| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java 8
Low-Level-Aspekte beim API Design mit Lambdas
Java Magazin, Juli 2016
|
Dies ist die Überarbeitung eines Manuskripts für einen Artikel, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Wir haben
uns im letzten Beitrag angesehen, was man unter Verwendung von Lambdas
anders machen könnte als ohne diese neuen Sprachmittel. Dabei ging es
um das Design von Schnittstellen, die Funktionalität in Form von Lambda-Ausdrücken
oder Methodenreferenzen entgegennehmen und diese Funktionalität irgendwann
später ausführen ("deferred execution"). Dieses Mal wollen wir uns
ein weiteres Beispiel für eine Programmiertechnik ansehen, die ohne Lambdas
wenig attraktiv wäre. Es geht um das sogenannte Execute-Around-Pattern.
Das ist eine Programmiertechnik, mit der sich redundanter Code elegant
vermeiden lässt. Am Beispiel von Execute-Around wollen wir außerdem
auf einige Aspekte der neuen Sprachmittel eingehen, die gelegentlich übersehen
oder ignoriert werden, weil sie lästig sind. Zum Beispiel wollen wir der
Frage nachgehen: Soll ich die Methoden meiner neu entworfenen, lambda-fähigen
Schnittstelle überladen, oder besser nicht? Soll meine neue Schnittstelle
Checked Exceptions zulassen? Muss ich bei der Deklaration meiner lambda-fähigen
Schnittstelle Generics und Wildcards verwenden - und wenn ja, wie? Welche
anderen Sprachkomplikationen gibt es, die ich beim Design meiner lambda-fähigen
Schnittstelle beachten sollte?
Das Execute-Around-Pattern
Die Ausgangssituation
public final class TimeInterval {
private LocalTime lower, upper;
public TimeInterval(LocalTime l, LocalTime u) {
lower = l;
upper = u;
}
public void setLower(LocalTime l) {
if (l.isBefore(upper)||l.equals(upper)) {
lower = l;
}
}
public LocalTime getLower() {
return lower;
}
public void setUpper(LocalTime u) {
if (lower.isBefore(u) || lower.equals(u)) {
upper = u;
}
}
public LocalTime getUpper() {
return upper;
}
public boolean contains(LocalTime i) {
return (lower.isBefore(i)||lower.equals(i)) && (i.isBefore(upper)||i.equals(upper));
}
}
Dabei ist
LocalTime
eine Abstraktion aus dem
java.time
-Package
des JDK, das es seit Java 8 gibt.
Nehmen wir mal an, wir wollen ín allen relevanten
Methoden der Klasse die Prüfung hinzufügen, ob die Zeitspanne gültig
ist. Das wäre eine Überprüfung der sogenannten
Klassen-Invariante
(engl.
class invariant
). Die Klassen-Invariante ist ein Element
des Design-by-Contract-Programming (siehe z.B. /DbC/). Die Idee des Design-by-Contract
besteht darin, dass für einen Typ und seine Operationen Vorbedingungen
(engl.
preconditions
), Nachbedingungen (engl.
postconditions
)
und die schon erwähnten Invariante definiert werden. Sie bilden den
Vertrag (engl.
contract
), den die Implementierung des Typs erfüllen
muss. Die Precondition beschreibt, welchen Bedingungen und/oder Zustände
am Anfang einer Operation herrschen müssen, damit die Operation überhaupt
ausgeführt werden kann. Die Postcondition beschreibt, welche Bedingungen
und/oder Zustände die Operation hinterlässt, wenn sie fertig abgelaufen
ist. Die Pre- und Postconditions beziehen sich auf die einzelnen Operationen
und sind für jede Operationen anders. Die Invariante ist von den einzelnen
Operationen unabhängig und beschreibt Bedingungen und Zustände, die für
jedes Objekt stets (genauer gesagt: zu Beginn und am Ende jeder Operation)
erfüllt sein müssen. Insbesondere in der Objekt-Orientierung wird erwartet,
dass jede Operation, die auf ein Objekt angewandt wird, das Objekt von
einem gültigen Zustand in den nächsten gültigen Zustand überführt.
Diese Idee eines "gültigen Zustands" ist genau das, was die Invariante
ausdrückt. Die Implementierung einer Operation gemäß Design-by-Contract
sähe dann im Prinzip so aus:
check precondition
check invariant
the operation's actual implementation
check invariant
check postcondition
Design-by-Contract ist eine Qualitätssicherungstechnik,
die in manchen Programmiersprachen (z.B. Eiffel, D, Ada) direkt durch Sprachmittel
unterstützt wird. Man kann das Design-by-Contract-Prinzip jedoch in
jeder objekt-orientierten Sprache anwenden. Solche Invarianten-Prüfungen
können beispielsweise in Java zur Unterstützung bei der Implementierung
verwendet werden, damit Fehler schneller erkannt werden. Bei Klassen
mit einer komplexen Invarianten, wie zum Beispiel bei einem balancierten
Binärbaum, ist eine Überprüfung der Invarianten am Anfang und Ende jeder
Methode zur Selbstunterstützung bei der Entwicklung durchaus hilfreich
und sinnvoll.
