| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java 8
Parallel Streams
Java Magazin, July 2015
|
Dies ist die Überarbeitung eines Manuskripts für einen Artikel, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Wir haben uns bereits in vorhergehenden Artikeln (/ KLS1 / bis / KLS4 /) mit der grundlegenden Funktionalität von Java 8 Streams beschäftigt. In diesem und den folgenden Artikeln wollen wir noch einmal zu den Streams zurückkehren und uns diesmal die fortgeschritteneren Themen ansehen. Beginnen wollen wir heute mit den parallelen Streams.
Sequentielle und Parallele Streams
Die grundsätzliche Idee ist, dass sequentielle
Streams ihre Funktionaliät sequentiell in einem einzigen Thread ausführen,
während parallele Steams dies parallel mit mehreren Threads machen.
Schauen wir uns dazu ein Beispiel an. Nehmen wir an,
ints
ist ein großes
int
-Array, in dem wir
das größte Element suchen wollen. Mit einem sequentiellen Stream geht
dies so:
int max = Arrays.stream(ints).reduce(Integer.MIN_VALUE,
Math::max);
Mit einem parallelen Stream so:
int max = Arrays.stream(ints)
.parallel
()
.reduce(Integer.MIN_VALUE,
Math::max);
Beim sequentiellen Stream sucht ein einziger
Thread das größte Element, beim parallelen Streams sind es (im Default-Fall
auf einer Multi-Core-Plattform) soviele Threads, wie es CPU-Cores auf der
unterliegenden Plattform gibt. Weitere Details zur parallelen Verarbeitung
sehen wir weiter unten an. Die grundsätzliche Erwartung ist, dass durch
die Nutzung mehrer parallel arbeitender Threads der parallele Stream mit
seiner Arbeit schneller fertig wird als der sequentielle und damit die
Performance unseres Java-Programms verbessert wird.
Aus JDK-Benutzersicht ist die Nutzung paralleler
Streams ziemlich einfach. Im Fall von Arrays (unser Beispiel oben) wird
der zusätzliche Aufruf der Stream-Methode
parallel()
benötigt. Bei Collections ruft man bei der Stream-Erzeugung auf dem
Collection-Objekt statt
stream()
die
Methdode
parallelSt
r
eam()
auf (siehe auch /
KLS2
/). Das heißt mit einem sequentiellen
Stream suchen wir das größte Element in einer
intList
(vom Typ
List
) so:
int max = intList.stream().reduce(Integer.MIN_VALUE,
Math::max);
Und mit einem parallelen Stream so:
int max = intList
.parallel
Stream()
.reduce(Integer.MIN_VALUE,
Math::max);
Sonst ändert sich für den JDK-Benutzer
im Wesentlichen nichts. In beiden Fällen ist der statische Stream-Typ,
auf dem man dann die weitere Stream-Funktionalität aufruft, der gleiche
nämlich
java.util.Stream
(und in dem
Beispiel mit dem
int
-Array weiter oben:
java.util.IntStream
).
Das heißt, es gibt keine unterschiedlichen Typen für sequentielle und
parallele Funktionalität. Es gibt nur einen Stream Typ, der beide Möglichkeiten
anbietet. Dies zeigt sich dann auch bei den Anforderungen an Parameter
von Stream-Operationen bzw. bei den Zusicherungen, an Ergebnisse von Stream-Operationen,
die in der Javadoc von
java.util.St
r
eam
beschrieben sind. Es gibt im Allgemeinen nur eine Beschreibung, die für
beide Streams, parallel und sequentiell, gilt. Das läuft dann in der
Praxis darauf hinaus, dass die strengeren Anforderungen und die schwächeren
Zusicherungen, die sich aus der parallelen Verarbeitung ergeben, beschrieben
sind. Die Idee dahinter ist, dass weder der sequentieller noch der paralleler
Stream ein Sonderfall ist, sondern dass beide gleich zu behandeln sind.
Der Vorteil dieses Ansatzes ist, dass es relativ einfach ist, statt eines
sequentiellen Streams einen parallelen zu nutzen, und umgekehrt.
