| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java 8
CompletableFuture
Java Magazin, März 2015
|
Dies ist die Überarbeitung eines Manuskripts für einen Artikel, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Wir setzen
unsere Reihe zum Thema Java 8 Neuerungen diesmal mit dem
CompletableFuture
fort. Das
CompletableFuture
überträgt
den Progammierstil des
Fluent Programming
, den wir uns bereits bei
den Streams angesehen haben, auf das Behandeln asynchroner Ergebnisse.
Schauen wir uns aber zuerst an, welche Möglichkeiten es im JDK bisher
für das Behandeln asynchroner Ergebnisse gab.
Ein kurzer Rückblick
ExecutorService pool = ...
Future<String> future = pool.submit(()->getStockInfo("YHOO"));
// Zeile 2
String stockInfo = "no result";
try { stockInfo = future.get(); } // Zeile 5
catch (InterruptedException | ExecutionException e)
{ ... }
System.out.println("YHOO: " + stockInfo);
// Zeile 8
Hier implementieren wir in Zeile 2 mit Hilfe einer Lambda Expression das Callable Interface und übergeben mit submit() dieses Callable an einen Threadpool, der es asynchron ausführen soll. Inhaltlich besteht unsere Implementierung aus dem Aufruf der Methode getStockInfo() mit dem Stringparameter YHOO . Dahinter steht ein HTTP-Request, der den aktuellen Kurs der Yahoo-Aktie ermittelt und als String zurückgibt. Wir erhalten vom Aufruf von submit() ein Future<String> zurück. Dieses future repräsentiert ein Handle auf das zukünftige String -Ergebnis.
Die Pull-Lösung
In Zeile 8 geben wir das Ergebnis aus, oder
den Default-Text
“n
o
result
“
, falls ein Fehler aufgetreten
ist.
Dieser Pull-Ansatz funktioniert meist ganz
zufriedenstellend. Typischerweise stößt man aber an seine Grenzen,
wenn man sehr viele Tasks an den Thread-Pool übergibt. Man braucht dann
nämlich für jede Task je einen Thread, um im blockierenden Aufruf von
get()
auf das Ergebnis der jeweiligen Task zu warten.
Das heißt, bei sehr vielen Tasks benötigen wir auch sehr viele Threads, die warten. Das ist ziemlich ressourcenintensiv. Zum einen kostet jeder Thread Speicherplatz. Zum anderen ist die Anzahl von parallel nutzbareren Threads (plattformabhängig) beschränkt. Das heißt, die Pull-Lösung skaliert nicht beliebig.
Die Poll-Lösung
Diese Methode hat einen Timeout-Parameter,
der aus zwei Teilen besteht: einem
long
-Wert
und einem
TimeUnit
-Wert, der angibt,
in welcher Zeiteinheit
(
NANOSECONDS
,
MICROSECONDS
,
MILLISECONDS
,
usw.)
der
long
-Wert zu interpretieren
ist. Wird nach dem Aufruf von
get()
der Timeout erreicht, wirft die Methode eine
TimeoutException
und signalisiert so, dass das asynchrone Ergebnis noch nicht vorliegt.
Um nun auf die asynchronen Ergebnisse von sehr vielen Tasks zu warten, kann man in einer Schleife diese get() -Methode mit Timeout auf jedem korrespondierenden Future aufrufen. Dabei wird man den Timeout relativ kurz wählen (vielleicht sogar: 0 NANOSECONDS ), um die Latenzzeit zwischen Eintreffen des Ergebnisses und Weiterverarbeiten des Ergebnisses möglichst gering zu halten.
Mit dem Poll-Ansatz benötigen wir nun nur noch einen Thread (die Schleife!) für alle Ergebnisse. Was die Thread-Ressourcen angeht, ist dieser Ansatz also viel genügsamer. Andererseits benötigt man nun zusätzliche CPU-Zeit für das Pollen. Dabei richtet sich die Höhe des CPU-Verbrauchs im wesentlich danach, wie häufig wir beim get() -Aufruf in den Timeout laufen und ohne Ergebnis zurückkommen. Die Tuningparameter dafür sind die Timeout-Zeit und die Reihenfolge der Future s in der Schleife. Wie gut diese Lösung dann ist, hängt sehr von der jeweiligen Situation ab.
CompletionService: die Queue-Poll-Lösung
Auch beim CompletionService wird also ein Pull oder Poll gemacht, allerdings genügt wegen der Result-Queue ein einziger Thread, der alle Ergebnisse abholt und sie nacheinander verarbeitet.
CompletableFuture: die Push-Lösung
ExecutorService pool = ...
