| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java 8
Stream-Erzeugung und Stream-Operationen
Java Magazin, Juli 2014
|
Dies ist die Überarbeitung eines Manuskripts für einen Artikel, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Im vorangegangen
Beitrag haben wir erläutert, was Streams in Java 8 prinzipiell sind.
Es geht dabei um neue Schnittstellen im Package java.util, mit denen sequentielle
und parallele Operationen auf allen Elementen einer Sequenz (z.B. Liste,
Set, Array) unterstützt werden. Nach der Einführung im letzten Beitrag
wollen wir nun dieses Mal einen Überblick über das Stream API geben.
Woher bekommt man einen Stream? Welche Operationen unterstützt er?
Worauf muss ich achten, wenn ich die Operationen verwenden will? Wie
orientiere ich mich in der JavaDoc des Stream-APIs?
Kurze Wiederholung: Was sind Streams?
Ehe wir uns das Stream API mit seinen zahlreichen Methoden näher ansehen, wollen wir schauen, wie man Streams erzeugen kann.
Das Erzeugen von Streams
Collection-basierte Streams
List<String> stringList = … ;
Stream<String> sequentialStringStream = stringList. stream ();
Stream<String> parallelStringStream = stringList. parallelStream ();
Array-basierte Streams
String[] array = … ;
Stream<String> sequentialStringStream = Arrays. stream (array);
Stream<String> parallelStringStream = Arrays.stream(array).
parallel
();
Neben den Methoden
stream
und
parallelStream
gibt es zusätzliche
statische Factory-Methoden, um Streams zu erzeugen. Das
Stream
-Interface
hat zum Beispiel die Methode
of(T…)
,
mit der ein Stream erzeugt wird, indem die Elemente einfach aufgezählt
werden. Hier ein Beispiel:
Stream<String> sequentialStringStream = Stream. of (
"Ich", "ging", "im", "Walde",
"so", "für", "mich", "hin",
"und", "nichts", "zu", "suchen",
"das", "war", "mein",
"Sinn");
Zusätzlich gibt es im Stream -Interface die Methode of(T) für das Erzeugen von Streams mit einem Element und die Methode empty() für das Erzeugen von leeren Streams mit keinem Element.
Infinite Stream
Stream<Double> sequentialDoubleStream
= Stream.
generate
(Math::random);
// Zufallszahlen
Stream<Integer> sequentialIntegerStream
= Stream.
generate
(new
AtomicInteger()::getAndIncrement); // die ganzen Zahlen 0,1,2,3,4,
usw.
Stream<Integer> sequentialIntegerStream
= Stream.
iterate
(2,
i -> i*2);
// Zweierpotenzen: 2,4,8,16,32, usw.
Stream<BigInteger> sequentialBigIntegerStream
= Stream.
iterate
(BigInteger.ZERO,
i -> i.add(BigInteger.ONE)); // die ganzen Zahlen 0,1,2,3,4, usw.
Der generate -Methode wird eine Funktion übergeben, die bei jedem Aufruf das jeweils nächste Element der Sequenz liefert. In unserem Beispiel entsteht ein Stream von Pseudo-Zufallszahle bzw. ein Stream von ganzen Zahlen.
Die iterate -Methode bekommt einen Anfangswert seed und eine Funktion f , die auf den Anfangswert und danach auf den Returnwert des jeweils vorangegangenen Aufrufs angewandt wird. Sie liefert also seed , f(seed) , f(f(seed)) , usw. In unseren Beispielen entstehen ein Stream von Zweierpotenzen und ein Stream von ganzen Zahlen als BigInteger .