Leider lässt sich dieser Ansatz sequentielle-und-parallele-Streams-sind-gleich-zu-behandeln
nicht immer und überall umsetzen. Ein gewisses Maß an Pragmatismus
vorausgesetzt, kann man in Situationen kommen, wo man (z.B. aus Performancegründen)
dann doch zwischen sequentieller und paralleler Verarbeitung unterscheiden
möchte. Auch die JDK 8 Entwickler haben dies so gesehen. So wird zum
Beispiel in einigen Ausnahmefällen explizit ein unterschiedliches Verhalten
von sequentiellen und parallelen Streams beschrieben. Die
forEach()
Stream-Methode ist ein Beispiel dafür: „
For parallel stream pipelines,
this operation does
not
guarantee to respect the encounter order of the stream, as doing so would
sacrifice the benefit of parallelism. (…) If the action accesses shared
state, it is responsible for providing the required synchronization. (/
STFE
/)”
Als Benutzer eines Stream-Objekts kann man
mit Hilfe der Stream-Methode
isParallel()
zur Laufzeit prüfen, ob es sich um einen sequentiellen oder parallelen
Stream handelt, am Typ kann man es ja (wie oben diskutiert) nicht erkennen.
Dies ermöglicht dann in Ausnahmefälle Code zu schreiben, der explizit
eine Fallunterscheidung für sequentielle und parallele Streams macht.
Schauen wir uns dazu ein Beispiel an. Nehmen wir an, wir haben die
Wartung für folgenden Code übernommen:
public static void logStream(Stream<String> str)
{ str.forEach(System.out::println); }
Die Idee ist, dass die Methode
logStream
()
einen
Stream<String>
übergeben bekommt
und die
String
-Elemente des Streams zeilenweise
loggt. In diesem Beispiel heißt "loggen" einfach "auf STDOUT schreiben"
(weil wir uns die Diskussion über das beste Java Logging-API hier ersparen
wollen). An diesem Code wird nun bemängelt, dass es bei seiner Ausführung
immer wieder vorkommt, dass die Reihenfolge der Ausgabezeilen nicht stimmt.
Wenn wir uns noch mal oben die zitierte Javadoc
von
forEach()
ansehen, können wir bereits
ahnen, wo das Problem herkommt. Wenn ein paralleler Stream an
logStream
()
übergeben wird, kann es vorkommen, dass die Elemente nicht in der richtigen
Reihenfolge ausgegeben werden („
does
not
guarantee to respect the encounter order of the stream“
).
Damit auch bei parallelen Streams die Reihenfolge
eingehalten wird, stellt der Stream die Methode
forEachOrdered()
zur Verfügung. Ein erster Versuch, den Fehler zu beheben, ist folgender
Code:
public static void logStream(Stream<String> str) {
if (!str.isParallel())
str.forEach(System.out::println);
else
str.forEachOrdered(System.out::println);
}
Wir nutzen das oben bereits besprochene
isParallel()
,
um zu prüfen, ob es sich um einen parallelen Stream handelt, und wenn
nicht, rufen wir wie vorher
forEach()
auf und sonst
forEachOrdered()
. Funktional
lässt sich gegen diese Lösung nichts sagen. Sie hält immer die Reihenfolge
ein, egal, ob es sich um einen sequentiellen oder parallelen Stream handelt.
Konzeptionell ist die Lösung aber nicht gut, weil wir das
isParallel()
unnötigerweise nutzten. Für sequentielle Streams verhält sich
forEachOrdered()
nämlich genauso wie
forEach()
. Das heißt
die Fallunterscheidung ist überflüssig und wir können immer
forEachOrdered()
verwenden:
public static void logStream(Stream<String> str)
{ str.forEachOrdered(System.out::println); }
Das Beispiel hat das bisher Gesagte noch einmal zusammengefasst: Grundsätzlich sollte man mit Streams so programmieren, dass die angewandte Funktionalität sowohl bei sequentiellen wie auch bei parallelen Streams fehlerfrei funktioniert. Dies stellt sicher, dass ein Wechsel von sequentiell zu parallel bzw. umgekehrt möglich ist. In begründeten Ausnahmefällen kann man von dieser Regel abweichen. Man sollte sich dann aber sicher sein, dass es wirklich nötig ist.
