| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
Fehlerfreies Programmieren in C++
Dynamische Allokation von Ressourcen
Elektronik, März 1998
Angelika Langer
![]()
-
C++ ist eine mächtige und komplexe Programmiersprache
mit vielen unbestrittenen Vorteilen, aber dem unvermeidlichen Nachteil
einer steilen Lernkurve. Eigenarten der Sprache, die dem langjährigen
C++-Experten als selbstverständlich erscheinen, stellen für den
weniger geübten C++-Programmierer bisweilen Stolpersteine dar. In
diesem Artikel werden einige typische Anwendungsfehler erläutert,
mit dem Ziel ein Bewußtsein für die Fehlerquellen zu wecken
und Vorschläge für deren Vermeidung zu machen.
Für diese Vielseitigkeit zahlt man einen Preis, nämlich den einer steilen Lernkurve. Der übliche und empfehlenswerte Weg einer Annäherung an C++ beginnt mit der Verwendung von C++ als besseres C. Danach wendet man sich den modularen Konzepte zu, um sich dann allmählich der Objekt-Orientierung zu nähern. Generische Programmierung und die Verwendung von Templates und Exceptions stecken noch heute in den Kinderschuhen. Vom ersten Annäherungsversuch bis zur perfekten Beherrschung der Sprache in allen ihren Facetten vergehen im allgemeinen 2-3 Jahre. Derart gewaltige Lernphasen sind im allgemeinen nur projektbegleitend möglich. Daher finden sich viele Programmierer in einer Situation wieder, in der sie C++ anwenden wollen und/oder müssen, aber bei weitem nicht alle Eigenheiten der Sprache kennen und lieben gelernt haben.
Stolpersteine in C++ - am Beispiel der Konstruktion von Objekten
In diesem Artikel will ich der Situation zahlreicher Entwickler von Embedded Systemen Rechnung tragen, die fundierte Kenntnisse in Assembler und C mitbringen, aber im Umgang mit C++ nicht über jahrelange Erfahrung verfügen. Ich will versuchen, einige wenige typische Stolpersteine im Umgang mit der Sprache C++ darzustellen, den Leser für die fehleranfällige zu sensibilisieren und Vorschläge zu deren Vermeidung zu unterbreiten. Als Beispiel habe ich die Konstruktion von Objekten herausgegriffen, aus folgenden Gründen: Erstens ist die Konstruktion an sich ein wichtiges Thema in C++ und wird tagtäglich, bewußt oder unbewußt, von jedem C++-Programmierer verwendet. Zweitens sind Klassen und Objekte, als Verallgemeinerung von Datenstrukturen, insbesondere auch im Embedded Programming von Bedeutung, anders als zum Beispiel Mehrfachvererbung oder Polymorphismen. Als Einstieg in das Beispiel wollen wir zunächst einmal rekapitulieren, was jeder irgendwann einmal in einem C++-Kurs über Klassen gelernt hat.
Das Sprachmittel der Klasse in C++
C++ unterstützt die Definition neuer Typen durch den Benutzer. Diese benutzerdefinierten Typen sind üblicherweise Klassen, oder Strukturen oder Unions, die wiederum Spezialfällen von Klassen sind. Das Sprachmittel der Klasse in C++ hat mehrere Funktionen: Zum einen unterstützt es das Konzept abstrakter Datentypen (ADT), zu anderen hilft es beim korrekten Anlegen und Wegräumen von Daten und Ressourcen.
Den abstrakten Datentypen liegt die Idee der Datenkapselung zu Grunde. Daten werden zusammen mit den Funktionen, die auf diesen Daten arbeiten, zu einem neuen Datentyp gebündelt. Ziel der Übung ist es u.a., Unbefugten den Zugriff auf die Daten zu entziehen und Modifikationen der Daten zu kontrollieren. Auf diese Weise soll sichergestellt werden, daß die Daten nicht in inkonsistente Zustände geraten können. In C++ werden abstrakte Datentypen als Klassen realisiert. In einer idealen Klasse sind die zu schützenden Daten typischerweise private Datenmember der Klasse (gekennzeichnet durch das Schlüsselwort private ); die Funktionen werden als öffentliche Funktionsmember der Klasse (Schlüsselwort public ) implementiert.
