| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java 8
Benutzer-definierte Stream-Sourcen und Spliteratoren
Java Magazin, September 2016
|
Dies ist die Überarbeitung eines Manuskripts für einen Artikel, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Wir wollen uns in diesem Beitrag ansehen, wie man eigene Datenabstraktionen als Sourcen für Java 8 Streams verwenden kann. Damit ist es dann möglich, die gesamte Stream-Funktionalität, die wir uns in vorhergehenden Artikel angesehen haben, auf eigene Datenabstraktionen anzuwenden.
Ausgangssituation
String text = "A Stream is a sequence of elements supporting
sequential and parallel aggregate operations.";
long cnt = text.chars()
.filter(i -> !Character.isSpaceChar(i))
.count();
System.out.println("number of non-space characters:
" + cnt);
Wir ermitteln, wie viele non-space Character der String text enthält, indem wir aus text einen IntStream erzeugen ( chars() ). Danach werden nur die non-space Character durch den Filter gelassen ( filter() ) und diese anschließend gezählt ( count() ).
Es mag auf den ersten Blick überraschend
erscheinen, dass die Character eines
String
s
nicht als Source für einen
CharStream
dienen, sondern als
IntStream
s verarbeitet
werden. Der Grund ist, dass es keinen
CharStream
gibt und deshalb der Stream des nächst größeren primitiven Typs verwendet
wird, für den ein Stream Typ existiert.
Wie gesagt, der JDK stellt mit Java 8 bereits
die Funktionalität zur Verfügung, aus einer
CharSequence
(also in unserem Beispiel einem
St
r
ing
)
einen Stream zu erzeugen. Im Folgenden wollen wir uns ansehen, was wir
tun können bzw. müssen, wenn wir aus einer eigenen Datenabstraktion einen
Stream erzeugen wollen.
Um nicht extra für diesen Artikel eine eigene
Datenabstraktion implementieren zu müssen, verwenden wir die
ImmutableList
aus der Guava 19.0 Bibliothek (/
ILI
/).
ImmutableList
ist eine abstrakte Klasse. Sie hat Factory-Methoden, die eine Instanz von
RegularImmutableList
erzeugen, wenn mehr als ein Element in der Liste ist. Die Klasse
RegularImmutableList
ist von Außen nicht sichtbar, da sie
protected
im Package
com.google.common.collect
deklariert ist. Neben
RegularImmutableList
gibt es weitere Spezialisierungen von
ImmutableList
für den Fall, dass die Liste ein oder kein Element enthält. Diese sind
aber für unseren Artikel nicht weiter relevant.
Wie der Name schon sagt, repräsentiert die ImmutableList eine unveränderliche Liste. Eine solche unveränderliche Liste eignet sich zum Beispiel, um beim Progammstart alternative Konfigurationsdaten, die im weiteren Verlauf nur gelesen werden, in einer statischen final Referenzvariable vom Typ ImmutableList zu speichern. Diese Konfigurationsdaten können dann zum Beispiel durchsucht werden, um das Programm optimal an die Ablaufumgebung anzupassen. Hier wäre es vorteilhaft, wenn man aus der ImmutableList einen Stream machen könnte, um das Durchsuchen mit Hilfe von Stream-Operationen wie filter() , reduce() , usw. erledigen zu können.
Die ImmutableList als Stream-Source
String[] stringArr = populateArray();
Stream<String> sequentialStringStream = ImmutableList.copyOf(stringArr).stream();
Wir erzeugen aus dem
stringArr
mit Hilfe der Factory-Methode
copyOf()
eine
ImmutableList
. Um aus ihr einen
Stream<String>
zu erzeugen, rufen wir auf der
ImmutableList
-Instanz
stream()
auf. Der Code lässt sich fehlerfrei übersetzten und auch zur Laufzeit
funktioniert alles fehlerfrei.