Wie parallele Streams funktionieren
Da dies ein wenig abstrakt klingt, schauen wir uns an, wie unser Anfangsbeispiel:
int max = Arrays.stream(ints)
.parallel
()
.reduce(Integer.MIN_VALUE,
Math::max);
von einem parallelen Stream verarbeitet wird.
Nehmen wir dazu an, das
int
-Array
ints
habe die Größe 64, also Index 0 … 63.
Das Ausgangsproblem besteht darin, das größte
Element im Indexbereich 0 … 63 zu finden. Beim ersten Fork wird der
Indexbereich in zwei Teilbereiche aufgeteilt: 0 … 31 und 32 … 63.
Die damit entstandenen zwei Teilprobleme sind nun: größtes Element finden
im Indexbereich 0 … 31 und im Indexbereich 32 … 63. Diese Teilprobleme
lassen sich wieder durch halbieren der Indexbereiche in neue Teilprobleme
zerlegen: größtes Element von 0 … 15, 16 … 31, 32 … 47 und 48 …
63. Die gerade beschriebene Zerlegung sieht man auf der linken Seite
von Abbildung 1.
Entscheidend ist nun, dass die vier Teilprobleme
in der Ausführungsphase unabhängig voneinander durch je einen parallelen
Thread gelöst werden können, in dem wir die Funktionalität, die im
reduce()
übergeben wurde (
Math::max
), zusammen mit
dem Anfangswert
Integer.MIN_VALUE
auf
jeden der vier Teilbereiche anwenden. Damit lassen sich alle vier CPU-Cores
einer Quad-Core-Plattform nutzen. Diese parallele Verarbeitung war mit
unserem Ausgangsproblem, bei dem wir sequentiell das größte Element im
gesamten Array gesucht haben, nicht möglich. In der Ausführungsphase
erhalten wir nun das größte Element im ersten Viertel (0 … 15), zweiten
Viertel (16 … 31), dritten Viertel (32 … 47) und vierten Viertel (48
… 63) unseres Arrays.
Jetzt kommt die Join-Phase. Die Ergebnisse
der Teilprobleme werden nun zusammengefasst. Dies erfolgt in umgekehrter
Reihenfolge zur Zerlegung in der Forkphase. Im ersten Schritt werden
die Ergebnisse des ersten und zweiten Viertels zu einem Ergebnis für die
erste Hälfte (0 … 31) zusammengefasst. Dies geschieht, indem auf
die beiden Teilergebnisse die im
reduce()
übergebene Funktinonalität (
Math::max
) angewandt
wird. Das größere von beiden Teilergebnissen ist dann das Ergebnis
der ersten Hälfte. Parallel dazu wird in ähnlicher Weise das Ergebnis
für die zweite Hälfte (32 … 63) ermittelt. Nun wird noch mal das
Math::max
auf die beiden Teilergebnisse für die erste und die zweite Hälfte angewandt
und so das Ergebnis für das gesamte Array (0 … 63) ermittelt. Alle
Arbeitsschritte sind noch einmal in "Abbildung 1: Fork-Join-Verarbeitung"
grafisch dargestellt.