CompletableFuture<String> future
= CompletableFuture.supplyAsync(()->getStockInfo("YHOO"),
pool); // Zeile 3
future.thenAccept(info->System.out.println("YHOO: "
+ info)); // Zeile 5
In Zeile 3 erzeugen wir ein
CompletableFuture<String>
;
es ist das Handle auf das zukünftige Ergebnis. Dazu rufen wir die statische
Methode
supplyAsync()
und übergeben
als Parameter die Lambda-Expression mit der auszuführenden Funktionalität
und den Thread-Pool. Hier sieht man schon einen Unterschied im API: während
das
Future
direkt vom
ExecutorService
beim Übergeben der asynchron auszuführenden Funktionalität erzeugt wird
(erstes Beispiel), gibt es für das
CompletableFuture
statische Factory-Methoden, denen Task und
ExecutorService
als Parameter übergeben wird.
Der entscheidende Punkt ist aber nun, wie
das
CompleteFuture
weiter verwendet wird.
Wir rufen auf dem
CompleteFuture
die
Methode
thenAccept()
auf und übergeben als Parameter eine Lambda-Expression, die auf das asynchrone
Ergebnis angewandt wird, wenn es dann eingetroffen ist. Der Thread, der
den Aufruf der Methode
thenAccept()
macht,
läuft nach dem Aufruf von
thenAccept()
weiter, unabhängig davon, ob das asynchrone Ergebnis schon vorliegt oder
nicht.
Das heißt, das Eintreffen des asynchronen
Ergebnisses triggert die Ausführung der in Zeile 5 als Parameter übergebenen
Lambda-Expression. Daher stammt auch der Name: Push-Lösung. In unserem
Fall gibt diese Lambda-Expression das Ergebnis auf STDOUT aus. Auf den
ersten Blick sieht diese Lösung fast aus wie ein Callback, insbesondere
in unserem Beispiel: da wir
thenAccept()
benutzt haben, führt der Poolthread, der das asynchrone Ergebnis ermittelt
hat, anschließend synchron auch die in Zeile 5 übergebene Funktionalität
aus. Aber es steckt deutlich mehr dahinter. Wenn wir z.B. in Zeile
5 statt
thenAccept()
die Methode
thenAcceptAsync()
verwenden, wird die als Parameter übergebene Lambda-Expression asynchron
ausgeführt.
Die Funktionalität des Push-Beispiel entspricht
im Wesentlichen der des Pull-Beispiel weiter oben. Es gibt einen kleinen
Unterschied: im Fehlerfall wird beim Push-Beispiel gar nichts ausgegeben.
Die Details der Fehlerbehandlung beim
CompleteFuture
schauen wir uns in diesem Beitrag weiter unten an.
Bleiben wir im Moment noch ein wenig beim
konzeptionellen Modell der Push-Lösung. Beide Methoden
thenAccept()
und
thenAcceptAsync()
verarbeiten das
vorhergehende Ergebnis, ohne selbst wieder ein eigenes, neues Ergebnis
zu liefern. Alternativ dazu gibt es die Methoden
thenA
pply
()
und
thenA
pply
Async()
.
Sie nehmen als Parameter Funktionalität vom Typ
Function<T,R>
, die wieder ein Ergebnis erzeugt. Damit kann man dann eine Kette von
Verarbeitungsschritten (engl.:
Stages
) erstellen, bei denen das
Ergebnis der vorhergehenden Stufe jeweils die nachfolgende Stufe startet
(push). Die Verbindung zwischen den Schritten kann dabei synchron oder
asynchron sein je nachdem, ob man die synchrone oder asynchrone Methode
wählt. Implementieren lässt sich das im Stil des
Fluent Programming
s,
den wir bereits von der Stream-Programmierung kennen (/
KRE
/):
CompletableFuture.supplyAsync(()->getStockInfo("YHOO"), pool)
.thenApplyAsync( ... )
.thenApply( ... )
.thenAccept( ...);
Die Details des API schauen wir uns weiter
unten an.
Typ-Hierarchie
Superinterface Future
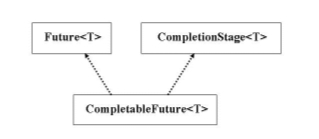
Die Klasse
CompletableFuture
implementiert u.a. auch das Interface
Future
.
Das heißt, das
CompletableFuture
unterstützt
neben der Push-Lösung auch die Pull- und Poll-Lösung. Wir können also
das Beispiel aus der Pull-Lösung von ganz oben auch mit einem
CompletableFuture
statt mit einem
Future
implementieren:
ExecutorService pool = ...