Dies ist bemerkenswert, wenn man berücksichtigt, dass Guava 19.0 nur JDK 6.0 benötigt (/ GRH /). Das heißt, die Guava Entwickler haben den Sourcecode ihrer Library noch gar nicht an Java 8 angepasst; trotzdem kann man aus der ImmutableList unter Java 8 einen Stream erzeugen. Das ist erstaunlich.
Aber es ist nicht nur möglich,
ImmutableList
als Source eines sequenziellen
Stream
<
String
>
zu verwenden; sie kann auch als Source eines parallelen Streams genutzt
werden:
String[] stringArr = populateArray();
Stream<String> parallelStringStream = ImmutableList.copyOf(stringArr).parallelStream();
Paralleler Stream bedeutet hier, dass die
Stream-Operationen, die auf diesem Stream aufgerufen werden, mit mehreren
Threads parallel abgearbeitet werden. Mehr Details zu parallelen Streams
finden sich in einem unserer vorhergehenden Artikel (/KLS1/).
Was steckt nun dahinter, dass wir aus der
ImmutableList
aus Guava 19.0 bei Bedarf einen sequentiellen bzw. einen parallelen Stream
erzeugen können? Streams gibt es doch erst seit Java 8 im JDK und die
Guava Library 19.0 ist noch gar nicht an Java 8 angepasst worden.
Im Wesentlichen sind es drei Gründe, die dafür sorgen, dass es funktioniert:
• Immutable List ist (indirekt) vom Interface java.util.C ollection aus dem JDK abgeleitet.
• Mit Java 8 ist es möglich, dass Interface-Typen Instanz-Methoden mit Implementierung enthalten können, sogenannte Default-Methoden (siehe auch / KLS2 /).
•
Mit
Java 8 ist das Interface
Collection
(unter
anderem) um die Default-Methoden
stream()
bzw.
parallelStream()
erweitert worden.
Verallgemeinert bedeutet dies, dass jede
Klasse, die von dem Interface
Collection
abgeleitet ist, als Stream-Source verwendet werden kann. Dazu muss man
nur die Methode
stream()
bzw.
parallelStream()
auf der Instanz der jeweiligen Klasse aufrufen.
Das ist die gute Nachricht. Die schlechte
Nachricht ist, dass die Performance dieser Default-Implementierung im sequentiellen,
aber ganz besonders im parallelen, Fall nicht besonders gut ist. Es liegt
einfach daran, dass die Default-Implementierung nicht an die spezifischen
Eigenschaften der jeweiligen Collection anpasst ist. Für die JDK Collections
gibt es natürlich die spezifischen Anpassungen mit Java 8. Dazu wurden
die aus
Collection
geerbten Implementierungen
der Default-Methoden in den jeweiligen abgeleiteten Klassen (z.B.
ArrayList
)
überschrieben.
Wir wollen uns im Weiteren ansehen, ob und wie wir dies auch für die ImmutableList tun können. Fangen wir damit an, dass wir uns die Stream Architektur genauer ansehen, speziell unter dem Aspekt, wie Streams mit ihrer Source verbunden sind.
StreamArchitektur: Stream, Stream-Source und Spliterator
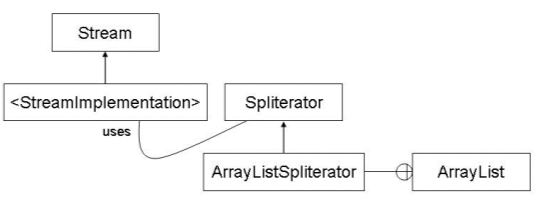
Jede konkrete Stream-Source, in unserem Diagramm
oben beispielhaft die
ArrayList
, hat
eine konkrete
Spliterator
-Implementierung
(
ArrayListSpliterator
)
und stellt diese der <
StreamImplementation
>
zur Verfügung. Dabei ist die
Spliterator
-Implementierung
im Allgemeinen eine Inner Class der Stream-Source-Klasse.