Kontrolle allein genügt nicht, um die Daten einer Klasse stets konsistent zu halten. Es muß auch dafür gesorgt werden, daß die Daten korrekt angelegt und wieder weggeräumt werden. Dies ist die zweite wichtige Funktion des Sprachmittels class in C++: es unterstützt die Verwaltung von Ressourcen und internen Daten eines Objekts. Die Konstruktoren einer Klasse sind zuständig für das Anlegen und Initialisieren von Ressourcen, der Destruktor kümmert sich um die Aufräumarbeiten. Der wesentliche Vorteil des Konzept von Konstruktoren und Destruktoren liegt im automatischen Aufruf derselben. Der Compiler führt einen Konstruktor aus, wenn eine Instanz einer Klasse angelegt wird, und ruft den Destruktor, wenn die Instanz ihre Gültigkeit verliert.
Klassen verhalten sich idealerweise wie richtige Datentypen: Objekte eines Datentyps in C++, z.B. int oder long , können nicht nur erzeugt und weggeworfen werden, sondern auch kopiert, einander zugewiesen und ineinander konvertiert. Das gleiche gilt für Objekte eines benutzerdefinierten Typs. Deshalb gibt es neben Konstruktoren und Destruktoren noch eine Reihe weiterer Memberfunktionen in einer Klasse, die automatisch vom Compiler unter gewissen Umständen gerufen werden. Dazu gehören all Operatoren, die in C++ typspezifisch überladen werden können. Konstruktion, Destruktion, Kopieren und Zuweisen sind jedoch die Basisoperationen, die jeder benutzerdefinierte Typ in irgendeiner Form unterstützt - bewußt oder unbewußt. Wenden wir uns dem Unbewußten zu, denn dort gibt es bisweilen Überraschungen.
Compiler-generierte Operationen
Wenn eine Klasse gewisse Operationen nicht selbst definiert, so generiert der Compiler diese Operationen. Daher hat eine Klasse immer die folgenden Memberfunktionen:
- einen Default-Konstruktor,
- einen Copy-Konstruktor, und
- einen Zuweisungsoperator.
class Empty {
public:
Empty(); // Default-Konstruktor
Empty(const Empty& rhs); // Copy-Konstruktor
Empty& operator=(const Empty& rhs); // Zuweisungsoperator
};
Hier sind ein paar Beispiele, die zeigen, wo und wann diese
Operationen automatisch gerufen werden:
const Empty e1; // ruft Default-Konstruktor Empty e2 = e1; // ruft Copy-Konstruktor e2 = e1; // ruft ZuweisungsoperatorDie implizite Generierung dieser Funktionen ist hilfreich, denn in vielen Fällen nimmt einem der Compiler eine Menge Arbeit ab. Selbstverständlich kann der Compiler die Semantik einer Klasse nicht erraten. Was er generiert, sind Defaultversionen der oben aufgeführten Operationen, deren Funktionalität in vielen Fällen genau richtig ist. Unter gewissen Umständen passen jedoch die vom Compiler generierten Operationen einfach nicht zur Semantik der Klasse, wie wir später sehen werden. Schauen wir uns aber zunächst einmal an, was die compiler-generierten Operationen eigentlich tun. Dabei beschränken wir uns auf den Copy-Konstruktor und die Zuweisungsoperation, weil die vollständige Betrachtung der Thematik den Rahmen dieses Artikel sprengen würde.
Vereinfachend könnte man sagen: Der compiler-generierte Copy-Konstruktor kopiert ein Objekt, in dem er seine einzelnen Sub-Objekte kopiert. Der compiler-generierte Zuweisungsoperator weist ein Objekt einem anderen zu, in dem er die einzelnen Sub-Objekte zuweist Im Detail bedeutet es, daß alle nicht-statischen Datenmember einer Klasse kopiert bzw. zugewiesen werden, sowie alle Datenmember, die von direkten Basisklassen geerbt wurden. Abhängig vom Typ des Sub-Objekts wird das Kopieren/Zuweisen unterschiedlich ausgeführt.
