert werden. Das ist eine grobe Verletzung der const-Garantien.
void someFunction(const Sequence& seq)
{
Sequence::Iterator iter = seq.makeIterator();
Data* elemPtr = iter.next();
*elemPtr = Data(?new value?); //
ß das sollte eigentlich nicht möglich sein !!!
}
Das Problem liegt darin, daß die Funktion makeIterator() als const deklariert ist und damit auf unveränderliche Sequenzen angewandt werden kann, aber dann einen Iterator zurück gibt, der den schreibenden Zugriff auf die Elemente in der Sequenz zuläßt, weil er eine non-const Referenz auf die Elemente der Sequenz liefert. Dieses Loch in der Const-Correctness kann man stopfen, indem man zwei Varianten der makeIterator()-Funktion implementiert, eine für veränderliche und eine für unveränderliche Sequenzen. Die makeIterator()-Funktion für unveränderliche Sequenzen müßte einen Lese-Iterator liefern und die makeIterator()-Funktion für veränderliche Sequenzen dürfte einen Schreib-Iterator liefern. Man braucht also zwei Iterator-Typen, einen Lese- und einen Schreib-Iterator. Das würde dann etwa so aussehen:
class Sequence {
public:
...
WriteIterator makeIterator()
{ return writeIter(p,len); }
ReadIterator makeIterator() const
{ return readIter(p,len); }
...
};
Wie implementiert man die beiden benötigten Iterator-Typen am geschicktesten? Den Schreib-Iterator hatten wir ja schon; wir müssen den Typ Iterator nur umbenennen in WriteIterator:
class Sequence::WriteIterator
{
public:
Iterator (Data* base, size_t size)
: pIter(base), lenIter(size), current(0)
{}
Data* next()
{ if (current < lenIter)
return pIter+(current++);
else
return 0;
}
private:
Data* pIter;
size_t lenIter;
size_t current;
};
Der Lese-Iterator sieht ganz ähnlich aus. Er unterscheidet sich lediglich im Rückgabetyp der Funktion next() und im Typ des privaten Pointer-Datenmembers:
class Sequence::ReadIterator
{
public:
Iterator (const Data* base, size_t size)
: pIter(base), lenIter(size), current(0)
{}
const Data* next()
{ if (current < lenIter)
return pIter+(current++);
else
return 0;
}
private:
const Data* pIter;
size_t lenIter;
size_t current;
};
Hier haben wir die Implementierung gezeigt, die wohl die meisten Programmierer intuitiv gewählt hätten. Man kopiert einfach den Source-Code des Schreib-Iterators mit Copy-Paste, macht die beiden winzigen Änderungen und – voilà – man hat einen Lese-Iterator implementiert. Das machen manche Programmierer auch noch, wenn der zu kopierende Code etwas umfangreicher ist, wie das wohl bei einer realistischen Iterator-Klasse der Fall wäre; typischerweise hat ein Iterator nicht nur eine einzige Memberfunktion, sondern eher ein halbes bis ein ganzes Dutzend. Dann werden nicht nur 10 Zeilen Code, sondern gleich 100 Zeilen Code kopiert.
Code-Duplizierung ist zwar einfach, hat aber gravierende Nachteile. Man erzeugt Redundanzen, die sich später bei der Weiterentwicklung und Wartung des Quellcodes nachteilig auswirken, weil man immer alle Kopien synchron ändern muß, zum Beispiel wenn den Iterator-Typen eine neue Funktion hinzugefügt werden soll oder wenn eine bestehende Funktion geändert werden muß. Aus Gründen der Wartbarkeit seines Codes wird man Redundanzen grundsätzlich vermeiden, wenn man kann. Und hier könnte man die Redundanz beispielsweise mit Templates vermeiden.
Der Unterschied zwischen den beiden Iterator-Typen besteht lediglich im Namen der Interator-Typen, im Return-Typ der Memberfunktion next(), und im Typ eines Datenmembers. Ansonsten sind die beiden Iterator-Typen absolut identisch. Unterschiede, die sich nur auf Typinformation beziehen, kann man über Template-Argumente ausdrücken. Man könnte ein einziges Klassen-Template definieren, aus dem die beiden benötigten Iterator-Typen generiert werden können. Das sieht dann wie folgt aus:
class Sequence {
public:
template <class ElemT> class Iterator {
public:
Iterator (ElemT* base, size_t size)
{ … }
ElemT* next()
{ … }
private:
ElemT* pIter;
...