Primitive Streams
Die "integralen" Streams
IntStream
und
LongStream
haben zwei Factory-Methoden
range
und
rangeClosed
, die es in den anderen
Stream-Typen nicht gibt. Mit diesen Factory-Methoden können Streams
erzeugt werden, die einen Bereich von ganzen Zahlen enthalten. Hier sind
zwei Beispiele:
IntStream sequentialIntStream1 = IntStream. range (0,10); // die Zahlen von 0 bis 9
IntStream sequentialIntStream2 = IntStream.
rangeClosed
(0,10);
// die Zahlen von 0 bis 10
Bis jetzt haben wir alle Streams aus Collections oder Arrays erzeugt, weil Collections und Arrays die offensichtlichsten Abstraktionen im JDK sind, die Sequenzen von Elementen liefern können. Es gibt aber auch noch eine Reihe anderer Abstraktionen im JDK, die ebenfalls als Sequenzen interpretiert werden können. Die meisten dieser Abstraktionen haben nun Methoden, die Streams zu den betreffenden Sequenzen erzeugen.
Streams von Zufallszahlen
DoubleStream randomNumbers1 = new SplittableRandom(). doubles (); // unbeschränkt viele Zufallszahlen
DoubleStream randomNumbers2 = new SplittableRandom(). doubles (25); // nur 25 Zufallszahlen
DoubleStream randomNumbers3 = new SplittableRandom(). doubles (0,100); // unbeschränkt viele Zahlen aus [0,100)
DoubleStream randomNumbers4 = new SplittableRandom().
doubles
(25,0,100);//
25 Zufallszahlen aus [0,100)
Prinzipiell könnte man einen Stream von
Zufallszahlen auch mit Hilfe von
java.util.Random
oder
java.util.concurrent.ThreadLocalRandom
erzeugen. Das haben wir oben im Zusammenhang mit Generatoren schon gesehen
(denn
Math::random
verwendet intern
java.util.Random
)
.
Beide Zufallszahlengeneratoren sind thread-sicher und man könnte sie deshalb
sogar für Streams verwenden, auf denen parallele Operationen ausgeführt
werden sollen. Allerdings ist bei einem gemeinsam verwendeten
Random
-Objekt
die Performance unerfreulich, insbesondere wenn zahlreiche parallele Threads
intensiv auf das gemeinsame
Random
-Objekt
zugreifen. Mit einen
ThreadLocalRandom
-Objekt
lässt sich das Performancedefizit vermeiden, weil jeder Thread seine eigene
Kopie des Zufallszahlengenerators verwendet. Damit sind die Kollisionen
weg, aber es sind mehrere thread-lokale Kopien des Zufallszahlengenerators
im Spiel. Für manche Fragestellungen ist die Verwendung mehrerer Zufallsgeneratoren
aber nicht zufällig genug.
Das SplittableRandom löst beide Probleme - das Performance- und das Qualitätsproblem. Das SplittableRandom braucht nicht thread-sicher sein, weil es auch im parallelen Fall nicht gemeinsam verwendet wird. Es ist nicht "shared", sondern "splitted". Das ist so ähnlich wie bei einer Collection als Stream-Source. Man kann eine nicht thread-sichere Collection, z.B. eine ganz normale ArrayList , als Source für einen parallelen Stream verwenden. Es funktioniert, weil die internen Mechanismen der Streams dafür sorgen, dass die parallelen Threads nicht kollidierend auf dieselben Bereiche der Collection zugreifen. Vielmehr wird die Collection geteilt mit Hilfe eines so-genannten Splitterators . Beim SplittableRandom funktioniert es analog; deshalb ist kein Overhead für die Threadsicherheit nötig; damit ist das Performanceproblem gelöst. Das Qualitätsproblem wird beseitigt, indem anders als beim ThreadLocalRandom nicht einfach nur Kopien des Zufallszahlengenerators erzeugt werden, sondern die intern erzeugten Subgeneratoren sind so gemacht, dass sie die statistischen Eigenschaften des Originals erhalten. Wer sich für weitere Details zu SplittableRandom interessiert, dem sei / SPLR / als Informationsquelle empfohlen.
CharSequence-basierte Streams
String string = "abc";
IntStream chars1 = string. codePoints (); // die Character 'a','b','c'
IntStream chars2 = string.
chars
();
// die Character 'a','b','c'
static void print(IntStream stream, boolean asChar) {
String fmt = (asChar)?"%c":"%d";
stream.forEach(i -> System.out.format(fmt, i));
}
| Code Points vs. Characters |
|
Man mag sich fragen, worin sich die Methoden
codePoints
und
chars
unterscheiden: Die Methode
chars
liefert die Code Units der Zeichen im UTF-16-Encoding. Die Methode
codePoints
hingegen liefert die Unicode Codes der Zeichen.