Das Spliterator -Interface bzw. seine konkrete Implementierung für jeden Stream-Source-Typ sind die zentralen Elemente für die Interaktion von Stream und Stream-Source.
Kommen wir in diesem Zusammenhang noch mal
auf unser Beispiel mit der
ImmutableList
zurück. Da wir die
ImmutableList
als
Stream-Source verwenden können, würde es bedeuten, dass auch sie eine
Spliterator
-Implementierung
hat. Wie kann das sein, wenn die
ImmutableList
aus Guava 19.0 nur den JDK 6.0 benötigt, aber das
Spliterator
-Interface
erst seit 8.0 im JDK ist? Es erklärt sich dadurch, dass das
Collection
-Interface
eine Default-Methode
spliterator()
hat,
die für alle von
Collection
abgeleiteten
Typen eine
Spliterator
-Implementierung
zur Verfügung stellt. Diese Implementierung ist im Wesentlichen für
die oben schon diskutierte eingeschränkte Stream-Performance verantwortlich.
Die Implementierung basiert nämlich allein auf der
Iterator
-Funktionalität
der Collection. Zur Erinnerung: jede Collection hat einen Iterator, da
Collection
von
Iterable
abgeleitet ist.
Wie oben bereits angedeutet, würde eine spezifische Spliterator -Implementierung für ImmutableList diese Performance-Einschränkung beseitigen. Bevor wir uns an eine solche Implementierung machen, schauen wir uns das Spliterator -Interface erst einmal genauer an.
Das Spliterator -Interface
Das Teilen der unterliegenden Stream-Source
wird bei der parallelen Stream-Verarbeitung benötig, um das inhärent
sequentielle Ausgangsproblem in viele Teilprobleme zu zerlegen, die parallel
verarbeitet werden können. Details dazu finden sich in unserem vorhergehen
Artikel zu parallelen Streams (/
KLS1
/).
Für das Teilen stellt das
Spliterator
-Interface
die Methode:
Spliterator<
T
>
trySplit()
zur Verfügung. Wird sie auf einem
Spliterator
aufgerufen, so liefert die Methode einen neuen
Spliterator
zurück, der den abgespaltenen Teil repräsentiert, während sich die Original-
Spliterator
-Instanz
um diesen Teil verkleinert hat.
Das Iterieren wird sowohl bei der sequentiellen wie auch bei der parallelen Stream-Verarbeitung benutzt, um die Funktionalität der Stream-Operationen auf die einzelnen Elemente der unterliegenden Stream-Source anzuwenden.
Zum Iterieren bietet das
Spliterator
-Interface
zwei Methoden an:
boolean tryAdvance(Consumer<? super T> action)
void forEachRemaining(Consumer<? super T> action)
tryAdvance()
wendet die Funktionalität der
action
vom Typ
Consumer
auf das nächste Element
an. Der Returnwert gibt an, ob ein â??nächstes’ Element existierte
(
true
) oder nicht (
false
).
forEachRemaining()
wendet die
action
auf alle verbliebenen
Elemente an. Das
Spliterator
-Interface
enthält eine
default
-Imlementierung
für
forEachRemaining()
. Diese ruft in
einer Schleife solange
tryAdvance()
auf,
bis
tryAdvance()
false
liefert.
Das
Spliterator
-Interface
hat noch eine Reihe weiterre Methoden die sich um die
Characteristics
der unterliegenden Stream-Source drehen. Die Characteristics sind als
Bit-Feld (d.h. 2er Potenzen) implementiert. Sie dienen dazu die Stream-Implementierung
auf Basis von spezifischen Eigenschaften der Stream-Source zu optimieren.
Diese Eigenschaften sind zum Beispiel, dass die Stream-Source eine feste,
bekannte Länge hat (
SIZED
), dass sie eine
feste Reihenfolge bei der Iterierung hat (
ORDERED
)
oder dass alle Elemente der Stream-Source unterschiedlich sind (
DISTINCT
).