CompletableFuture<String> future
= CompletableFuture.supplyAsync(()->getStockInfo("YHOO"),
pool);
String stockInfo = "no result";
try { stockInfo = future.get(); }
catch (InterruptedException | ExecutionException e)
{ ... }
System.out.println("YHOO: " + stockInfo);
Weiter bedeutet es, dass auch hybride Lösungen
mit dem
CompletableFuture
möglich sind.
Dies hier ist eine Push-Pull-Lösung:
try {
result = CompletableFuture.supplyAsync(()->getStockInfo("YHOO"), pool)
.thenApplyAsync( ... )
.thenAppl( ... )
.get(); // Zeile 5
} catch (InterruptedException | ExecutionException
e) { ... }
Die Verarbeitung erfolgt erst über einige
Push-Stages, aber am Ende in Zeile 5 wartet der Thread dann auf das Gesamtergebnis
(Pull-Lösung).
Die Idee dahinter ist, dass das CompletableFuture den maximalen Funktionsumfang einer Future -Abstraktion im JDK unterstützt, und der JDK Benutzer entscheidet, was er davon wie nutzen möchte.
Superinterface CompletionStage
CompletableFuture<String> asyncRequest() { // Ansatz 1
CompletableFuture<String> future = new CompletableFuture<>();
…
return future;
}
Der Benutzer verwendet die Schnittstelle:
CompletableFuture<String> future = Library.asyncRequest(
... );
Dann wird dem Benutzer immer auch der Pull-
und Poll-Zugang möglich und nicht allein das Push-API.
Auf Grund dieses Feedbacks wurde dann die
Funktionalität des Push-API in das Superinterface
CompletionStage
herausgezogen, siehe (/
LEA2
/). Das heißt, der zurück
gelieferte Typ, der nur das Push-API zur Verfügung stellt, ist
CompletionStage
.
Eine Bibliotheksschnittstelle kann und sollte also
CompletionStage
zurückliefern,
wenn sie nur das Push-API anbieten möchte:
CompletionStage<String> asyncRequest() { // Ansatz 2
CompletableFuture<String> future = new CompletableFuture<>();
…
return future;
}
Der Benutzer bekommt dann nur noch ein Objekt
vom Typ
CompletionStage
:
CompletionStage<StringY future = Library.asyncRequest(
... );
Intern in der Implementierung der Bibliothek
wird aber weiterhin
CompletableFuture
verwendet. Es besteht so die Gefahr, dass ein Nutzer der Bibliothek das
erhaltene Objekt auf
CompletableFuture
zurück castet und Code wie diesen schreibt:
CompletableFuture<String> future
= (CompletableFuture<String>)Library.asyncRequest(
... ); // Ansatz 3
Damit kann er dann über das
CompletableFuture
auch die Pull- oder Poll-Funktionalität wieder verwenden.
Um mit dieser Situation richtig umgehen zu
können, enthält das Interface
CompletionStage
die Methode:
CompletableFuture<T> toCompletableFuture()
Sie stellt so etwas wie den offiziell vorgesehen
Cast auf das
CompletableFuture
zur Verfügung.
Der Bibliotheksentwickler kann nun entscheiden, ob er die Umwandlung in
ein
CompletableFuture
zulassen will oder
nicht. Wenn er sie zulassen will, braucht er nichts weiter tun, denn
die Default-Implementierung von
toCompletableFuture()
gibt
this
zurück. Wenn er die Umwandlung
abklemmen will, dann sieht der Code zum Beispiel so aus:
CompletionStage<String> asyncRequest() { // Ansatz 4
class ReactiveFuture<String> extends CompletableFuture<String> {
public CompletableFuture<String> toCompletableFuture() {
throw new UnsupportedOperationException () ;
}
public String get() {
throw new UnsupportedOperationException () ;
}
... analog für die übrigen Future-Methoden ...
}
CompletableFuture<String> future = new ReactiveFuture<>();
…
return future;
}
Die Bibliotheksschnittstelle gibt nun einen lokalen Subtyp ReactiveFuture von Complet ableFuture zurück. Die Ableitung überschreibt toCompletableFuture() so, dass die Methode eine UnsupportedOperationException wirft (siehe / TCF /). Zusätzlich muss man auch alle aus dem Interface Future geerbten Methoden, insbesondere die beiden get() Methoden, so überschreiben, dass sie eine UnsupportedOperationException werfen. Denn der Brute-Force-Cast aus Ansatz 3 funktioniert ja weiterhin, aber durch das Überschreiben der Future -Methoden kann der Benutzer nun nicht mehr auf die Pull- und Poll-Funktionalität zugreifen.