Da wir in diesem Beitrag nicht Design-by-Contract,
sondern das Execute-Around-Pattern betrachten wollen, schenken wir uns
die Vor- und Nachbedingungen für unsere Beispielklasse
TimeInterval
und prüfen nur die Invariante. Sie ist simpel:
lower
und
upper
müssen ungleich
null
sein und
lower
muss zeitlich vor
upper
liegen. Die Klasse
TimeInterval
könnte
mit der Invariantenprüfung so aussehen:
public final class TimeInterval {
private LocalTime lower, upper;
public TimeInterval(LocalTime l, LocalTime u) {
try {
lower = l;
upper = u;
} finally {
boolean valid = lower!=null && upper!=null
&& (lower.isBefore(upper) || lower.equals(upper));
assert(valid) ;
}
}
public void setLower(LocalTime l) {
boolean valid = lower!=null && upper!=null
&& (lower.isBefore(upper) || lower.equals(upper));
assert(valid) ;
try {
if (l.isBefore(upper)||l.equals(upper)) {
lower = l;
}
} finally {
boolean valid = lower!=null && upper!=null
&& (lower.isBefore(upper) || lower.equals(upper));
assert(valid) ;
}
}
public LocalTime getLower() {
boolean valid = lower!=null && upper!=null
&& (lower.isBefore(upper) || lower.equals(upper));
assert(valid) ;
return lower;
}
public void setUpper(LocalTime u) {
boolean valid = lower!=null && upper!=null
&& (lower.isBefore(upper) || lower.equals(upper));
assert(valid) ;
try {
if (lower.isBefore(u) || lower.equals(u)) {
upper = u;
}
} finally {
boolean valid = lower!=null && upper!=null
&& (lower.isBefore(upper) || lower.equals(upper));
assert(valid) ;
}
}
public LocalTime getUpper() {
boolean valid = lower!=null && upper!=null
&& (lower.isBefore(upper) || lower.equals(upper));
assert(valid) ;
return upper;
}
public boolean contains(LocalTime i) {
boolean valid = lower!=null && upper!=null
&& (lower.isBefore(upper) || lower.equals(upper));
assert(valid) ;
return (lower.isBefore(i)||lower.equals(i)) && (i.isBefore(upper)||i.equals(upper));
}
}
In diesem Beispiel haben wir die Gültigkeitsprüfung
mit Copy-Paste an alle relevanten Stellen kopiert und damit den Source-Code
ziemlich aufgebläht. Eigentlich würde man solche Code-Duplikationen
lieber vermeiden und das werden wir mit Hilfe des Execute-Around-Patterns
auch tun.
Die oben gezeigte Gültigkeitsprüfung ist ein aber nur ein Beispiel für eine Code-Duplikation, die man mit dem Execute-Around-Pattern vermeiden kann. Es gibt zahlreiche andere Situationen, etwa das Anfordern und Freigeben von Ressourcen wie einem Mutex (mit lock() und unlock() ), einer Datei (mit open() und close() ), einer Semaphore (mit acquire () und release () ). Redundanzen können sich auch bei der Fehlerbehandlung ergeben, z.B. wenn identische catch -Klauseln für die immer gleiche Sequenz von Exceptions geschrieben werden müssen. Unsere Gültigkeitsprüfung ist stellvertretend für andere Formen von Redundanzen zu betrachten.
Das Execute-Around-Pattern
public final class Utility {
public static void checkInvariant (BooleanSupplier invariant, Runnable nonRedundantPart) {
invariant.getAsBoolean();
try { nonRedundantPart.run(); }
finally { invariant.getAsBoolean(); }
}
}
Der nicht-redundante Teil wird als
Runnable
übergeben. Die Gültigkeitsprüfung wird vor und nach der Ausführung
des
Runnable
s gemacht. Die Gültigkeitsprüfung
selbst wird als
BooleanSupplier
übergeben.
Man kann die Prüfung auch fest in der Hilfsmethode
checkInvariant()
verdrahten, aber wir haben es flexibel gestaltet.
Der
BooleanSupplier
ist ein funktionales Interface, das wir selbst definiert haben. Es ist
den funktionalen Interfaces im Package
java.util.function
nachempfunden und sieht so aus:
public interface BooleanSupplier {
boolean getAsBoolean();
}
Die
checkInvariant()
-Hilfsmethode
verwenden wir in unserer
TimeInterval
-Klasse
so:
public final class TimeInterval {
private LocalTime lower, upper;
private boolean isValid() {
boolean valid = lower!=null && upper!=null
&& (lower.isBefore(upper) || lower.equals(upper));
assert(valid);
return valid;
}
public void setLower(LocalTime l) {
Utility.checkInvariant(this::isValid,() -> {
if (l.isBefore(upper)||l.equals(upper)) {
lower = l;
}
});
}
public void setUpper(LocalTime u) {
Utility.checkInvariant(this::isValid,() -> {
if (lower.isBefore(u) || lower.equals(u)) {
upper = u;
}
});
}
…
}
Schauen wir uns zunächst einmal die Verwendung
unserer Hilfsmethode in den Setter-Methoden von
TimeInterval
an. Die gesamte Implementierung der jeweiligen Setter-Operation wird
in die
checkInvariant
()
-Hilfsmethode
eingepackt. Um es übersichtlich und lesbar zu gestalten, soll der Wrapper
möglichst knapp und kurz sein. Deshalb haben wir eine private Methode
isValid()
für die
TimeInterval
-Klasse geschrieben;
sie macht die Gültigkeitsprüfung. Eine Referenz auf diese Methode
this::isValid
übergeben wir als erstes Argument an unsere Hilfsmethode
checkInvariant()
.
Das zweite Argument ist ein Lambda-Ausdruck, der den nicht-redundanten
Teil, nämlich die Implementierung der Setter-Methoden, enthält. Der
Rumpf dieses Lambda-Ausdrucks entspricht exakt dem Rumpf der Original-Implementierung
der Setter-Methoden, so wie er war, ehe wir die Invarianten-Prüfung hinzugefügt
hatten.