};
typedef Iterator<Data>
WriteIterator;
typedef Iterator<const Data> ReadIterator;
…
WriteIterator makeIterator()
{ return writeIter(p,len); }
ReadIterator makeIterator() const
{ return readIter(p,len); }
};
Es gibt natürlich auch andere Techniken, um die Redundanz zu vermeiden. Beispielsweise könnte man versuchen, die Gemeinsamkeiten der beiden Iterator-Typen durch eine gemeinsame Basisklasse auszudrücken. Dann implementiert man statt einem Klassen-Template ein ganze Klassen-Hierarchie mit 3 Klassen. Vererbung ist in der Tat eine sinnvolle Möglichkeit zur Redundanzvermeidung. Allerdings stellt man fest, daß man in unserem Beispiel nur die Datenmember in die Basisklasse legen kann. Die Memberfunktion next() kann nicht in die Basisklasse gezogen werden, weil sie in beiden abgeleiteten Klassen eine ähnliche, aber dennoch leicht andere Signatur haben müßte. In einer realistischen Implementierung einer Iterator-Klasse würde das vermutlich für eine ganze Reihe von Memberfunktionen gelten.
Anstelle der Vererbungslösung kann man auch eine Wrapper-Lösung versuchen, bei der man den Lese-Iterator so implementiert, daß er einen Schreib-Iterator enthält, alle Funktionen durch Delegierung an den enthaltenen Schreib-Iterator implementiert und lediglich bei der next()-Funktion einen anderen Return-Typ, nämlich einen Pointer auf const ElemT liefert. Man hat dann aber immer noch die Arbeit, daß man das gesamte Iterator-Interface zweimal hinschreiben und, wenn auch in trivialer Form, implementieren muß.
Unter Verwendung von Templates bekommt man verglichen mit der Vererbungs-
und der Wrapper-Lösung eine kompakte, redundanz-freie, optimale Lösung.
Das berüchtigte Code-Bloat-Problem besteht hier nicht, weil bei der
Template-Instanziierung nichts entsteht, was nicht auch beim Copy-Paste
entstanden wäre. Im Gegenteil! Der Compiler darf bei der
Instanziierung von Iterator<Data> und Iterator<const Data> nur die
Memberfunktionen erzeugen, die auch tatsächlich aufgerufen werden.
Wenn es Memberfunktionen im Iterator-Template gäbe, die nirgendwo
verwendet werden, dann würde die Template-Lösung sogar zu einer
Reduzierung der Binärcode-Größe im Vergleich zu allen anderen
Lösungen führen.
Fazit
Wie man am Beispiel sieht, sind Templates auch in ganz normalen Lebenslagen nützlich, d.h. in Situation, die mit Template-Programmierung im klassischen Sinne nichts zu tun haben. Hier wird nicht versucht, ein Container-Template zu implementieren. Die Templates wurden einfach nur verwendet, um Code-Duplizierung zu vermeiden, Redundanzen zu eliminieren und den eigenen Code übersichtlicher und leichter wartbar zu gestalten.
Wer sich mit Templates etwas besser auskennt, wird feststellen, daß
sich Templates relativ gut zur Redundanzvermeidung einsetzen lassen. Es
ist nicht immer so trivial wie im besprochenen Beispiel und man muß
u.U. mehr Template-Sprachmittel einsetzen als hier gezeigt, aber es geht
und ist nützlich und in gewissen Fällen sind Templates anderen
Techniken wie beispielsweise der Vererbung sogar überlegen.