Dies war erst mal ein kurzer Überblick über das Spliterator -Interface. Weitere Details finden sind in der Javadoc und der Implementierung des Interfaces.
Der IteratorSpliterator
Schauen wir uns einmal im Detail an, wo die
eingeschränkte Performance dieses Spliterators genau herkommt.
Relativ offensichtlich ist, dass die Implementierung
von
trySplit()
, also die Funktionalität
des Teilens der unterliegenden Stream-Source, nicht unbedingt optimal ist.
Denn, um die Hälfte der unterliegenden Stream-Source in einem neuen Spliterator
abzuspalten, muss der Spliterator mit Hilfe der Methoden
hasNext()
und next() des adaptierten Iterators bis zur Hälfte der Stream-Source
iterieren. Bei einer index-basierten Stream-Source wie unserem
RegularImmutableList
kann dies natürlich viel effizienter durch eine Indexberechung implementiert
werden, wie wir weiter unten noch sehen werden. Die suboptimale Implementierung
von
trySplit()
führt vor allem bei großen
Stream-Sourcen mit vielen Elementen zu deutlichen Performance-Einschränkungen
bei der Benutzung paralleler Streams.
Die Performance-Einschränkungen bei der
sequentiellen Streamverarbeitung resultieren eher aus verschiedenen kleinen
Details der
IteratorSpliterator
-Implementierung.
Ein Detail ist zum Beispiel die Redundanz beim Iterieren mit
hasNext()
und
next()
wie hier im Code von
tryAdvance()
:
if (it.hasNext()) {
action.accept(it.next());
return true;
}
Die Redundanz entsteht dadurch, dass
next()
intern wieder
hasNext()
aufruft, wie
zum Beispiel in der Implementierung des Iteratators unserer
RegularImmutableList
:
public final E next() {
if (!hasNext()) {
throw new NoSuchElementException();
}
return get(position++);
}
Dadurch wird die Bedingung, ob es weitere Elemente gibt, noch einmal geprüft, obwohl wir im übergeordneten Kontext bereits wissen, dass es so ist. Dies liegt natürlich wieder daran, dass der IteratorSpliterator auf die Funktionalität des Iterators der Stream-Source zurückgreifen muss. Die Prüfung in der next() -Methode, ob es weitere Elemente gibt, ist typisch für die Implementierungen der next() -Methode des java.util.I terator -Interfaces.
Die SplitableImmutableList
Bevor wir dies tun, schauen wir uns noch
mal die Gesamtsituation an. Wir haben in diesem Artikel die
ImmutableList
bzw. ihre konkrete Implementierung
RegularImmutableList
als Beispiel für eine eigene Stream-Source verwendet. Genaugenommen
ist es aber nicht unsere eigene Implementierung sondern eine Open-Source-Third-Party-Implementierung
aus der Guava Library von Google. Hätten wir eine eigene Implementierung,
könnten wir einfach hingehen und den neuen Spliterator als eingeschachtelten
Typ in der
RegularImmutableList
implementieren.
Leider ist die
RegularImmutableList
nicht
unsere Implementierung, deshalb geht es nicht so einfach.
Um aber das Beispiel in dem Artikel weiter
verwenden zu können, kopieren wir den gesamten Source-Code der
RegularImmutableList
in eine eigene Klasse
SplitableImmutableList
und arbeiten mit dieser weiter. Es ist natürlich immer ein recht zweifelhaftes
Vorgehen, wenn man den Source-Code aus einer Third-Party-Library kopiert,
um ihn zu verändern. Wir machen es hier nur, um in diesem Artikel das
Beispiel zu Ende diskutieren zu können. Die
RegularImmutableList
dient hier lediglich als Beispiel, wie man eigene Abstraktionen verändern
kann/muss, um sie effizient als Stream-Sourcen zu nutzen.