Das Benutzer API
Factory-Methoden
static <U> CompletableFuture<U> supplyAsync(Supplier<U> task)
static <U> CompletableFuture<U> supplyAsync(Supplier<U> task, Executor executor)
static CompletableFuture<Void> runAsync(Runnable task)
static CompletableFuture<Void> runAsync(Runnable
task, Executor executor)
Die als Parameter übergebene Task kann entweder
vom Typ
Supplier
<U>
sein; dann erzeugt sie ein Ergebnis vom generischen Typ
U
.
Die als Parameter übergebene Task kann alternativ ein
Runnable
sein, das kein Ergebnis hat. Abhängig davon erzeugt die Factory-Methode
dann ein
CompletableFuture<U>
(Ergebnis
vom Typ
U
) bzw. ein
CompletableFuture<Void>
(kein Ergebnis).
Auffallend ist vielleicht, dass die ergebniserzeugende
Task vom Interface-Typ
java.util.function.Supplier<
U
>
ist und nicht
java.util.concurrent.Callable<U>
wie bisher in ähnlichen Situationen. Andere Abstraktionen im Package
java.util.concurrent
verwenden üblicherweise das
Callable
(zum Beispiel
ExecutorService
.submit()
).
Der Grund dafür ist einfach, dass
Callable
s
Checked-Exceptions werfen dürfen (was der
Supplier
nicht darf) und der Fluent-Programming-Stil unter Verwendung von Lambdas
sich nicht gut mit Checked-Exceptions verträgt. Details dazu finden
sich hier: /
LEA3
/.
Der zweite optionale Parameter der Factory-Methoden ist der Thread-Pool vom Typ Executor . Das ist der Pool, von dem die Task ausgeführt werden soll. Wenn man keinen Thread-Pool als Parameter mitgibt,
• wird der neue „default“ Thread-Pool des JDK 8, nämlich java.util.concurrent.ForkJoinPool.commonPool() , verwendet, falls dieser Pool eine Parallelität (englisch : parallelism ) >= 2 hat, oder sonst
• wird explizit ein neuer Thread für die Ausführung der Task gestartet.
Details zum Common Pool finden sich in der Javadoc des ForkJoinPool s (/ FJP /). Die Einstellung der Parallelität ist in der Javadoc nicht beschrieben. Dazu muss man sich den Sourcecode ansehen und zwar die private Methode ForkJoinPool.makeCommonPool() . Da sieht man dann, dass die Parallelität im Default-Fall bei einem Multi-Core-System die Anzahl der Cores – 1 ist (genauer: Runtime.get Runtime().availableProcessors() –1 ). Bei einem Single-Core-System ist die Parallelität 1. Daneben lässt sich die Parallelität explizit mit Hilfe der System-Property java.util.concurrent.ForkJoinPool.common.parallelism festlegen (siehe / FJP /).
Von CompletionStage geerbte Methoden
Die elementare Basisfunktionalität wird von den drei Methoden
<U> CompletableFuture<U> thenApply (Function<T,U> task)
CompletableFuture<Void> thenRun (Runnable task)
CompletableFuture<Void> thenAccept (Consumer<T>
task)
zur Verfügung gestellt. Ähnlich wie bei den Factory-Methoden, die wir uns vorher angesehen haben, gilt auch hier: der Methodenname bestimmt den Typ der Task, die als Parameter übergeben wird und ausgeführt werden soll:
• thenApply() nimmt als Parameter eine Function<T,U> , die das Ergebnis der vorhergehenden Stufe als Input (Typ T ) bekommt und selbst wieder ein Ergebnis (vom Typ U ) produziert und zurückgibt. Der Returntyp von thenApply() ist daher CompletableFuture<U> .
• thenRun() nimmt als Parameter ein Runnable , das weder einen Input hat noch ein Ergebnis produziert. Der Returntyp von thenRun() ist daher CompletableFuture<Void> .
•
thenAccept()
nimmt als Parameter einen
Consumer<T>
,
der das Ergebnis der vorhergehenden Stufe als Input (Typ
T
)
bekommt, selbst aber kein Ergebnis produziert. Der Returntyp von
thenAccept
()
ist daher wieder
CompletableFuture<Void>
.
Von jeder dieser drei Methoden gibt es je drei Varianten. Sehen wir uns diese am Beispiel von thenRun() an:
CompletableFuture<Void> thenRun (Runnable task )
CompletableFuture<Void> thenRunAsync (Runnable task )
CompletableFuture<Void> thenRunAsync (Runnable task , Executor executor)
Die Varianten unterscheiden sich dabei dadurch,
wie sie die übergebene Task ausführen.
thenRun()
führt die Task synchron mit dem Thread aus, der die vorhergehende Stufe
ausgeführt hat. Für
thenRunAsync()
gilt das gleiche, wie oben bei den asynchronen Factory-Methoden beschrieben.