I/O-Operatoren für beliebige Objekte
Sehen wir uns ein anderes Beispiel von Template-Programmierung in
der Praxis an. Stellen wir uns vor, wir implementieren Software für
einen Paketdienst. In der Applikation gibt es eine Abstraktion ShippingInfo,
die Informationen über Gewicht und Maße des Pakets und die Entfernung
zum Zielort enthält, damit daraus die Zustellgebühren berechnet
werden können. Für solche selbst-definierten Typen implementiert
man häufig die I/O Operatoren, damit z.B. der Inhalt eines ShippingInfo-Objekts
protokolliert werden kann, indem man das Objekt auf eine Datei ausgibt.
Hier sieht man einen Teil der ShippingInfo-Klasse und den Ausgabe-Operator:
#ifndef ShippingInfo_H
#define ShippingInfo_H
class ShippingInfo {
private:
float _wght; // weight in pounds
float _siz[3]; // size in inches
float _dist; // distance to destination in miles
public:
ShippingInfo( float w, float s1, float s2, float s3, float
d)
: _wght(w), _dist(d)
{_siz[0] = s1; _siz[1] = s2; _siz[2] = s3;}
…
friend std::ostream& operator<< (std::ostream& os,
const ShippingInfo& si);
};
std::ostream& operator<< (std::ostream& os, const
ShippingInfo& si)
{
os << ”weight: ” << si._wght << ‘ ‘;
os << ”size: ” << si._siz[0] << ‘x’ <<
si._siz[1] << ‘x’ << si._siz[2] << ‘ ‘;
os << ”distance: ” << si._dist ;
return os;
}
#endif /* ShippingInfo_H */
Den Ausgabe-Operator kann man dann wie folgt benutzen:
#include <iostream>
#include ”ShippingInfo.h”
void main()
{
ShippingInfo item(2,3,5,7,600);
std::cout << ”Info: ” << item << ‘\n’;
}
Das Programm schreibt auf den Bildschirm:
Info: weight: 2 size: 3x5x7 distance: 600
Im Laufe der Weiterentwicklung der Anwendung ergibt es sich, daß zwischen metrischen und amerikanischen Maßeinheiten konvertiert werden muß. Weil diese Konvertierung typischerweise im Zusammenhang mit der Ein- und Ausgabe von Daten und nicht nur im Zusammenhang mit der ShippingInfo-Abstraktion gebraucht wird, soll die Konvertierung in der Stream-Abstraktion implementiert werden. Zu diesem Zweck wird eine neue Stream-Klasse implementiert:
#ifndef MetricConvStream_H
#define MetricConvStream_H
#include <sstream>
class MCostringstream : public std::ostringstream {
private:
bool _metric;
float MilesToKm(float m) const { return m * 1.609;
}
float InchesToCm(float m) const { return m * 2.54; }
float PoundsToKg(float w) const { return w * .45359; }
public:
MCostringstream() :_metric(false) {}
void set_metric(bool m) { _metric = m; }
…
};
#endif /* MetricConvStream_H */
Diese neue Stream-Klasse MCostringstream ist von der in der Standard-Bibliothek existierenden Klasse std::ostringstream abgeleitet, die ihrerseits von der Klasse std::ostream abgeleitet ist. Die Hierarchie der Stream-Klassen wird noch eine Rolle spielen. Sie sieht so aus:
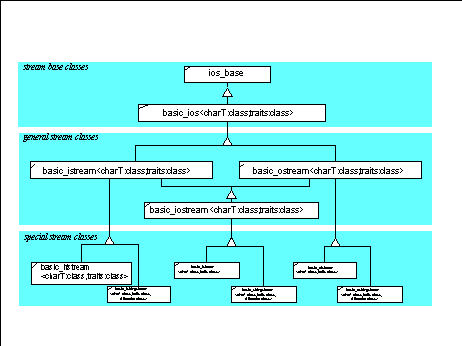
Da die neue Konvertierungsmöglichkeit selbstverständlich auch für die Ausgabe von ShippingInfo-Objekten genutzt werden soll, wird eine weiterer Ausgabe-Operator definiert, der ShippingInfo-Objekte auf MCostringstreams ausgeben kann:
MCostringstream& operator<<(MCostringstream& os,const
ShippingInfo& si)
{
float w = (os._metric) ? os.PoundsToKg(si._wght) : si._wght;
float d = (os._metric) ? os.MilesToKm(si._dist) : si._dist;
float s[3];
for (int i=0;i<3;i++)
s[i] = (os._metric) ? os.InchesToCm(si._siz[i])
: si._siz[i];
os << ”weight: ” << w << ‘ ‘;
os << ”size: ” << s[0] << ‘x’ <<
s[1] << ‘x’ << s[2] << ‘ ‘;
os << ”distance: ” << d;
return os;
}
Für die ShippingInfo-Objekte gibt es jetzt also zwei Ausgabe-Operatoren:
std::ostream& operator<< (std::ostream& os, const
ShippingInfo& si);
MCostringstream& operator<<(MCostringstream& os,
const ShippingInfo& si);
Schauen wir uns an, was passiert, wenn man nun die ShippingInfo-Objekte auf einen MCostringstreams ausgibt wie in folgendem Beispiel:
#include <iostream>
#include ?ShippingInfo.h?