Einen nennenswerten Unterschied macht es
immer dann, wenn ein einziger Code Point im Unicode-Encoding mit mehreren
Code Units im UTF-16-Encoding dargestellt wird. Das ist bei "Sonderzeichen"
der Fall; für die meisten gebräuchlichen Zeichen macht es keinen Unterschied,
weil sich ihr Unicode-Code-Point in genau einer UTF-16-Code-Unit darstellen
läßt.
Ein Beispiel für ein Zeichen, dass in UTF-16
mehrere Code-Units braucht, ist
Die Unicode-Code-Points werden in Java in
Variablen vom primitiven Typ
int
abgelegt. Die UTF-16-Code-Units werden in Variablen vom Typ
char
oder
char[]
abgelegt. Das Zeichen Die Konvertierung zwischen den Darstellungen findet man in der Klasse java.lang.Character . Unicode-Code-Points können mit der Methode char[] Character.toChars(int codePoint) in eine Sequenz von UTF-16-Code-Units konvertiert werden. Die umgekehrte Konvertierung geht mit der Methode int Character.toCodePoint(char high,char low)
|
Sonstige Streams
String poem = "Ich ging im Walde so für mich hin und nichts zu suchen das war mein Sinn";
Stream<String> words = Pattern.compile("[^\\p{L}]").
splitAsStream
(poem);
Die Klasse
Files
hat eine Method
lines
, die den Inhalt
einer Datei als Stream von Zeilen liefert. Hier ist ein Beispiel:
Stream<String> lines = Files.
lines
(Paths.get("text.txt"),
StandardCharsets.UTF_8);
Die Klasse Files hat außerdem noch eine Method list , die die Pfade alle Entries in einem Directory als Stream von Path -Objekten liefert. In diesem Stil gibt es auch außerhalb des Collection-Frameworks JDK-Abstraktionen, die seit Java 8 Sequenzen von Elementen in Form von Streams liefern.
Klassifizierung der Stream-Operationen
Intermediate vs. Terminal Operations
Ein Beispiel für eine solche Kette von Stream-Operationen ist:
String[] txt = { "State", "of", "the", "Lambda", "Libraries", "Edition"};
int sum = Arrays.stream(txt)
.filter(s -> s.length() > 3)
.map(String::length)
.peek(System.out::println)
.reduce(0, Integer::sum);
Die intermediären Operationen sind
filter
,
map
und
peek
; die terminale Operation ist
reduce
.
Wie wir beim letzten Mal schon erläutert
haben, werden die intermediären Operationen erst durch die terminale Operation
angestoßen. Die intermediären Operationen gehen also nicht hin und
wenden die übergebene Funktionalität auf alle Elemente der Input-Sequenz
an. Stattdessen fabriziert jede intermediäre Operation lediglich einen
neuen Stream, in dem sie hinterlegt, auf welchem Input-Stream welche zusätzliche
Operation auszuführen ist. Tatsächlich ausgeführt wird die gesamte
Kette von Operationen erst, wenn die terminale Operation auftritt. Erst
das Aufrufen der terminalen Operation führt dazu, dass die Elemente der
unterliegenden Datenquelle besucht und auf jedem Element die Kette der
intermediären Operationen plus der terminalen Operation ausgeführt wird.
In unserem obigen Beispiel wird die terminale
reduce
-Methode
den ersten String aus dem unterliegenden Array besuchen, darauf den Filter
("Stringlänge > 3) anwenden, anschießend den String auf seine Länge
abbilden, die Länge auf
System.out
ausgeben
und den ersten Reduktionsschritt "Anfangswert + Stringlänge" ausführen.