Die Variante mit dem expliziten
Ececutor
führt die Task asynchron auf diesem Thread-Pool aus. Die Variante ohne
Executor führt die Task asynchron auf dem CommonPool aus. Falls dessen
Parallelität kleiner als zwei ist, wird explizit ein Thread gestartet,
in dem die Task asynchron ausgeführt wird.
So ergeben sich als Basisfunktionalität neun Methoden, mit denen man
Verarbeitungsstufen hintereinander verketten kann.
Dazu kommt dann noch:
<U> CompletableFuture<U> thenCompose(Function<?
super T, ? extends CompletionStage<U>> task)
Diese Methode ist so etwas wie das flat-map
für das
CompletableFuture
. Wie man
an der Signatur sieht, ist das Ergebnis der Task bereits eine
CompletionStage<U>
,
welche dann als
CompletableFuture<U>
von
the
n
Compose()
zurück gegeben wird. Würde man diese Task mit
thenApply()
statt mit
thenCompose()
ausführen, würde
man ein
CompletableFuture<CompletableFuture<U>>
erhalten. Das ist nicht das, was man im Allgemeinen als Ergebnis haben
will, wenn man
fluent
die nächste Stufe anschließen möchte.
Deshalb benutzt man in einem solchen Fall
thenCompose()
statt
thenApply()
. Ergänzend zum synchronen
thenCompose()
gibt es auch wieder zwei asynchrone Versionen von
thenComposeAsynch()
.
In dem von
CompletionStage
geerbten API gibt es desweiteren Methoden, die es erlauben, eine Verarbeitungsstufe
nicht nur an eine, sondern an zwei vorhergehende Verarbeitungsstufen anzuschließen.
Dabei kann der Anschluss so erfolgen, dass
die nachfolgende Stufe ausgeführt wird, nachdem nur eine der vorhergehenden
Stufen ausgeführt wurde. Zum Beispiel:
<U> CompletableFuture<U> applyToEither(CompletionStage<? extends T> other,
Function<? super T,U> task)
Die vorhergehenden Stufen sind dabei zum
einen das
this
auf dem die Methode aufgerufen
wird und zum anderen der erste Parameter der Methode. Abhängig davon
welche der beiden Stufen zuerst ausgeführt worden ist, geht das erste
Ergebnis als Input an die Task.
Der Anschluss kann aber auch so erfolgen, dass die nachfolgende Stufe
ausgeführt wird, nachdem nicht nur eine, sondern beide vorhergehenden
Stufen ausgeführt worden sind. Zum Beispiel:
<U,V> CompletableFuture<V> thenCombine(CompletionStage<?
extends U> other,
BiFunction<?
super T,? super U,? extends V> task)
Wie man an der Signatur sehen kann, ist in
diesem Fall die Task eine
B
iFunc
tion
,
die die Ergebnisse beider vorgehender Verarbeitungsstufen als Input erhält.
Natürlich gibt zu
applyToEither()
und
thenCombine()
auch wieder die beiden
asynchronen Varianten.
Zusätzlich gibt für beide Anschlussarten applyToEither (Function) und thenCombine (BiFunction) abhängig von der Art der Task, die ausgeführt werden soll ( Function , Runnable oder Consumer ), weitere Methoden acceptEither( Consumer ) / runAfterEither(Runnable) und thenAcceptBoth(BiConsumer) / runAfterBoth(Runnable) . Auch diese Methoden gibt es natürlich wieder in drei Varianten.
Das Behandeln von Fehlern
Mit „lokal selbst in der Task reagieren“
ist gemeint, dass man die Exception schon in der Task selbst wieder fängt
und die Task normal beendet wird. Wenn nötig kann die Task zusätzlich
auch ein sinnvolles Default-Ergebnis liefern. Dies kann zum Beispiel
null
sein. Die Folgestufe muss dann natürlich auch in der Lage sein, mit
diesem Default-Wert als Input umgehen zu können. Dieser Ansatz bedeutet,
dass man einigen Aufwand in die lokale Fehlerbehandlung stecken muss und
die einzelnen Verarbeitungsstufen genau auf einander abstimmt sein müssen.
Schauen wir uns deshalb nun auch noch an,
was das
CompletableFuture
beim Error
Handling Support bietet; vielleicht kann man sich ja damit Arbeit sparen.