#include ?MetricConvStream.h?
void main()
{
ShippingInfo item(2,3,5,7,600);
MCostringstream os;
os << ?US:\t? << item << ‘\n’;
os.set_metric(true);
os << ?metric:\t? << item << ‘\n’;
std::cout << os.str();
}
Man würde erwarten, daß die Ausgabe erst in US-Einheiten erfolgt und nach dem Einschalten des metric-Flags in metrischen Einheiten. Das ist aber nicht der Fall. Das Flag hat überhaupt keine Wirkung und es wird in beiden Fällen eine Ausgabe in US-Einheiten gemacht. Wieso?
Um das zu verstehen, muß man sich eine Sequenz von Ausgabe-Operationen wie os << ?US:\t? << item << ‘\n’; genauer ansehen. Für die erste Ausgabe os << ?US:\t? sucht der Compiler einen operator<<, der einen Mcostringstream und einen C-String vom Typ const char* verarbeiten kann. Es gibt keinen solchen Operator. Also sucht der Compiler nach einem ähnlichen Ausgabe-Operator und findet einen Kandidaten in der Standard-Bibliothek. Es gibt dort Ausgabe-Operatoren für alle in der Sprache definierten Typen und auch einen für C-Strings vom Typ const char*. Diese Ausgabe-Operatoren sind für die Klasse std::ostream definiert:
std::ostream& operator<<(std::ostream&, int)
std::ostream& operator<<(std::ostream&, const string&)
std::ostream& operator<<(std::ostream&, const char*)
...
Nun paßt der Ausgabe-Operator std::ostream& operator<< (std::ostream&, const char*) nicht hundertprozentig, aber der Compiler weiß, daß er einen MCostringstream in einen std::ostream konvertieren kann, weil MCostringstream von std::ostream abgeleitet ist. Der Compiler ruft also diesen Ausgabe-Operator. Das Ergebnis dieses Aufrufs ist vom Typ std::ostream und mit diesem Ergebnis geht der Compiler auf die Suche nach dem passenden Ausgabe-Operator für die Ausgabe des ShippingInfo-Objekts item.
Für die Ausgabe von ShippingInfo-Objekten stehen zwei Operatoren zur Verfügung, einer für Streams vom Typ MCostringstream und einer für Streams vom Typ std::ostream. Da das Ergebnis des vorangegangenen Aufrufs vom Typ std::ostream war, entscheidet der Compiler, daß er den Operator für Standard-Streams vom Typ std::ostream verwenden muß, weil er auf die Argumente, d.h. rechter und linker Operand, vom Typ her genau paßt. Das ist aber genau der Ausgabe-Operator, der nie eine metrische Konvertierung macht und ist nicht der Operator, den wir aufrufen wollten. Schließlich ist der Stream os ein MCostringstream und dann sollte der Compiler eigentlich auch den Ausgabe-Operator für MCostringstream nehmen. Das tut er aber nicht, weil durch den vorangegangenen Aufruf des Operators für C-Strings die Information verloren gegangen ist, daß der Stream os tatsächlich ein MCostringstream war.