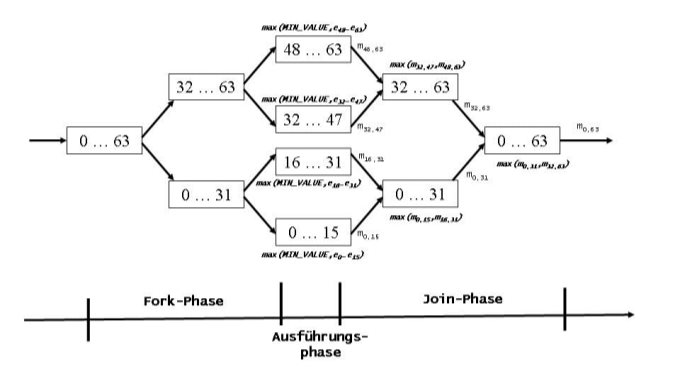
Abbildung 1: Fork-Join-Verarbeitung
Durch die Benutzung des Fork-Join-Frameworks können sich mehrere Threads und damit mehrere CPU-Cores parallel an der Bearbeitung der Stream-Operationen beteiligen. Die parallele Verarbeitung erfolgt dabei in der Fork-, der Join- und ganz besonders in der Ausführungsphase. Dabei ist die Parallelität sogar noch etwas feinganularer als oben dargestellt. Es werden so viele Fork-Stufen durchgeführt, dass in der Ausführungsphase ungefähr (4 * Anzahl der CPU-Cores)-viele Teilprobleme zu bearbeiten sind. (Genauer gesprochen ist die Zahl der Teilprobleme die Zweierpotenz, die größer als 4*(N-1) ist, wobei N die Zahl der CPU-Cores ist.) In unserer Beschreibung oben hatten wir nur vier Teilprobleme. Bei einem echten Ablauf auf einem Quad-Core-Rechner sind es aber in Wirklichkeit 16 Teilprobleme. Das heißt, wir haben dann vier Fork-, bzw. Joinschritte, statt nur zwei wie in unserem Beispiel oben. Wir haben die Beschreibung bewusst etwas verkürzt, da die Funktionalität in den einzelnen Fork-Join-Stufen ja jedes Mal die gleiche ist.
Intermediäre Operationen und parallele Streams
int max = Arrays.stream(strings) .parallel ()
.mapToInt(String::length)
.reduce(Integer.MIN_VALUE,
Math::max);
Wo wird das intermediäre Mapping auf die Länge des String s im Rahmen des Fork-Joins ausgeführt? Dies erfolgt in der Ausführungsphase. Jedes parallele Teilproblem wird auf seinem Indexbereich so abgearbeitet wie ein sequentieller Stream auf dem gesamten Indesbereich. Das heißt, jeder String im Indexbereich wird erst auf seine Länge abgebildet ( map ToInt () ) und dann wird geprüft, ob diese Länge größer ist als das bisherige Maximum für diesen Indexbereich ( reduce() mit Math::max ). Die intermediäre mapToInt() -Operation wird also in der Ausführungsphase parallel in allen Teilproblemen angewandt.
Terminale Operationen und parallele Streams
CommonPool
Der erste beteiligte Thread ist der Thread,
der die terminale Operation auf dem parallelen Stream aufruft. Also in
unserem Beispiel ist es der Thread, der das Statement:
int max = Arrays.stream(ints)
.parallel
()
.reduce(Integer.MIN_VALUE,
Math::max);
ausführt. Unterstützt wird er von zusätzlichen Threads aus dem
CommonPool.
Der CommonPool ist eine mit Java 8 eingeführte
ForkJoinPool
–Instanz
im JDK, die als Singleton implementiert ist. Zugriff auf diesen Pool
erhält man über die statische Methode
java.util.concurrent.F
orkJoinPool.commonPool()
.
Bei der Verwendung von parallelen Streams braucht man diesen expliziten
Zugriff aber gar nicht, da jede parallele Stream-Instanz den CommonPool
von sich aus implizit nutzt.
Die Parallelität (Englisch: parallelism ) des CommonPool ist im Default-Fall auf einer Mulit-Core-Plattform gleich der (Anzahl der CPU-Cores – 1) und auf einer Single-Core-Plattform 1. Dabei ist die Anzahl der Cores der Wert, der bei java.lang.Runtime.availableProcessors() zurückkommt. Dies ist die Anzahl der virtuellen Cores der Plattform und nicht der physikalischen.
Alternativ lässt sich die Parallelität
des CommonPool explizit mit Hilfe der System-Property
java.util.concurrent.ForkJoinPool.common.parallelism
festlegen (siehe /
JFJP
/).