Unsere Execute-Around-Lösung sieht fast
so aus wie die Original-Implementierung - zuzüglich einer einzigen Zeile,
die für die gewünschte Invarianten-Prüfung sorgt, plus ein paar schließenden
Klammern, die die Lesbarkeit aber nicht beeinträchtigen. Tatsächlich
haben wir jedoch eine zusätzliche Indirektion eingebaut. Was aussieht
wie der Rumpf der Setter-Methode, ist in Wirklichkeit der Rumpf des
BooleanSupplier
,
den wir an unsere Hilfsmethode
checkInvariant()
übergeben. Beim Execute-Around-Pattern wird nicht mehr die eigentliche
Methode implementiert, sondern nur noch ein Lambda-Ausdruck, der an die
Hilfsmethode mit dem redundanten Code übergeben wird. Der Rumpf der
Setter-Methode selbst besteht nur noch aus dem Aufruf der Hilfsmethode.
Diese Art der Nutzung von Lambda-Ausdrücken
ist ein wenig gewöhnungsbedürftig, denn Lambda-Ausdrücke, die im Zusammenhang
mit Execute-Around-Lösungen verwendet werden, sehen anders aus, als Lambda-Ausdrücke,
die an Stream-Operationen (oder andere lambda-fähige APIs) übergeben
werden. Im Zusammenhang mit Streams werden Methodenreferenzen und kurze
Lambdas bevorzugt, die möglichst nicht länger als eine Zeile sein sollten.
Lambda-Ausdrücke im Zusammenhang mit Execute-Around sind dagegen eher
groß und mehrzeilig mit richtigem Rumpf in geschweiften Klammern.
In unserer Execute-Around-Lösung haben wir
beide Lambda-Varianten verwendet. Die Prüfmethode
isValid()
(das erste Argument für unsere
checkInvariant
()
-Hilfsmethode)
haben wir als Methodenreferenz ausgedrückt. An dieser Stelle wollen
wir uns knapp und übersichtlich ausdrücken und möglichst keinen syntaktischen
Overhead erzeugen. Das zweite Argument für die
checkInvariant
()
-Hilfsmethode
ist hingegen ein mehrzeiliger Lambda-Ausdruck mit Rumpf in geschweiften
Klammern. Dieser Lambda-Ausdruck sieht wie eine normale Methodenimplementierung
aus, weil er tatsächlich die ursprüngliche Methodenimplementierung enthält.
Kehren wir zurück zu unserem Ziel, die redundante
Invarianten-Prüfung per Execute-Around-Pattern zu vermeiden. Für die
set()
-Methoden
unserer Klasse funktioniert diese Lösung bereits wunderbar. Der nicht-redundante
Teil der Setter-Methoden passt auf die Signatur von
Runnable
,
weil er keine Argumente nimmt und nichts zurückgibt. Die Gültigkeitsprüfung
wird von der
checkInvariant
()
-Hilfsmethode
vor und nach dem redundanten Teil ausgeführt, genauso wie wir es haben
wollen.
Ein bisschen überraschend ist vielleicht
noch, dass das funktionale Interface für den nicht-redundanten Teil keine
Argument nimmt, obwohl die
set()
-Methode
auf Daten zugreifen muss, nämlich schreibend auf das
lower
-
bzw.
upper
-Feld der
TimeInterval
-Klasse
und lesend auf den neuen Wert, der als Argument an die
set()
-Methode
übergeben wird. Der Zugriff aus dem Lambda-Ausdruck heraus auf die
beiden Felder der Klasse erfolgt direkt, so wie man es auch sonst in jeder
beliebigen Methode der Klasse machen würde. Der Zugriff aus dem Lambda-Ausdruck
heraus auf das Argument der
set()
-Methode
ist möglich, weil das Argument eine lokale Variable ist, die nur gelesen,
aber nicht verändert wird. Die lokale Variable wird also "effectively
final" verwendet und deshalb darf der Lambda-Ausdruck direkt darauf zugreifen.
Für die
set()
-Methoden
unserer Klasse funktioniert unsere Execute-Around-Lösung schon einmal.
Aber für den Konstruktor funktioniert sie nicht, weil die Gültigkeitsprüfung
vor und nach dem nicht-redundanten Teil gemacht wird. Vor der eigentlichen
Konstruktion, also am Anfang des Konstruktors, ist das
TimeInterval
noch nicht in einem gültigen Zustand; es wird ja erst durch den Konstruktor
in den ersten gültigen Zustand versetzt. Im Konstruktor dürfen wir
also nur am Ende prüfen. Das lässt sich leicht beheben, indem wir die
Hilfsmethode überladen und eine zusätzliche Variante mit einem Flag-Argument
hinzufügen:
public final class Utility {
…
public static void checkInvariant(BooleanSupplier invariant, Runnable nonRedundantPart,
boolean checkOnlyOnExit ) {
if (!checkOnlyOnExit) invariant.getAsBoolean();
try { nonRedundantPart.run(); }
finally { invariant.getAsBoolean(); }
}
}
und entsprechend im Konstruktor:
public final class TimeInterval {
…
public TimeInterval(LocalTime l, LocalTime u) {
Utility.checkInvariant(this::isValid,() -> {
lower = l;
upper = u;
}, true );
}
…
}
Aber auch für die
get()
-
und die
contains()
-Methoden unserer
TimeInterval
-Klasse
funktioniert die obige Hilfsmethode nicht. Das liegt daran, dass der
nicht-redundante Teil einer
get()
-Methode
einen Returnwert zurückgeben will. Unsere Hilfsmethode verlangt aber
ein
Runnable
als nicht-redundanten Teil
und ein
Runnable
darf nichts zurückgeben.