Was ist, wenn die Task einer Verarbeitungsstufe
mit einer unchecked Exception abgebrochen wird? Dann werden alle folgenden
Stufen nicht mehr ausgeführt und die Exception geht verloren, wenn man
keine weiteren Vorkehrungen trifft. Das heißt, die Pipeline wird mit
der Stufe, in der die Exception aufgetreten ist, abgebrochen. Der Abbruch
wird aber nicht nach Außen signalisiert. Dies gilt, wenn die Verarbeitungsstufen
mit einer der Methoden, die wir oben diskutiert haben, implementiert worden
ist. Es gibt aber für die Fehlererkennung und -behandlung sowie das
mögliche Wiederaufsetzen der Pipeline spezielle Methoden, die wir uns
nun genauer ansehen wollen:
CompletableFuture<T> exceptionally(Function<Throwable,T> task)
CompletableFuture<T> whenComplete (BiConsumer<T,Throwable> task)
<U> CompletableFuture<U> handle (BiFunction<T,Throwable,U>
task)
Die Methode
exceptionally()
erlaubt es, einen neues
CompletetableFuture<T
>
mit einem neuen Wert zu erzeugen, wenn die vorhergehende Stufe mit einer
Exception abgebrochen wurde. Schauen wir uns dazu ein Test-Beispiel an:
boolean flag = ... // Zeile 1
CompletableFuture.supplyAsync(() -> {
if (flag)
throw new IllegalStateException("TEST");
return "hello world";
})
.exceptionally(e -> {
System.err.println("exception occurred: " + e);
return "new text";
})
.thenAccept(s -> System.out.println(s));
Wenn das flag in Zeile 1 mit false initialisiert wird, ist der Returnwert der ersten Task " hello world" . Da keine Exception geworfen wurde, wird das exceptionally() übersprungen und gleich das thenAccept () mit dem " hello world" als Input ausgeführt. Der Output des Programms ist also: hello world .
Wenn das flag in Zeile 1 mit true initialisiert wird, wirft die erste Task eine IlegalStateException . Die Task wird abgebrochen und liefert keinen Returnwert. Da die vorhergehende Stufe mit einer Exception abgebrochen, wurde wird nun das exceptionally() ausgeführt. Wir geben die Exception, die wir als Parameter erhalten, auf STDERR aus und geben einen Ersatzttext ( "new text" ) zurück. Dieser wird nun als Input an das thenAccept() übergeben und dort ausgegeben. Der Output des Programms ist nun:
exception occurred: java.util.concurrent.CompletionException: java.lang.IllegalStateException: TEST
new text
Man sieht an der Ausgabe, dass die eigentliche
Exception (
IllegalStateException
) in eine
CompletionException
eingepackt ist.
Wenn man diese Fehlerbehandlung mit der Lösung vergleicht, die wir oben als „lokal selbst in der Task reagieren“ beschrieben haben, so sind beide gar nicht so unterschiedlich. In beiden Fällen wird im Fehlerfall ein neuer Wert erzeugt, der der nächsten Stufe als Input dient. Die Vorteile der Lösung mit exceptionally() sind:
• der Code der Task muss nicht verändert werden (keine zusätzlichen try-catch-Blöcke),
•
die
explizite Fehlerbehandlungsstufe auf oberster Ebene im Code ist deutlich
sichtbar und unabhängig von der vorhergehenden Task implementiert.
Mit der Methode
handle()
lässt sich die Fehlerbehandlung in die Folgestufe ziehen. Das heißt
die Funktionalität von
exceptionally()
und
thenAccept()
aus dem vorhergehenden
Beispiel kann alternativ in
handle()
implementiert werden. Der Code sieht dann so aus:
boolean flag = ... // Zeile 1
CompletableFuture.supplyAsync(() -> {
if (flag)
throw new IllegalStateException("TEST");
return "hello world";
})
.handle((s, e) -> {
if (e != null) {
System.err.println("exception occurred: " + e);
s = "new text";
}
System.out.println(s);
return (Void)null;
});
Die
BiFunktion
von
handle
()
hat zwei Input-Parameter. Der erste ist das potentielle Ergebnis, der
zweite die potentielle Exception der vorhergehenden Stufe. Einer davon
ist immer
null
, je nachdem ob die vorhergehende
Stufe normal beendet wurde (Exception
null
)
oder mit einer Exception abgebrochen wurde (Ergebnis
null
).
Wenn man das weiß, ist die Implementierung leicht zu verstehen. Sie
liefert das gleiche Ergebnis wie das vorhergehende Beispiel. Der Vollständigkeit
halber sollte noch erwähnt werden, dass es neben
handle()
zwei
weitere asynchrone Varianten
handleAsync()
gibt.