Schauen wir uns zuerst ein paar Details der
Implementierung der
SplitableImmutableList
an, die zum jetzigen Zeitpunkt einfach eine Kopie der
RegularImmutableList
ist. Sie hat die folgenden drei Felder:
private final transient int offset;
private final transient int size;
private final transient Object[]
array;
array
ist die
Referenz auf das unterliegende Array.
offset
und
size
geben an, welcher Bereich des
arrays
durch die
SplitableImmutableList
-Instanz
repräsentiert wird. Wenn es das ganze
array
ist, sind
offset==0
und
size==array.len
g
th
.
Da die Konstruktoren der Klasse
package
-protected
sind, bieten wir eine
public
Factory-Methode
an (ähnlich wie sie auch für die
RegularImmutableList
in
ImmutableList
existiert):
public static <E> SplitableImmutableList<E> copyOf(E[] elements) {
return new SplitableImmutableList<E>(checkElementsNotNull(elements.clone()));
}
Die Implementierung erzeugt eine
shallow
copy
des Arrays
elements
, prüft
danach, ob alle Elemente ungleich
null
sind, und initialisiert mit Hilfe des Konstruktors die drei Felder so,
dass die
SplitableImmutableList
-Instanz
das gesamte Array repräsentiert.
Soviel erst einmal zur Implementierung von SplitableImmutableList , die wie gesagt, im Wesentlichen eine Kopie der Implementierung der RegularImmutableList ist.
Ein Spliterator für die SplitableImmutableList
Um einen eigenen Spliterator zu implementieren,
schaut man sich am Besten zuerst die Spliteratoren im JDK an, die es dort
für Speicherstrukturen mit ähnlicher Topologie gibt. Das heißt, in
unserem Fall ist es naheliegend, sich den Spliterator für ein
Object
-Array
anzusehen, weil dies die zentrale Datenstruktur in der Implementierung
der
SplitableImmutableList
ist.
Der entsprechende Spliterator ist
Spliterators.ArraySplitertor
.
Es ist (wie vorher
IteratorSpliterator
)
ein eingeschachtelter Typ in der Klasse
Spiterators
,
der
package
-protected ist.
Hier ist zum Beispiel die
trySplit()
-Implementierung
des
ArraySpliterators
, die auf einer
Index-Berechung basiert und damit äußerst effizient teilt:
public Spliterator<T> trySplit() {
int lo = index, mid = (lo + fence) >>> 1;
return (lo >= mid)
? null
: new ArraySpliterator<>(array, lo, index = mid, characteristics);
}
Zum besseren Verständnis des Codes sei noch
dazu gesagt, dass
index
und
fence
die Felder sind, die den Anfang bzw. das Ende der
ArraySpliterator
-Instanz
bezüglich
array
angeben. array ist
ein weiteres Feld des
Spliterators
.
Es ist die Referenz auf das unterliegende Array, mit dem die
ArraySpliterator
-Instanz
assoziiert ist. Der System-Programmierer-Stil des Codes ist möglicherweise
nicht jedermanns Sache. So ist die Division durch zwei als „
>>>
1
“ implementiert und die Zuweisung an das Feld
index
erfolgt in der Parameterlist beim Aufruf des Konstruktors des
ArraySpliterators
für den abgespaltenen Teil.
Im allgemeinen Fall lässt man sich von der
im JDK gefundenen Implementierung inspirieren - was dann meist auf mehr
oder weniger viel Copy-and-Paste-Programmierung hinausläuft. In unserem
Fall sind wir in einer günstigeren Position, denn die
ArraySpliterator
-Implementierung
passt ohne weitere Veränderungen. Wie oben bereits erwähnt, ist
ArraySpliterator
zwar
package
-protected in
java.util
.