Also brauchen wir eine weitere Variante der Hilfsmethode, die anstelle
des
Runnable
s einen funktionalen Interface-Typ
nimmt, dessen Methode einen Rückgabewert hat:
public final class Utility {
…
public static <T> T checkInvariant(BooleanSupplier invariant,
Supplier<?
extends
T>
nonRedundantPart) {
T result = null;
invariant.getAsBoolean();
try { result = nonRedundantPart.get(); }
finally { invariant.getAsBoolean(); }
return result;
}
}
Wir verwenden anstelle eines
Runnable
das vordefinierte funktionale Interface
Supplier
aus dem
java.util.function
-Package des
JDK. Ein
Supplier
darf etwas zurückgeben
und damit funktionieren dann auch die
get()
-
und die
contains()
-Methoden unserer
TimeInterval
-Klasse.
Sie sehen so aus:
public final class TimeInterval {
…
public LocalTime getLower() {
return Utility.checkInvariant(this::isValid,() -> {
return lower;
});
}
public LocalTime getUpper() {
return Utility.checkInvariant(this::isValid,() -> {
return upper;
});
}
public boolean contains(LocalTime i) {
return Utility.checkInvariant(this::isValid,() -> {
return (lower.isBefore(i)||lower.equals(i)) && (i.isBefore(upper)||i.equals(upper));
});
}
}
Exception-Handling
public final class TimeInterval {
private LocalTime lower, upper;
…
public static
class
NoOverlapException extends Exception
{}
private boolean overlapsWith(TimeInterval other) {
TimeInterval first, second;
if (this.lower.isBefore(other.lower)) {
first = this; second = other;
} else {
first = other; second = this;
}
return first.contains(second.lower);
}
public TimeInterval intersectionWith(TimeInterval other,Comparator<? super LocalTime> cmp)
throws NoOverlapException {
return Utility.checkInvariant(()->this.isValid()&&other.isValid(), () -> {
if (!this.overlapsWith(other))
throw new NoOverlapException() ;
return new TimeInterval(TimeInterval.max(this.lower, other.lower,cmp),
TimeInterval.min(this.upper, other.upper,cmp));
});
}
public TimeInterval unionWith(TimeInterval other,Comparator<? super LocalTime> cmp)
throws NoOverlapException {
return Utility.checkInvariant(()->this.isValid()&&other.isValid(), () -> {
if (!this.overlapsWith(other))
throw new NoOverlapException() ;
return new TimeInterval(min(this.lower, other.lower,cmp),
max(this.upper, other.upper,cmp));
});
}
}
In den Methoden
intersectionWith()
und
unionWith()
werden
zwei
TimeInterval
-Objekte verwendet,
this
und
other
. Bisher haben wir in der
checkInvariant()
-Hilfsmethode
immer nur die Invariante vom
this
-Objekt
geprüft. Jetzt wollen wir die Invariante beider Objekte überprüfen.
Das geht nicht mit einer einfachen Methodenreferenz; schließlich wollen
wir nicht eine, sondern zwei Methoden aufrufen, nämlich
this::isValid
und
other::isValid
. Methodenreferenzen
kann man nicht mit dem logischen
&&
-Operator
verknüpfen. Deshalb ist das erste Argument für die
checkInvariant()
-Methode
dieses Mal keine Methodenreferenz, sondern ein Lambda-Ausdruck. Im Rumpf
des Lambda-Ausdrucks rufen wir die beiden Methoden
this::isValid
und
other::isValid
auf
und verknüpfen deren Ergebnisse mit dem
&&
-Operator.
[1]
Leider lassen sich die Methoden
intersectionWith()
und
unionWith()
nicht übersetzen, weil
unsere
checkInvariant()
-Hilfsmethode
als nicht-redundanten Teil nur Funktionalität akzeptiert, die keine (Checked)
Exceptions wirft, denn sowohl die abstrakte Methode von
Runnable
als auch die von
Supplier
sind ohne
throws
-Klausel
deklariert. Also brauchen wir weitere funktionale Interfaces und zusätzliche
Hilfsmethoden, um auch die Fälle mit Checked Exceptions abdecken zu können:
public interface ThrowingSupplier<T,E
extends Exception> {
public T get() throws E;
}
public final class Utility {
…
public static <T, E extends Exception>
T checkInvariant(BooleanSupplier invariant, ThrowingSupplier<T,E> nonRedundantPart)
throws
E {
T
result = null;
invariant.getAsBoolean();
try
{
result = nonRedundantPart.get();
}
finally
{
invariant.getAsBoolean();
}
return
result;
}
}
Bei Bedarf braucht man analog auch noch ein
ThrowingRunnable
Interface und eine dazu gehörige Variante der
checkInvariant()
-Hilfsmethode.