- Skalare Typen . Für die in C++ definierten Typen wie bool , char , int , long , float , double , aber auch für Pointer wird bitweise kopiert/zugewiesen.
- Klassen-Typen . Für Instanzen von Klassen wird deren Copy-Konstruktor/Zuweisungsoperator gerufen.
- Arrays . Jedes Element des Arrays wird gemäß seines Typs kopiert/zugewiesen.
Wie ist das nun bei Klassen? Betrachten wir ein einfaches Beispiel - eine Klasse, die einen ganzzahligen Wert mit einem Namen verknüpft:
class NamedInt {
private:
String nameValue;
int intValue;
public:
// diverse Konstruktoren
NamedInt(char* name, int value);
NamedInt(const String& name, int value);
// weitere Memberfunktionen
...
};
Die Klasse besteht aus einer Zeichenkette für den Namen
und einer Ganzzahl. Die definierten Konstruktoren initialisieren die beiden
Datenmember. Man beachte, daß die Klasse
NamedInt
weder einen Default-Konstruktor noch einen Copy-Konstruktor definiert.
Gegeben sei außerdem eine Klasse String. Es handelt sich dabei um
eine Zeichenketten-Klasse mit folgender Definition:
class String {
public:
String(char* val=0);
String(const String& rhs); // Copy-Konstruktor
String& operator=(const String& rhs); // Zuseisungsoperator
...
};
Auch diese Klasse hat keinen Default-Konstruktor, aber sie
hat einen Copy-Konstruktor. Betrachten wir die folgenden Anweisungen:
NamedInt i("Smallest Prime Number", 2);
NamedInt j = i; // ruft den compiler-generierten Copy-Konstruktor
In der ersten Anweisung wird ein Objekt vom typ
NamedInt
konstruiert; es wird der Konstruktor
NamedInt(char*
name, int value)
gerufen. In der zweiten Anweisung wird ein
weiteres Objekt vom Typ
NamedInt
erzeugt, diesmal als Kopie eines anderen Objekts; es wird also ein Copy-Konstruktor
gebraucht. Da der Autor der Klasse
NamedInt
keinen Copy-Konstruktor definiert hat, wird der vom Compiler generierte
verwendet. Dieser Copy-Konstruktor kopiert das Integer-Datenmember
intValue
bitweise, weil es sich um ein Sub-Objekt skalaren Typs handelt, und ruft
für das String-Datenmember
NameValue
den Copy-Konstruktor der Klasse
String
.
Ganz offensichtlich ist das auch sinnvoll so: Die Klasse
String
hat einen Copy-Konstruktor und wird wohl selbst am besten wissen, wie sie
ihre Objekte korrekt kopieren muß. Also überläßt
man das Kopieren des
String
-Datenmembers
dem Copy-Konstruktor der Klasse
String
.
Insgesamt entspricht auch hier die vom Compiler gewählte Strategie
dem, was man ohnehin getan hätte. Man kann sich also die Mühe
sparen und braucht keinen expliziten Copy-Konstruktor zu definieren. Wenden
wir uns nun den Situationen zu, in denen man mit den compiler-generierten
Operationen nicht uneingeschränkt glücklich ist.
Dynamische Allokation von Ressourcen
C++ unterstützt, im Gegensatz zu C, die Verwaltung von Ressourcen durch das Konzept der Konstruktoren und Destruktoren. Die Ressource wird üblicherweise in eine Klasse verpackt, in deren Konstruktor die Ressource angefordert und initialisiert wird, und in deren Destruktor die Ressource wieder frei gegeben wird. Solche Ressourcen können Dateizeiger sein, oder Mutexe und Semaphore, Socket oder Pipe Ids, Window Handles, oder dynamisch allozierter Speicher auf dem Heap. Sehen wir uns also eine Klasse mit einer dynamisch angeforderten Ressource an, eine primitive String-Klasse:
class String {
private:
char *data; // Zeiger auf den internen Puffer
public:
String(char* value=0); // Konstruktor
~String(); // Destruktor
};
Die fragliche Ressource ist der für das Ablegen der
Zeichenkette benötigte Speicher. Er wird im Konstruktor angefordert:
String::String(char* value)
{if(value)
{ data=new char[strlen(value)+1]; // Speicher für Puffer anfordern
strcpy(data,value); // Puffer initialisieren, d.h. Initialwert kopieren
}
else // kein Initialwert vorhanden, d.h. leeren Puffer anlegen
{ data=new char[1];
*data='\0';
}
und im Destruktor wieder freigegeben:
inline String::~String()
{ delete[] data; } // Speicher für Puffer freigeben
Man beachte, daß die Klasse
String
weder einen Copy-Konstruktor noch einen Zuweisungsoperator definiert und
sich also für diese Operationen auf den Compiler verläßt.