Danach besucht sie den zweiten String im Array, prüft seine Länge, stellt
fest, dass er zu kurz ist und wendet die Operationen
map
,
peek
und reduce auf dieses Element gar nicht mehr an. Desgleichen für den
dritten String im Array; er ist wieder zu kurz. Der vierte String ist
lang genug und seine Länge wird im Reduktionsschritt aufaddiert. Und so
verfährt die terminale Operation mit allen weiteren Elementen der unterliegenden
Sequenz, bis alle Elemente besucht wurden und das Endergebnis berechnet
ist.
Die beschriebene vertikale Abarbeitung in
einer Pipeline hat den Vorteil, dass jedes Sequenz-Element nur einmal besucht
werden muss und dass keine Zwischenergebnisse gespeichert werden müssen.
Alles wird in einem Durchgang erledigt. Ohne das Pipelining wäre auch
die parallele Abarbeitung von Stream-Operationen schwierig und ineffizient.
Es gibt noch einen anderen Unterschied zwischen intermediären und terminalen Operationen. Wir hatte beim letzten Mal schon erwähnt, dass terminale Operationen (im Gegensatz zu den intermediären Operationen) den Stream konsumieren. Nach einer terminalen Operation kann man keine weiteren Operationen mehr auf den Stream anwenden. Wenn man es trotzdem versucht, bekommt man eine IllegalStateException .
Short-Circuiting Operations
die folgenden intermediären Operationen:
Stream<T> limit (long maxSize)
Stream<T> skip (long n)
die folgenden terminalen Operationen:
boolean anyMatch (Predicate<? super T> predicate)
boolean allMatch (Predicate<? super T> predicate)
boolean noneMatch(Predicate<? super T> predicate)
Optional<T> findFirst()
Optional<T> findAny()
Die limit -Operation hört auf, wenn sie die spezifizierte Maximalzahl von Elementen besucht hat. Die skip -Operation verfährt ähnlich und besucht nur die Elemente nach dem n-ten Element. Die allMatch -Operation hört auf, wenn sie das erste Element gefunden hat, dass die spezifizierte Eigenschaft nicht hat; dann weiß sie, dass nicht alle Elemente die gewünschte Eigenschaft haben und liefert false zurück. Die Operationen anyMatch und non e Match hören auf, wenn sie das erste Element mit der spezifizierten Eigenschaft gefunden haben. anyMatch liefert dann true zurück, denn irgendeines der Elemente hat die gewünschte Eigenschaft. noneMatch liefert false zurück, denn es ist falsch, dass keines der Elemente die gewünschte Eigenschaft hat. Die Operationen findFirst und findAny machen nur einen einzigen Zugriff und liefern dann das betreffende Element zurück oder die Information, dass kein Element da war (weil der Stream leer ist).
Stateful vs. Stateless Operations
Andere Operationen hingegen benötigen zusätzlich
zum Sequenz-Element und der betreffenden Funktionalität Kontext-Information.
Zum Beispiel die
limit
-Operation muss
mitzählen, wie viele Elemente sie schon besucht hat, um zu wissen, wann
die Maximalzahl erreicht ist. Ähnlich bei der
distinct
-Operation:
sie soll Duplikate (gemäß
equals()
)
aussortieren. Dafür genügt es nicht, sich nur ein einzelnes Element
in Isolation anzusehen. Es wird die Kontext-Information darüber benötigt,
ob schon ein äquivalentes Element in der Sequenz gefunden wurde. Ein
weiterer offensichtlicher Fall ist die
sorted
-Operation:
man kann Sequenzen nicht sortieren, ohne die übrigen Sequenz-Element anzusehen.
Alle Operationen, die Kontext-Information sammeln und auswerten müssen,
werden als "stateful"-Operationen bezeichnet.
Die Unterscheidung ist wichtig, weil zustandslose
Operationen einfach zu handhaben sind und auch bei paralleler Abarbeitung
keinerlei Probleme bereiten. Zustandsbehaftete Operationen hingegen erfordern
bei der Parallelisierung zusätzlichen Aufwand, der mit Performance-Einbußen
verbunden sind. Der komplexeste Fall dieser Art ist die
sorted
-Operation.