Alternativ kann man auch so vorgehen, wie es im JDK gemacht wird. Keines der funktionalen Interfaces im Package java.util.function lässt Checked Exceptions zu und kein lambda-fähiges API im JDK ( Stream , CompleteableFuture , etc.) akzeptiert Funktionalität, die Checked Exceptions wirft. So hätten wir es theoretisch auch machen können. Dann würden die zusätzlichen Versionen für ThrowingSupplier , ThrowingRunnable , etc. nicht erforderlich und der Benutzer unserer checkInvariant() -Methode müsste dafür sorgen, dass seine nicht-redundante Funktionalität grundsätzlich keine Checked Exceptions wirft. Dazu müsste er seine Lambda-Ausdrücke ggf. mit try - catch -Konstrukten aufblähen und das würde den Sinn und Zweck der Execute-Around-Lösung ad absurdum führen. Für das Execute-Around-Pattern haben wir deshalb Checked Exceptions zugelassen. Im JDK hat man sich bewusst dagegen entschieden, wie man unter /LEA/ nachlesen kann.
Overload Resolution
public final class TimeInterval {
private LocalTime lower, upper;
…
public boolean contains(LocalTime i) {
return Utility.checkInvariant(this::isValid,() -> {
return (lower.isBefore(i)||lower.equals(i)) && (i.isBefore(upper)||i.equals(upper));
});
}
…
}
Der Compiler weiss nicht, ob er in der contains() -Methode die checkInvariant() -Methode mit dem Supplier - oder dem ThrowingSupplier -Argument nehmen soll. Da der nicht-redundante Teil keine Checked Exception wirft, würde beides passen; der Compiler könnte auch die Variante mit dem ThrowingSupplier verwenden, wenn er für den Typparameter E den Typ RuntimeException deduziert.
Er hat die Methode
Boolean checkInvariant(BooleanSupplier invariant,
Supplier< Boolean > nonRedundantPart)
und die Methode
Boolean checkInvariant(BooleanSupplier invariant,
ThrowingSupplier< B oolean ,RuntimeException> nonRedundantPart)
zur Auswahl, weiss nicht mehr weiter und
meldet dann: "
Error: reference to checkInvariant is ambiguous
"
Solche Zweideutigkeiten können auch entstehen,
wenn man einem lambda-fähigen API aus Effizienzgründen weitere Überladung
für primitive Typen hinzufügt. Im Beispiel der
contains
()
-Methode
gibt der nicht redundante Teil einen primitiven
boolean
zurück, der aber per Autoboxing in der in
checkInvariant()
-Methode
als
Boolean
zurückgegeben wird, um dann
per Unboxing wieder in einen primitiven
boolean
verwandelt zu werden. Um das Boxing und Unboxing zu vermeiden, könnte
man der
Utility
-Klasse Varianten mit
Boolean
Supplier
(und
ThrowingBoolean
Supplier
)
hinzufügen. Aber, je mehr überladene Variante man hinzufügt, desto
eher scheitert der Compiler bei der Overload Resolution. Warum ist das
Überladen von Methoden, die Lambda-Ausdrücke als Argumente nehmen, eigentlich
so problematisch?
Es liegt daran, dass der Compiler zwei Dinge
gleichzeitig tun muss. Beim Aufruf einer Methode, die einen Lambda-Ausdruck
als Argument entgegen nimmt und die dann selber noch in mehreren überladenen
Varianten existiert, muss der Compiler nicht nur die richtige überladene
Methode ermitteln (Overload Resolution), sondern er muss auch noch den
Zieltyp für den Lambda-Ausdruck aus dem Kontext deduzieren (Target Type
Deduction). Das ist aufwändig für den Compiler und kann dann eben auch
mal dazu führen, dass der Compiler aufgibt und eine Fehlermeldung macht.
In unserem Falle lösen wir das Overload-Resolution.Problem,
in dem wir auf die Varianten mit
Runnable
und
Supplier
verzichten und Varianten
für primitive Typen gar nicht erst hinzufügen. Wir begnügen uns mit
den Varianten für
ThrowingRunnable
und
ThrowingSupplier
.
Wenn man die
Utility
-Klasse
übersichtlich hält, dann könnte sie so aussehen:
public class Utility {
public static <E extends Exception>
void checkInvariant(BooleanSupplier invariant, ThrowingRunnable<E> nonRedundantPart,
boolean...
checkOnlyOnExit) throws E {
checkInvariant(invariant,
()-> { nonRedundantPart.run(); return (Void)null;},
checkOnlyOnExit);
}
public static <T, E extends Exception>
T checkInvariant(BooleanSupplier invariant, ThrowingSupplier<T,E> nonRedundantPart,
boolean...
checkOnlyOnExit) throws E {
T result = null;
if (checkOnlyOnExit.length>0&&!checkOnlyOnExit[0])
invariant.getAsBoolean();
try { result = nonRedundantPart.get(); }
finally { invariant.getAsBoolean(); }
return result;
}
}
Ganz nebenbei haben wir auch noch die Varianten
mit und ohne Flag für die Gültigkeitsprüfung am Anfang zusammengelegt,
indem wir das Flag als Varargs-Parameter übergeben. Dann kann man es
angeben oder aber auch weglassen und wir brauchen nur noch eine Methode
für beide Fälle. Das ist nicht ganz die Art von Verwendung, für die
die variablen Argumente gedacht sind, weil wir nicht beliebig viele Argument
akzeptieren wollen, sondern nur 0 oder 1 Argument. Es ist daher Geschmacksache,
ob man diese Lösung mag oder dann lieber doch Überladungen mit und ohne
Flag anbietet.