Nehmen wir jetzt einmal an, wir hätten zwei String-Objekte und würden
die eine Zeichenkette den anderen zuweisen. Was geschieht dann?
| Ausgangssituation mit zwei String-Objekten | |
String a("Hello");
String b("World");
|

|
| Situation nach der Zuweisung | |
b = a; |

|
void doNothing (String locStr) {}
String s = "Goodbye cruel world";
doNothing(s);
Wir rufen eine harmlose Funktion
doNothing()
auf, die gar nichts tut. Sie bekommt lediglich ein String-Objekt übergeben,
das sie aber nicht anrührt. Überraschenderweise ist nach dem
Aufruf von
doNothing(s);
der String
s
korrumpiert: sein Zeiger
data
zeigt auf einen bereits freigegeben Speicherbereich. Jeder weitere Zugriff
auf
s
kann, muß aber nicht,
zum Programmabsturz führen. Es handelt sich um eine dieser wunderschönen
Situationen, deren Konsequenzen erst viel später, an ganz anderen
Stellen im Programm zu Problemen führen und deren Ursache so unendlich
mühselig zu finden ist. Was ist hier passiert?
Bei der Übergabe des Strings
s
an die Funktion
doNothing()
wird
eine Kopie des String-Objekts angelegt. Das liegt daran, daß die
Funktion
doNothing()
ihr Argument
als Wert und nicht als Referenz bekommen soll. Wäre die Funktion als
void
doNothing (String& locStr)
deklariert, so würde nur
eine Referenz auf das String-Objekt
s
übergeben. In unserer Situation muß aber eine Kopie von
s
gemacht werden. Kopien werden mit Hilfe des Copy-Konstruktors erzeugt.
Die Klasse
String
hat keinen expliziten
Copy-Konstruktor. Also wird der vom Compiler generierte Copy-Konstruktor
verwendet. Der wiederum erzeugt eine bitweise Kopie des Originals, d.h.
es wird nur der Zeiger
data
kopiert,
nicht aber der Inhalt des Speicherbereichs, auf den der Zeiger zeigt.
| Situation bei Aufruf der Funktion doNothing() | |
void doNothing (String locStr) {}
String s = "Goodbye cruel world";
doNothing(s);
|
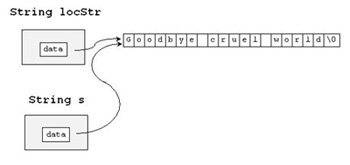
|
| Situation nach dem Verlassen der Funktion doNothing() | |
void doNothing (String locStr)
{
...
} Hier geht locStr "out of scope"!
|
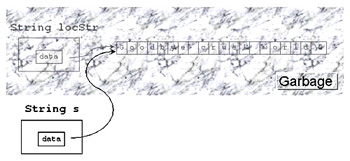
|
Solche Überraschungen will man gerne vermeiden, insbesondere da man die resultierenden Probleme erst sehr viel später erkennt und dann die Ursache des Übels nur noch schwer zu identifizieren ist. Was ist aber eigentlich die Ursache des Übels hier? Die Klasse String ist irgendwie falsch. Einige Problempunkte haben wir bereits identifiziert. Der compiler-generierte Zuweisungsoperator hinterläßt Memory Leaks. Der Destruktor gibt Speicher zweimal oder viel zu früh wieder frei. Eine Lösung für das Problem mit dem Zuweisungsoperator wurde oben bereits skizziert: Man definiere einen expliziten Zuweisungsoperator für die Klasse String, der den Speicher korrekt frei gibt. Auch der Destruktor kann korrigiert werden. Es muß gezählt werden, wie viele String-Objekte auf denselben Speicherbereich zeigen, und es darf dann erst bei der Destruktion des letzten solchen String-Objekts der Speicher frei gegeben werden. Diese Technik wird als Reference Counting bezeichnet und wird in jeder realen Implementierung von String-Klassen verwendet. In diesem Fall muß dann aber auch der Copy-Konstruktor explizit definiert werden, weil das Kopieren jeweils ein neues Objekt erzeugt, welches den Speicher gemeinsam mit seinem Original benutzt und also der Referenzzähler inkrementiert werden muß. Der compiler-generierte Copy-Konstruktor reicht also nicht mehr aus.