Kommen wir nun noch zu
CompletableFuture<T> whenComplete(BiConsumer<T,Throwable>
task)
Die Methode dient dazu, den Ausgang der vorhergehenden
Stufe mitzuloggen. Die beiden Input-Parameter des
BiConsumer
sind wieder das potentielle Ergebnis und die potentielle Exception der
vorhergehenden Stufe. Typischerweise würde man sie in der Implementierung
des
BiConsumer
s nutzen, um sie zu loggen.
Man kann keinen neuen Wert setzten. Das heißt, auf den Returnwert von
whenComplete()
haben wir gar keinen Einfluss; es wird einfach der Returnwert der vorhergehenden
Stufe verwendet. Zu
whenComplete()
gibt es auch wieder zwei Varianten von
whenCompleteAsync()
.
Bevor wir uns ein Beispiel für die Nutzung
von
whenComplete()
ansehen, wollen wir
unser Augenmerk noch mal auf einen Aspekt richten, den wir bereits kurz
erwähnt haben. Die „normalen“ Stufen-Methoden wie
thenApply()
,
thenRun
()
,
thenAccept()
und ihre asynchronen Varianten werden nicht aufgerufen, wenn in einer vorhergehenden
Stufe eine Exception geworfen wurde. Nur die Methoden für die Fehlerbehandlung
exceptionally()
,
whenComplete()
,
handle()
und ihre asynchronen Varienten (bei
exceptionally()
gibt es keine) werden in einer solchen Situation noch aufgerufen. Das
bedeutet, dass die Input-Parameter für die Fehlerbehandlungsmethoden nicht
aus der im Code vorhergehenden Stufe stammen, sondern aus der vorhergehenden
Stufe, die ausgeführt worden ist. Schauen wir uns mit diesem Aspekt
im Hinterkopf ein Beispiel für die Benutzung von
whenComplete()
an:
boolean flag = ... // Zeile 1
CompletableFuture.supplyAsync(() -> {
if (flag)
throw new IllegalStateException("TEST");
return "hello world";
})
.thenAccept(s -> System.out.println(s))
.whenComplete((v,e) -> {
if (e != null)
System.err.println("exception occurred: " + e);
});
Wenn das
flag
in Zeile 1 mit
false
initialisiert wird,
gibt das
thenAccept()
hello
world
aus. Das
whenComplete()
wird zwar aufgerufen, tut aber nichts. Angemerkt werden sollte vielleicht
noch, dass beide Input-Parameter von
whenComplete()
den Wert
null
haben. Das
e
ist
null
, weil vorher keine Exception
geworfen wurde, und das
v
ist
null
,
weil der Returnwert der Methode
thenAccept()
vom
Typ
CompletableFuture<Void>
ist, dass
heißt, die Task hat kein Ergebnis produziert.
Interessant wird das Ganze, wenn wir das
flag
in Zeile 1 mit
true
initialisieren.
Die
supplyAsync()
-Stufe wird mit einer
IllegalStateException
abgebrochen. Die
thenAccept()
-Stufe
wird gar nicht aufgerufen, weil die vorhergehende Stufe nicht normal beendet
wurde. Die
whenComplete()
-Stufe wird
aber wieder aufgerufen, weil sie ja eine Fehlerbehandlungsstufe ist.
Als Exception-Parameter erhält sie die Exception aus dem
supplyAsync()
und
gibt sie aus:
exception occurred: java.util.concurrent.CompletionException:
java.lang.IllegalStateException: TEST
Mit dem whenComplete() am Ende der Pipeline behandeln (= loggen) wir alle Exceptions, die in irgendeiner Stufe in der Pipeline auftreten. Dies ist unter Umständen ein sinnvoller Fehlerbehandlungsansatz: ein globales Errorhandling für die ganze Pipeline, statt jede Stufe einzeln auf Fehler zu überwachen. Ein Kriterium für die Entscheidung, ob die Fehlerbehandlung am Ende der Pipeline ausreicht, ist ganz sicher die Frage, ob die Verarbeitungsstufen Seiteneffekte haben. Wenn ja, wird man die Fehlerbehandlung vermutlich sehr nah an das Auftreten des Fehler heranbringen wollen, um sich klar darüber zu werden, welche Seiteneffekte bereits getätigt worden sind, und wie mit diesen umzugehen ist (Rollback, …). Wenn nein, dann ist die Fehlerbehandlung am Ende der Pipeline häufig eine sinnvolle, weil wenig aufwändige Lösung.