Wir haben das Overload-Resolution-Problem
durch Verzicht auf diverse überladene Varianten gelöst. Alternativ
hätten wir es auch so lösen können, wie es im JDK gemacht wird. Dort
wird im Zweifelsfall auf die Überladung verzichtet und die verschieden
Varianten der Methode haben unterschiedliche Namen. Das sieht man zum
Beispiel bei der
map()
-Operation der
Streams. Ein
Stream<T>
hat eine
map()
-Methode,
die einen Referenz-Stream vom Typ
Stream<R>
zurückgibt, und zusätzlich Methoden
mapToInt()
,
mapToLong()
und
mapToDouble()
,
die einen primitiven
Int
-,
Long
-
bzw.
DoubleStream
zurückgeben.
Wildcards in lambda-fähigen Schnittstellen
public final class TimeInterval
<T
extends
Temporal>
{
private T lower, upper;
public TimeInterval(T l, T u) {
Utility.checkInvariant(this::isValid,() -> {
lower = l;
upper = u;
},true);
}
public void setLower(T l) {
Utility.checkInvariant(this::isValid,() -> {
if (invokeIsBefore(l,upper)||l.equals(upper))
{ lower = l; }
});
}
public T getLower() {
return Utility.checkInvariant(this::isValid,()->lower);
}
… etc. …
}
Dabei ist
Temporal
der Supertyp von
LocalDate
,
LocalTime
,
LocalDateTime
,
ZonedDateTime
,
etc. Damit kann man jetzt Intervalle wie die folgenden erzeugen:
// [09:00,10:00]
TimeInterval<LocalTime> meeting
= new TimeInterval<>(LocalTime.of(9, 0),LocalTime.of(10,0));
// [2015-07-27,2016-01-01]
TimeInterval<LocalDate> restOfYearInDays
= new TimeInterval<>(LocalDate.now(),LocalDate.of(LocalDate.now().getYear()+1,1,1));
Nehmen wir an, die
TimeInterval
-Klasse
hätte eine Methode für die Konvertierung von einem Typ von Zeitintervall
in einen anderen Typ von Zeitintervall:
public final class TimeInterval<T extends Temporal>
{
private T lower, upper;
…
public <S extends Temporal>
TimeInterval<S>
convert
(
Function<T,
S
>
converter
) {
return new TimeInterval<S>(converter.apply(lower),converter.apply(upper));
}
}
Mit dieser Methode könnte man aus einem
Intervall wie "9:00 Uhr bis 10:00 Uhr" (ohne bestimmte Tagesangabe) ein
Intervall mit Tagesangabe machen, also z.B. "heute von 9:00 Uhr bis 10:00
Uhr".
// [09:00, 10:00]
TimeInterval<LocalTime> meeting
= new TimeInterval<>(LocalTime.of(9, 0),LocalTime.of(10,0));
// [2015-07-27T09:00, 2015-07-27T10:00]
TimeInterval<LocalDateTime> todaysMeeting
= meeting.convert(time->LocalDateTime.of(LocalDate.now(),time));
Die
convert()
-Methode
nimmt Funktionalität als Argument, die beschrieben ist durch das funktionale
Interface
Function
aus dem Package
java.util.function
des JDK. Es sieht so aus:
public interface Function<A, R> {
R apply(A t);
}
Ebenso wie alle anderen vordefinierten funktionalen
Interfaces aus dem Package
java.util.function
des JDK ist
Function
ein generischer
Typ. Er hat zwei Typparameter:
A
ist
der Argumenttyp und
R
ist der Returntyp.
Wir haben in der Deklaration der
convert()
-Methode
eine Parametrisierung von
Function
ohne
Wildcards verwendet, nämlich
Function<T,S>
.
Das sieht zwar auf den ersten Blick überzeugend aus, ist aber falsch.
Warum ist es falsch? Schauen wir uns das obige Beispiel noch einmal genauer
an:
// [09:00, 10:00]
TimeInterval<LocalTime> meeting = new TimeInterval<>(LocalTime.of(9,
0),LocalTime.of(10,0));
Function<LocalTime,LocalDateTime>
converter = time->LocalDateTime.of(LocalDate.now(),time);
// [2015-07-27T09:00, 2015-07-27T10:00]
TimeInterval<LocalDateTime> todaysMeeting = meeting.convert(converter);
Die Konvertierungsfunktionalität, die wir
der
convert()
-Methode übergeben, muss
aus einem
LocalTime
-Objekt ein
LocalDateTime
-Objekt
machen. Der Typ des Konverters ist
Function<LocalTime,LocalDateTime>
.
Soweit funktioniert es. Wenn aber die Situation ein wenig anders ist,
funktioniert es nicht mehr. Zum Beispiel könnte es sein, dass wir das
Ergebnis der Konvertierung nicht einer Variablen vom Typ
TimeInterval<LocalDateTime>
sondern einer Variablen vom Typ
TimeInterval<Temporal>
zuweisen (oder einer Methode mit diesem Argumenttyp übergeben) wollen.
Das geht aber mit unserer Deklaration von
convert()
nicht:
Function<LocalTime,LocalDateTime> converter = time->LocalDateTime.of(LocalDate.now(),time);
TimeInterval<
Temporal
>
todaysMeeting = meeting.convert(converter); // error
Für diese Zuweisung würden wir einen Konverter
vom Typ
Function<LocalTime,Temporal>
benötigen,
obwohl
Temporal
der Supertyp von
LocalDateTime
ist und der Konverter ein
LocalDateTime
-Objekt
produziert, dass insbesondere ein
Temporal
-Objekt
ist. Eigentlich würde man erwarten, dass ein Konverter vom Typ
Function<LocalTime,LocalDateTime>
benutzt werden kann, um ein
TimeInterval<Temporal>
zu erzeugen. Wenn wir das erreichen wollen, müssen wir die
convert()
-Methode
anders deklarieren, nämlich so:
public <S extends Temporal>
TimeInterval<S> convert(Function<T, ? extends S> converter) {
return new TimeInterval<S>(converter.apply(lower),converter.apply(upper));
}
Jetzt wird nur noch ein Konverter verlangt,
der
S
oder einen Subtyp von
S
erzeugt, d.h. wir können einen Konverter vom Typ
<LocalTime,LocalDateTime>
verwenden, um ein
TimeInterval<Temporal>
zu erzeugen.