Was kann man nun tun, damit der Compiler den „richtigen“ Ausgabe-Operator aufruft? Nun, wenn es einen Ausgabe-Operator gäbe, der C-Strings auf MCostringstream schreiben kann, dann bräuchte der Compiler nicht auf den Operator aus der Standard-Bibliothek zurückgreifen. Ein solcher Operator mit der Signatur MCostringstream& operator<< (MCostringstream&, const char*) würde natürlich auch einen MCostringstream zurückliefern und dann würde der Compiler im nächsten Schritt den „richtigen“ Ausgabe-Operator aufrufen. Problem gelöst! Der zusätzliche Operator sähe dann wie folgt aus:
MCostringstream& operator<<(MCostringstream& os, const
char* obj)
{
static_cast<std::ostream&>(os) << obj;
return os;
}
Das ist natürlich nur eine partielle Lösung des Problems. Wenn die Sequenz der Ausgabe-Operationen vor dem ShippingInfo einen Integer ausgeben will, dann wird wiederum auf die Standard-Bibliothek zurück gegriffen, weil es nur dort einen Ausgabe-Operator für integrale Werte gibt und wir haben das gerade gelöste Problem schon wieder. Also müßten wir noch einen zusätzlichen Ausgabe-Operator schreiben, der weiß, wie man Integers auf MCostringstream schreibt. Und so weiter und so fort. Eigentlich müssen wir Ausgabe-Operatoren für alle erdenklichen Typen schreiben, die man auf Streams ausgeben kann.
Eine solche Aufgabe kann man natürlich mit Copy-Paste erledigen. Aber wenn morgen ein neuer Typ entsteht, den man auf Standard-Streams ausgeben kann, dann muß auch ein neuer Ausgabe-Operator für diesen neuen Typ und unseren MCostringstream entstehen. Das läuft auf ein ziemliches Wartungsproblem hinaus, daß sich aber glücklicherweise mit Templates vermeiden läßt. Wenn aus dem oben gezeigten Ausgabe-Operator ein Template macht, dann kann der Compiler alle nötigen Ausgabe-Operatoren automatisch generieren. Das Template sähe so aus:
template <class T>
MCostringstream& operator<<(MCostringstream& os,
const T& obj)
{
static_cast<std::ostream&>(os) << obj;
return os;
}
Das ist eine elegante Lösung, die mitwächst, ohne daß ein Wartungsaufwand entsteht. Der Compiler generiert von selbst neue Funktionen, wenn welche gebraucht werden. Das müssen wir nicht manuell per Copy-Paste machen. Overhead in Form von Code-Bloat entsteht hier nicht unbedingt. Alle generierten Funktionen sind einfache Delegationen an bereits existierende Ausgabe-Operatoren. Ein gut optimierender Compiler wird die generierten Funktionen alle „inlinen“, d.h. die Aufrufe der generierten Funktionen durch die existierenden Funktionen, an die deligiert wird, ersetzen. Bei guter Optimierung tauchen die generierten Ausgabe-Operatoren im Binärcode überhaupt nicht auf.
Es soll nicht verschwiegen werden, daß es auch eine Lösung ohne Templates gibt, bei der man auf dynamische Typinformation zurückgreift. Dabei würde man gar keine Ausgabe-Operatoren für MCostringstream implementieren, sondern den einen Ausgabe-Operator für Standard-Streams std::ostream& operator<< (std::ostream& os, const ShippingInfo& si) so ändern, daß er abfragt, ob der Stream ein MCostringstream ist. Wenn ja, dann kann der Ausgabe-Operator die Konvertierungsfunktionalität des Streams nutzen. Wenn nein, dann wird halt Ausgabe ohne Konvertierung gemacht. Das sähe dann im Prinzip so aus:
std::ostream& operator<< (std::ostream& os,const ShippingInfo&
si)
{ MCostringstream* p = dynamic_cast<MCostringstream*>(&os);
if (p)
{ /* do metric conversion */ }
else
{ /* no conversion */ }
// output to os
return os;
}
Wenn man die beiden Lösungen vergleicht, stellt man fest, daß von der Code-Größe her kein Unterschied besteht. Die Funktionalität, die in der Template-Lösung in den zwei Ausgabe-Operatoren für ShippingInfo-Objekte implementiert ist, taucht hier in den beiden Zweigen der if-Anweisung auf. Und die per Template generierten Operatoren werden bei guter Optimierung, wie bereits erläutert, vollständig wegoptimiert.