Die Parallelität des CommonPools entspricht im Wesentlichen der Anzahl der Poolthreads des Pools. Dies gilt aber nicht in allen Situationen. So beendet der CommonPool bei Inaktivität sukzessive seine Threads und startet neue, wenn wieder Aufgaben an ihn übergeben werden. In solchen Situationen kann die Anzahl der Poolthreads kleiner sein als seine Parallelität. Zum anderen hat der ForkJoinPool unter gewissen Umständen ( ForkJoinPool.ManagedBlocker ) die Fähigkeit, wartende (Englisch: blocking ) Poolthreads durch Erzeugen neuer Poolthreads zu kompensieren. In einer solchen Situation kann die Anzahl seiner Poolthreads dann höher sein als seine Parallelität. Wir schauen uns das Feature mit dem Erzeugen zusätzlicher neuer Threads in einem zukünftigen Artikel über parallele Streams und wartende Funktionalität noch genauer an.
Spliterator
Das Interface
java.util.Spliterator
ist neu in Java 8. Wie der Name
Spliterator
= Splitter + Iterator schon sagt, stellt das
Spliterator
-Interface
die Funktionalität zur Verfügung, um eine Stream-Source zu teilen und
um zu iterieren. Beides wird von der Stream-Implementierung bei der parallelen
Verarbeitung genutzt: das Teilen in der Fork-Phase und das Iterieren in
der Ausführungsphase. Bei einem sequentiellen Stream nutzt die Stream-Implementierung
nur das Iterieren.
Jeder Stream-Source-Typ besitzt seine spezifische
Spliterator
-Implementierung.
Diese Implementierung weiss, wie sie ihre Stream-Source teilt und iteriert.
Für eine
ArrayList
ist die spezifische
Spliterator
-Implementierung
die private eingeschachtelte (Englisch:
nested
) Klasse
ArrayListSpliterator
.
Das heißt, im Rahmen des JDK 8 sind für alle Stream-Sourcen
Spliterator
-Implementierungen
neu dazugekommen. Da es sich dabei aber zumeist um private Klassen in
dem Stream-Source-Typ handelt, sind diese Erweiterungen nicht besonders
aufgefallen.
Das
Spliterator
-Interface
ist aber nicht nur eine wichtige interne Schnittstelle im JDK. Es ist
auch der Erweiterungspunkt (Englisch:
extension point
), wenn man
eigene Abstraktionen als Stream-Sourcen nutzen möchte. Dann muss man
nämlich für die eigenen Abstraktionen das
Spliterator
-Interface
implementieren.
Ein wenig Unterstützung gibt es dafür schon
in der Klasse
java.util.Spliterators
.
So findet man unter anderem eine eingeschachtelte Klasse
AbstractSpliterator
,
die man als Basis-Klasse für eigene
Spliterator
-Implementierung
nutzen kann. Zusätzlich gibt es auch eine Factory-Methode, die es erlaubt,
aus einem
Iterator
einen
Spliterator
zu erzeugen. Eine Warnung dazu: die Performance des so erzeugten
Spliterator
s
in Kombination mit parallelen Streams ist meist schlechter als eine
Spliterator
-Implementierung,
bei der man das Teilen explizit selbst implementiert hat.
Hat man dann die
Spliterator
-Implementierung
für die eigene Abstraktion erstellt, so kann man mit der Factory-Methode
public static <T> Stream<T> stream(Spliterator<T>
spliterator, boolean parallel)
aus der Klasse java.util.stream.StreamSupport einen Stream mit der eigenen Abstraktion als Stream-Source erzeugen. Der erste Parameter der stream() -Factory-Method ist eine Instanz des eigenen Spliterator s, die mit der Stream-Source assoziiert ist. Der zweite Parameter gibt an, ob der erzeugte Stream parallel oder sequentiell sein soll.
Zusammenfassung und Ausblick
Den Wechsel von einem sequentiellen zu einem parallelen Stream wird man im Allgemeinen zur Performancesteigerung in Betracht ziehen. Welche Regeln man dabei gelten und welche Steigerungsraten man erwarten kann, schauen wir uns beim nächsten Mal an.
Literaturverweise
![]()
Die gesamte Serie über Java 8:
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
|||||||||||||
Seminar
|
Related Reading
|
||||||||||||