Ähnliches gilt für den Typparameter
T
.
Auch er ist zu restriktiv und sollte durch ein Wildcard ersetzt werden.
Beispielsweise können wir keinen Konverter vom Typ
Function<Temporal,LocalDateTime>
verwenden für die Konvertierung von einem
LocalTime
-Interval
in ein
LocalDateTime
-Interval.
Die
apply()
-Methode
eines
Konverters
vom Typ
Function<Temporal,LocalDateTime>
würde
zwar ein Argument vom Typ
Temporal
akzeptieren und damit auch jedes Objekt von einem Subtyp von
Temporal
;
also könnten wir problemlos ein
LocalDate
an den Konverter übergeben. Aber unsere restriktive Deklaration der
convert()
-Methode
lässt es nicht zu. Sie verlangt
einen
Konverter vom Typ Function
<L
ocalTime,LocalDateTime>
.
Auch
diese Restriktion lässt sich durch eine Wildcard-Parametrisierung lösen,
so dass die korrekte Deklaration der
convert()
-Methode
letzendlich
so
aussehen
muss
:
public <S extends Temporal>
TimeInterval<S> convert(Function< ? super T, ? extends S> converter) {
return new TimeInterval<S>(converter.apply(lower),converter.apply(upper));
}
Da funktionale Interface häufig generisch
sind, muss man beim Design einer lambda-fähigen Schnittstelle darauf achten,
dass unter Umständen Wildcard-Parametrisierungen als Argumenttypen deklariert
werden müssen. Die Regel dafür ist einfach:
Input-Parameter sind kontravariant, d.h. man muss ein "? super"-Wildcard verwenden und
Output-Parameter sind kovariant, d.h. man muss eine "? extends"-Wildcard
verwenden.
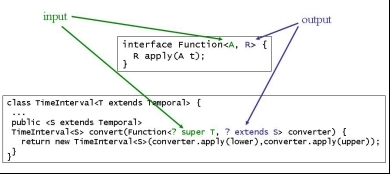
Bei den Methoden unserer
Utility
-Klasse
wurden keine Wildcard-Parametrisierungen als Argumenttypen gebraucht, weil
die Methoden nur "normale" (und keine generischen) Returntypen hatten.
Aber sobald eine lambda-fähige Schnittstelle mit Input- und Output-Objekten
von generischem Typ arbeitet, sind Wildcard-Parametrisierung häufig nötig,
wie im Beispiel unserer
convert()
-Methode,
die ein
TimeInterval<T>
in ein
TimeInterval<S>
verwandelt. Ein instruktives Beispiel sind auch die Streams im JDK; viele
Stream-Methoden verwandeln einen Input-Stream vom Typ
Stream<A>
in einen Output-Stream vom Type
Stream<B>
und verwenden dafür Funktionalität, die durch eine Wildcard-Parametrisierung
eines vordefinierten funktionalen Interfaces beschrieben ist. Hier einige
Beispiele:
interface Stream<T> {
Stream<T> filter(Predicate< ? super T> predicate)
<R> Stream<R> map(Function< ? super T, ? extends R> mapper)
Optional<T> max(Comparator< ? super T> comparator)
...
}
Wie man sieht, kommt es relativ häufig vor, dass die Argumenttypen von Methoden, die Lambda-Ausdrücke entgegen nehmen, als Wildcard-Parametrisierung ausgedrückt werden müssen. Leider sieht man immer wieder Beispiele, wo genau das falsch gemacht wird und die lambda-fahige Schnittstelle restriktiver ist, als sie korrekterweise sein sollte.
Nicht-Statische Methoden in Funktionalen Interfaces
public interface BooleanSupplier {
boolean getAsBoolean();
}
Wenn man für solche funktionalen Interfaces
nicht-statische Methoden definiert, dann ist die Verwendung dieser Methoden
für den Benutzer gelegentlich unerfreulich. Betrachten wir ein Beispiel.
Nehmen wir an, wir wollen dem
BooleanSupplier
-Interface
Methoden
and()
,
or()
und
negate()
hinzufügen, damit man zwei
BooleanSupplier
kombinieren kann oder aus einem
BooleanSupplier
einen neuen mit dem negierten Ergebnis machen kann. Das könnte so aussehen:
public interface BooleanSupplier {
boolean getAsBoolean();
default BooleanSupplier and(BooleanSupplier other) {
return () -> this.getAsBoolean() && other.getAsBoolean();
}
default BooleanSupplier or(BooleanSupplier other) {
return () -> this.getAsBoolean() || other.getAsBoolean();
}
default BooleanSupplier negate() {
return () -> ! this.getAsBoolean();
}
}
Eigentlich ist die Idee gut. Man könnte
beispielsweise die
and()
-Methode verwenden,
um die Gültigkeitsprüfung in den Methoden
unionWith()
und
intersectionWith()
übersichtlicher
zu gestalten. Es werden
this
und
other
auf Gültigkeit geprüft und wir haben für diese kombinierte Prüfung
einen Lambda-Ausdruck verwendet.