Von Future geerbte Methoden
Runnable runner = () -> {
System.out.println("started ...");
try {Thread.sleep(500); }
catch (InterruptedException ie) { return; }
System.out.println("... finished");
};
CompletableFuture<Void> future = CompletableFuture.runAsync(runner);
future.whenComplete((v, e) -> {
if (e != null)
System.out.println("exception occurred: " + e);
});
try {Thread.sleep(10); } // Zeile 15
catch (InterruptedException ie) {} // Zeile 16
future.cancel(true);
Wir starten mit runAsync() ein Runnable , das seinen Start ausgibt, 500ms schläft und dann noch sein Ende ausgibt. Sollte während des Schlafens eine InterrupedException erfolgen, beendet sich die Task sofort. Hier müssen wir jetzt den fluent Programmierstil unterbrechen, um das CompletableFuture zur gestarteten Task in der lokalen Variablen future zu speichern. Auf future wenden wir die Fehlerbehandlung aus dem vorhergehenden Beispiel an. Dann schlafen wir 10ms. Als letztes brechen wir die Ausführung der Task ab, indem wir auf future die Methode cancel() aufrufen. Die Ausgabe des Beispiels ist:
started ...
exception occurred: java.util.concurrent.CancellationException
... finished
Wie beschrieben kann das
cancel()
die bereits in einem Thread gestartete Task nicht abbrechen, deshalb läuft
sie weiter bis zu ihrem Ende. Auffallend ist dabei vielleicht, dass die
Fehlerbehandlungsstufe (
whenComplete()
) bereits
mit dem
cancel()
getriggert wird und
nicht erst, wenn die vorhergehende Task zu Ende gelaufen ist (siehe Reihenfolge
der Ausgabe!). Wie man sieht, bekommt man als Fehler eine
CancellationException
im Gegensatz zur
CompletionException
;
die kommt, wenn die vorhergehende Task von einer eigenen Exception abgebrochen
wurde.
Lässt man den
sleep()
in Zeile 15+16 weg, bekommt man eine
Race Condition
. Je nachdem,
ob die Task schneller in einem Thread gestartet wird, oder das
cancel()
schnell ist, bekommt man verschiedene Ergebnisse. Ist der Threadstart
schnell, so ist das Ergebnis das gleiche wie mit
sleep()
.
Ist das
cancel()
schneller, sieht die
Ausgabe so aus:
exception occurred: java.util.concurrent.CancellationException
Das heißt, das cancel() hat dazu geführt, dass die Task erst gar nicht ausgeführt wurde. In einer realen Situation ist so eine Race Condition natürlich unbefriedigend, besonders wenn die Task Seiteneffekte enthält. Ob das cancel() unter diesen Bedingungen überhaupt eine sinnvolle Funktionalität darstellt, muss wohl jeder für sich selbst an seinem eigenen Problem ausmachen.
Weitere Methoden
Das Bibliotheksentwickler (Library Writer) API
Die Nutzung ist erst einmal ziemlich geradeaus.
Mit dem Konstruktor erzeugt man sich ein
CompletableFuture
,
das man dem Benutzer zurückgibt. Wenn zu einem späteren Zeitpunkt das
asynchrone Ergebnis vorliegt, setzt man dieses mit
complete()
in das
CompletableFuture
. Stellt man
fest, dass beim Ermitteln des Ergebnisses ein Fehler aufgetreten ist, so
kann man diesen mit
completeExceptionally()
(passende Exception als Parameter) alternativ signalisieren.
In der Praxis wird es unter Umständen nicht immer so einfach gehen. Deshalb gibt es auch noch die Methoden obtrudeValue() , obtrudeExceptionally() . Wir wollen aber nicht weiter auf die Details eingehen, da man sich als Bibliotheksentwickler ohnehin selbst ein bisschen mehr in das Thema einarbeiten muss.
Zusammenfassung
Literaturverweise
| /FJP/ |
Javadoc
vom ForkJoinPool
URL:
http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ForkJoinPool.html
|
|
Übersicht
über das Stream API in Java 8
Klaus Kreft & Angelika Langer, Java Magazin,
Mai 2014
URL: http://www.angelikalanger.com/Articles/EffectiveJava/74.Java8.Streams-Overview/74.Java8.Streams-Overview.html |
|
| /LEA1/ |
CompletableFuture,
Doug Lea
URL:
http://cs.oswego.edu/pipermail/concurrency-interest/2012-December/010423.html
|
| /LEA2/ |
CompletionStage,
Doug Lea
URL:
h
ttp://cs.oswego.edu/pipermail/concurrency-interest/2013-July/011496.html
|
| /LEA3/ |
Mixing
Checked Exceptions and Lambdas Is Too Nightmarish, Doug Lea
|
| /TCF/ |
Javadoc
von CompletionState.toCompletableFuture()
|
![]()
Die gesamte Serie über Java 8:
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
|||||||||||||
Seminar
|
Related Reading
|
||||||||||||