Resümee
Am Beispiele einer primitiven String-Klasse haben wir gesehen, daß C++ dem Programmierer bisweilen kleine Stolpersteine in den Weg legt. Die compiler-generierten Operationen einer Klasse sind ein Beispiel dafür. Sie sind in vielen Fällen sehr, sehr nützlich. In manchen Fällen haben sie aber die falsche Semantik und ziehen überraschende Fehler nach sich. Bisweilen mag es schwierig erscheinen, zu entscheiden, wann eine Klasse nun einen expliziten Copy-Konstruktor und Zuweisungsoperator braucht, und wann sie keinen braucht. Es ist z. B. keine gute Lösung, nun grundsätzlich immer alle Operationen explizit zu definieren. Erstens ist das viel Arbeit. Zweitens kann man viele Fehler dabei machen. Drittens ist der Compiler einfach effizienter, d.h. man ruiniert sich u.U. die Performance mit hand-codierten Operationen, die nicht nötig sind. Es muß also immer genau überlegt werden, ob explizite Operationen gebraucht werden oder nicht. Als Faustregel kann man sich merken, daß sie mit Wahrscheinlichkeit immer dann explizit definiert werden müssen, wenn in der Klasse dynamisch Ressourcen angefordert werden. Der typischste solche Ressource ist Speicher auf dem Heap. Wenn eine Klasse also Datenmember hat, die Zeiger oder Referenzen sind, dann sollte man sich Gedanken über deren Initialisierung und Verwendung machen, und sehr wahrscheinlich wird man feststellen, daß der compiler-generierte Default-Konstruktor, Copy-Konstruktor, Zuweisungsoperator und Destruktor nicht ausreichen.
Der Stolperstein bei der Entscheidung für oder gegen
die compiler-generierten Operationen beim Design einer Klasse ist nur einer
von unzähligen Beispielsweise haben wir nicht überlegt, wann
eigentlich ein Destruktor virtuell sein muß, oder wie ein korrekter
Zuweisungsoperator aussehen muß, wie globale und statische Variablen
korrekt initialisiert werden, etc. etc. Wie können Fehler schon im
Vorfeld vermieden werden? Selbstverständlich ist Erfahrung durch nichts
zu ersetzen. In der Praxis ist die notwendige Erfahrung aber oft nicht
da, und außerdem will man ja nicht alles durch schlechte Erfahrungen
lernen. Werkzeuge können Hilfestellung leisten. Viele fehleranfällige
Situationen können durch statische Analyse des Programms erkannt werden
und ein Tool kann entsprechende Hinweise geben. Solche Werkzeuge sind dem
lint
Programm in C ähnlich. Sie sind häufig sogar in der Lage, die
Einhaltung von Regeln aus Style Guides zu überprüfen. Natürlich
können Werkzeuge und Style Guides nicht alle potentiellen Fehler erkennen.
Manche Probleme können nur entdeckt werden, wenn man die Semantik
einer Klasse versteht. Die korrekte Verwendung von
const
fällt typischerweise in diese Kategorie. Semantische Fehler kann nur
ein Reviewer oder Mentor finden. Wer Fehler in C++ Programmen nicht erst
beim Test finden will, sollte einen Style Guide verwenden, sich ein entsprechendes
Werkzeug besorgen, und die Programme regelmäßige von einem erfahrenen
Mentor reviewen lassen.
|
If you are interested to hear more about this and related topics you might want to check out the following seminar:
|