Vorher:
public final class TimeInterval {
…
public TimeInterval unionWith(TimeInterval other,Comparator<? super LocalTime> cmp)
throws NoOverlapException {
return Utility.checkInvariant( ()->this.isValid()&&other.isValid() , () -> {
if (!this.overlapsWith(other))
throw new NoOverlapException();
return new TimeInterval(min(this.lower, other.lower,cmp),
max(this.upper, other.upper,cmp));
});
}
}
Mit der
and()
-Methode
des
BooleanSupplier
-Interfaces könnte
man jetzt Methodenreferenzen verwenden, die ja oft übersichtlicher und
lesbarer sind. Wir würden es gerne so machen - nur leider geht es nicht.
Nachher (Wunschvorstellung):
public final class TimeInterval {
…
public TimeInterval unionWith(TimeInterval other,Comparator<? super LocalTime> cmp)
throws NoOverlapException {
return Utility.checkInvariant( this:: isValid . and (other::isValid ) , () -> { // error
if (!this.overlapsWith(other))
throw new NoOverlapException();
return new TimeInterval(min(this.lower, other.lower,cmp),
max(this.upper, other.upper,cmp));
});
}
}
Der Compiler meldet einen Fehler zu unserer
Kombination der beiden Methodenreferenzen, denn er akzeptiert keine Methodenreferenzen
als Receiver-Objekt für einen Methodenaufruf. Das gleiche gilt für
Lambda-Ausdrücke. Das Konstrukt
(()->this.isValid()).and(()->other.isValid())
weist er ebenfalls als Fehler zurück.
Der Grund für die Fehlermeldung ist die
Tatsache, dass Lambda-Ausdrücke und Methodenreferenzen nicht als sogenannte
Receiver
-Objekte
verwendet werden können. Als Receiver-Objekt wird der Ausdruck bezeichnet,
der auf der linken Seite vom
'.'
bei
einem Methodenaufruf steht; d.h. der Receiver ist das Objekt, auf dem eine
nicht-statische Methode aufgerufen wird. Dieser Receiver-Kontext ist
laut Sprachspezifikation /JLS8/ kein Deduktionskontext, aus dem der Compiler
den Zieltyp für einen Lambda-Ausdruck oder eine Methodenreferenz herleiten
könnte. Deshalb dürfen Lambda-Ausdrücke und Methodenreferenzen an
genau dieser Stelle nicht vorkommen. Bei nicht-statischen Methoden von
funktionalen Interfaces ist aber genau das die naheliegende Art der Verwendung.
Das bedeutet, dass nicht-statische Methoden in funktionalen Interfaces
nicht so angenehm zu benutzen sind, wie es auf den ersten Blick scheinen
mag.
In unserem obigen Beispiel müssen wir einen
Cast einfügen, damit wir die
and()
-Methode
benutzen können. Das sieht dann so aus:
public final class TimeInterval {
…
public TimeInterval unionWith(TimeInterval other,Comparator<? super LocalTime> cmp)
throws NoOverlapException {
return Utility.checkInvariant( ( (BooleanSupplier) this::isValid).and(other::isValid) , () -> {
if (!this.overlapsWith(other))
throw new NoOverlapException();
return new TimeInterval(min(this.lower, other.lower,cmp),
max(this.upper, other.upper,cmp));
});
}
}
Wir könnten auch eine lokale Variable vom Typ BooleanSupplier verwenden, der wir die Methodenreferenz this::isValid zuweisen, und dann die Variable als Receiver-Objekt verwenden. Wichtig ist nur, dass der Compiler den Zieltyp für das Receiver-Objekt nicht selber deduzieren muss, sondern bereits vorfindet (im Cast oder in der Variablendeklaration). Egal, wie man sich behilft, sowohl der Cast als auch die zusätzliche Variable beeinträchtigen die Lesbarkeit, so dass letztlich der Lambda-Ausdruck ohne die Verwendung der and() -Methode die schönere Lösung ist.
Zusammenfassung
Nicht-statische Methoden in funktionalen Interfaces sind nicht so angenehm zu benutzen, wie man es sich wünschen würde. Deshalb sollte man gut überlegen, ob und wann sie als Bestandteil der Schnittstelle sinnvoll sind.
Literaturverweise
| /KRE1/ |
Klaus Kreft & Angelika Langer
Funktionale Programmierung in Java, Java Magazin, September 2013 URL: http://www. AngelikaLanger.com/Articles/EffectiveJava/70.Java8.FunctionalProg/70.Java8.FunctionalProg.html |
| /EAM1/ |
Frank Buschmann, Kevlin Henney, Douglas C. Schmidt
Pattern-Oriented Software Architecture, Wiley, 2007 |
| /EAM2/ |
The Pattern Almanac by Linda Rising
Addison-Wesley, 2000 |
| /JLS8/ | Java Language Specification, section 15.27.3 "Type of a Lambda Expression" |
|
Design
by Contract - Eiffel
|
|
| /LAN/ |
Klaus Kreft & Angelika Langer
Die Artikelserie "Effective Java" URL: http://www.angelikalanger.com/Articles/EffectiveJava.html |
|
Mixing Checked Exceptions and Lambdas Is Too Nightmarish, Doug Lea
URL: http://cs.oswego.edu/pipermail/concurrency-interest/2012-December/010486.html |
![]()
Die gesamte Serie über Java 8:
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
|||||||||||||
Seminar
|
Related Reading
|
||||||||||||