Aber
Spliterators
hat eine
public
Factory-Methode, mit der wir unseren
ArraySplit
erat
or
erzeugen können:
public static <T> Spliterator<T> spliterator(Object[]
array, int fromIndex, int toIndex,
int additionalCharacteristics)
Das heißt, wir müssen nur noch in unserer SplitableImmutableList -Implementierung die Methode spliterator() mit einem Aufruf dieser Factory-Methode überschreiben:
public Spliterator<E> spliterator() {
return Spliterators.spliterator(array, offset,
size,
Spliterator.ORDERED
| Spliterator.IMMUTABLE | Spliterator.NONNULL);
}
Als Characteristics setzen wir zusätzlich zu den im ArraySpliterator bereits gesetzten Spliterator.SIZED , Spliterator.SUBSIZED noch:
• Spliterator.ORDERED , weil die Elemente in unserer SplitableImmutableList eine festgelegte Reihenfolge haben,
• Spliterator.IMMUTABLE , weil unserer SplitableImmutableList unveränderlich ist, und
• Spliterator.NONNULL , weil die copyOf() -Factory-Methode, mit der eine SplitableImmutableList konstruiert werden kann, prüft, dass die Elemente des übergebenen Arrays ungleich null sind (siehe Implementierung oben).
Der Performance-Vergleich
Zum Vergleich haben wir deshalb einen Micro-Benchmark
durchgeführt. Dabei suchen wir in einer
RegularImmutableList
bzw.
SplitableImmutableList
von 1000000
Integer
-Werten
das größte Element:
Integer[] array = new Integer[1_000_000];
... // fill array with random numbers
ImmutableList.copyOf(array).stream() //.parallel()
.max(Comparator.comparingInt(Integer::intValue))
.ifPresent(m -> System.out.println("ImmutableList,
max = "+m));
SplitableImmutableList.copyOf(array).stream() //.parallel()
.max(Comparator.comparingInt(Integer::intValue))
.ifPresent(m -> System.out.println("SplitableImmutableList,
max = "+m));
Für den Benchmark haben wir bewusst ein
Szenario gewählt, bei dem die CPU-Kosten für die Verarbeitung pro Stream-Element
relativ gering sind, so dass im Wesentlichen die Kosten für den Zugriff
auf die Elemente das Ergebnis bestimmen.
Den Benchmark haben wir auf einem älteren
Einstiegs-Laptop (Dual-Core Intel Pentium B960 CPU) durchgeführt. Die
Resultate sehen folgendermaßen aus:
sequentiell parallel
RegularImmutableList 45,24ms 49,13ms
SplitableImmutableList
31,82ms 19,88ms
Die Ergebnisse entsprechen dem, was wir bereits
oben auf Basis des Source-Codes diskutiert haben. Aber schauen wir uns
noch mal die Details genauer an.
Die
RegularImmutableList
mit dem
IteratorSpliterator
hat auf Grund
der schlechten Teilbarkeit eine ungenügende Performance bei paralleler
Verarbeitung. Die Suche nach dem größten Element dauert bei paralleler
Verarbeitung mit beiden Cores länger als bei sequentieller Verarbeitung
mit nur einem Core. Das heißt, die schlechte Teilbarkeit kostet so viel,
dass selbst die Benutzung eines weiteren Cores die zusätzlichen Kosten
nicht kompensieren kann.
Bei der parallelen Verarbeitung ist die
SplitableImmutableList
mit dem
ArraySpliterator
deutlich besser.
Sie kann bei paralleler Verarbeitung die Performance um rund 160% steigern.
Das liegt an der guten Teilbarkeit. Denn wie wir oben bereits gesehen haben,
besteht das Teilen nur aus einer Index-Berechnung.
Die Performance-Steigerung der
SpitableImmutableList
gegenüber der
RegularImmutableList
bei
sequentieller Verarbeitung beträgt ca. 142%. Hier kommen die vielen
kleinen Optimierungen zum Tragen, die sich aus der spezifischen Spliterator-Implementierung
(
ArraySpliterator
) ergeben gegenüber einer
Spliterator-Implementierung, die nur einen Iterator zu einem Spliterator
adaptiert (
IteratorSpliterator
).