Von der Performance her ist die Template-Lösung sogar besser, weil in der Lösung ohne Templates die dynamische Typinformation des Streams abgefragt werden muß. Diese Entscheidung fällt in der Template-Lösung bereits zur Compilezeit anhand der statischen Typinformation des Streams und belastet daher das Laufzeitverhalten nicht.
Die Übersetzungszeiten der Template-Lösungen werden länger
sein, weil das Instanziieren von Templates und das anschließende
Inlinen und Wegoptimieren der generierten Funktionen natürlich Zeit
kostet.
Fazit
Auch in diesem Fall haben wir Templates für die Lösung
eines ganz alltäglichen Problems verwendet. Statt mit Copy-Paste
zahlreiche Funktionen zu erzeugen, haben wir sie uns vom Compiler per Template-Instanziierung
generieren lassen.
Das Beispiel mit den Stream-Klassen ist nicht ausgedacht, sondern ist ein real existierendes Problem, das den meisten Programmierern aber vermutlich eher selten unterkommen wird. Es ist ein Beispiel für eine ganze Kategorie von Situationen, in denen man sich über Templates Funktionen generieren lassen kann. Wenn man zum Beispiel Adaptoren für existierende Funktionen schreiben will und diese Adaptoren ähneln sich, dann kann man sie sich auch generieren lassen. Zum Beispiel könnte es ein, daß man sicher stellen will, daß in einem bestimmten Kontext keine Funktion irgendwelche Exceptions wirft, oder man will alle Exceptions abfangen und nicht nur unterdrücken, sondern irgendwie besonders behandeln, z.B. in ein Logbuch schreiben. Dann kann man sich einen Exception-Adaptor bauen, der die betreffende Funktion in einem try-Block aufruft, die Exceptions abfängt und unterdrückt oder behandelt. Einen solchen Adaptor braucht man für jede erdenkliche Funktion, die man adaptieren will. Solche Adaptoren muß man nicht von Hand schreiben, sondern man kann sie sich per Template generieren lassen.
#include <iostream>
#include <stdexcept>
#include <typeinfo>
typedef void (*Function)(void);
typedef void (*ExcHandler)(void);
template <Function Fct, ExcHandler Exc>
void adapted()
{
try { Fct(); }
catch (...)
{ Exc(); }
}
extern void foo();
void suppress() {}
void report()
{
try { throw; }
catch (std::logic_error& e)
{ std::clog << typeid(e).name()
<< ": " << e.what() << std::endl; }
catch (...)
{ std::terminate(); }
}
int main(void)
{
foo();
adapted<foo,suppress>();
adapted<foo,report>();
return 0;
}
Hier im Beispiel haben wir den Adapter nur für Funktionen ohne Argumente und Rückgabewerte gezeigt. Wenn man es verallgemeinern will, wird es deutlich komplizierter, aber es ist machbar.
Wie man sieht, ist die Verwendung von Templates keineswegs auf die Implementierung
von Container-Bibliotheken beschränkt, sondern hilft auch in der ganz
normalen Alltagsprogrammierung.
Referenzen
| /VAN/ |
C++ Templates: The Complete Guide
David Vandevoorde und Nicolai M. Josuttis Addison Wesley, 2003 ISBN: 0-201-73484-2 http://www.aw.com/catalog/academic/product/1,4096,0201734842,00.html |
| /KRE/ |
Buchbesprechung von „C++ Templates – The Complete Guide“
von Klaus Kreft & Angelika Langer erschienen im OBJEKTspektrum im März 2003 http://www.AngelikaLanger.com/Articles/Reviews/Templates/Templates.html |
| /MVC/ |
Microsoft’s Ankündigung für den neuen C++-Compiler Visual
C++ .NET 2003:
http://msdn.microsoft.com/visualc/productinfo/visualc03/features/default.asp |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||
Seminar
|
||