Bleibt noch die Bewertung, ob sich der Aufwand,
einen spezifischen Spliterator für eine eigene Datenstruktur anzubieten,
lohnt. Eine allgemeine Empfehlung kann man eigentlich nicht abgeben,
da es jeweils von der konkreten Situation abhängt. In unserem Beispiel
war der Aufwand relativ gering, da wir den
ArraySpliterator
aus dem JDK direkt nutzen konnten. Im Allgemeinen ist das nicht so und
man muss den spezifischen Spliterator selbst mit mehr Aufwand implementieren.
Die Performance-Steigerung bei der sequentiellen
Verarbeitung dürfte wohl im Allgemeinen in dem Bereich liegen, den wir
in unserem Beispiel gesehen haben.
Die Steigerung bei paralleler Verarbeitung lässt sich nicht so ohne Weiteres verallgemeinern. Sie hängt von der Topologie der eigenen Stream-Source ab, weil der Aufwand für die Teilung stark von der Topologie abhängt. Wenn wir zum Beispiel eine eigene verkettete Liste als neue Stream-Source verwenden wollen, so kann man für diese den Teilungsalgorithmus gegenüber dem IteratorSpliterator fast gar nicht in der Performance verbessern, weil man selbst in der Implementierung des spezifischen Spliterator einen ähnlichen Algorithmus verwenden muss.
Zusammenfassung
Noch ein ergänzender Tipp an dieser Stelle:
Auch Datenstrukturen, die keine
Collection
sind, aber über einen Iterator verfügen, können den
IteratorSpliterator
nutzen, um als Stream-Sourcen genutzt zu werden. Dafür gibt es in der
Companion-Klasse
Spliterators
eine Factory-Methoden:
<T> Spliterator<T> spliterator(Iterator<?
extends T> iterator, long size, int characteristics)
die den Iterator auf einen Spliterator adaptiert
und dabei intern den
IteratorSpliterator
verwendet. Um aus diesem Spliterator dann einem Stream zu machen, benutzt
man die Factory-Methode:
<T> Stream<T> stream(Spliterator<T> spliterator,
boolean parallel)
aus der Klasse
StreamSupport
.
Der Vorteil bei der Benutzung des
IteratorSpliterator
ist, dass er wenig Implementierungs-Aufwand erfordert in den Fällen, in
denen ein Iterator für die Datenstruktur bereits vorhanden ist. Der
Nachteil dieses Ansatzes ist, dass die Stream-Performance nicht so optimal
ist, weil der
IteratorSpliterator
ein
generischer Spliterator ist, der nicht an die Datenstruktur angepasst ist,
die als Stream-Source verwendet werden soll. Diesen Nachteil kann man
eliminieren, wenn man genau so einen an die Datenstruktur angepassten Spliterator
zur Verfügung stellt. Im Allgemeinen muss man einen solchen angepassten
Spliterator neu implementieren. Wir konnten in unserem Beispiel den bereits
im JDK vorhandenen
ArraySpliterator
benutzen.
Mit Hilfe eines Benchmarks haben wir uns
angesehen, wie groß der Performance-Unterschied zwischen dem generischen
IteratorSpliterator
und dem spezifischen
ArraySpliterator
bei sequentieller und paralleler Stream-Verarbeitung ist.
Welchen Weg man gehen möchte, wenn man eine eigene Datenabstraktion als Stream-Source nutzen möchte, hängt von der jeweiligen Situation ab. Im Allgemeinen läuft die Entscheidung auf einen Trade-Off zwischen Implementierungsaufwand und Stream-Performance hinaus.
Literaturverweise
| /GRH/ |
Guava
Release History
|
|
Guava
19.0: ImmutableList<E>
|
|
| /KLS1/ |
Klaus
Kreft & Angelika Langer: Parallele Streams
|
| /KLS2/ |
Klaus
Kreft & Angelika Langer: Default Interface Methoden
|
![]()
Die gesamte Serie über Java 8:
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
|||||||||||||
Seminar
|
Related Reading
|
||||||||||||