Sortieren ist eine intermediäre Operation. Nun haben wir weiter oben
gesagt, dass die intermediären Operationen erst ausgeführt werden, wenn
eine terminale Operation angestoßen wird, was den Vorteil hat, dass keine
Zwischenergebnisse gespeichert werden müssen. Dieses effiziente Pipelining
geht bei der
sorted
-Operation aber gar
nicht. Die intermediäre
sorted
-Operation
führt (anders als zustandslose, intermediäre Operationen) dazu, dass
vor dem Sortieren und nach dem Sortieren die Sequenz zwischengespeichert
werden muss. Die Pipeline der Stream-Operationen wird also durch eine
sorted
-Operation
unterbrochen. Das ist natürlich schlecht für die Performance.
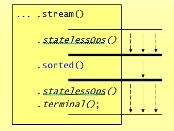
Abbildung 1: Prinzip der Verarbeitung der
sorted
-Operation
Man muss daher im Kopf behalten, dass Stream-Operationen
mit Zustand teurer sein können als zustandslose Stream-Operationen.
Dies gilt für
sorted()
schon im sequentiellen
Fall. Für die anderen "stateful"-Operationen kommt der Performancenachteil
erst bei Verarbeitung zum Tragen.
Nach diesen Erläuterungen zur Terminologie
und Klassifizierung der Stream-Operationen ist nun klar, was eine Beschreibung
in der JavaDoc wie "
This is a short-circuiting stateful intermediate
operation
." bedeuten soll: Es geht um eine intermediäre Operation
mit Zustand, die nicht notwendig alle Elemente besucht. So ist beispielsweise
die
limit
-Operation beschrieben. Wer
die Terminologie nachlesen will, findet Erläuterungen dazu in der JavaDoc
zum Package
java.util.stream
.
Die meisten Stream-Operationen kann man aus der Beschreibung in der JavaDoc und in Kenntnis der eben erläuterten Klassifizierung ganz gut verstehen. Die wesentlichen Operationen haben wir in diesem und dem vorangegangen Beitrag auch bereits erwähnt. Einzig die Operation flatMap bedarf einer weiteren Erläuterung.
map- und flatMap-Operationen
Stream<String> lines = Files.lines(Paths.get("poem.txt"), StandardCharsets.UTF_8);
Stream<String> lowerCaseLines = lines. map (String::toLowerCase);
lowerCaseLines.forEach(System.out::println);
Unser Input-Stream ist ein
Stream<String>
,
der die Zeilen einer Textdatei liefert. Jeder String wird mit der
lowerCase
-Methode
der Klasse
String
auf den entsprechenden
String in Kleinschreibung abgebildet. Das Ergebnis ist wieder ein
Stream<String>
.
Alle Strings werden am Ende ausgegeben.
Das Ergebnis der Abbildung muss nicht notwendig
wieder vom selben Typ sein. Hier ist ein Beispiel, in dem jeder String
auf seine Stringlänge abgebildet wird. Das Ergebnis ist dann ein
IntStream
.
Stream<String> lines = Files.lines(Paths.get("poem.txt"), StandardCharsets.UTF_8);
IntStream lineLengths = lines. mapToInt (String::length);
long totalLength = lineLengths.sum();
System.out.format("\nText contains %d characters.",
totalLength);
Selbstverständlich kann die Abbildung auch
so sein, dass jedes Sequenz-Element auf einen Stream abgebildet wird. Das
Ergebnis wäre dann ein Stream von Streams. Hier ist ein Beispiel:
Stream<String> lines = Files.lines(Paths.get("poem.txt"), StandardCharsets.UTF_8);
Stream<Stream<String>>
words = lines.
map
(Pattern.compile("[^\\p{L}]")::splitAsStream);
Die Input-Sequenz ist ein
Stream<String>
,
der die Zeilen aus einer Textdatei enthält. Wir zerlegen jede Zeile
in Worte mit Hilfe der
splitAsStream
-Methode
der Klasse
java.util.regex.Pattern
.
Die
splitAsStream
-Methode nimmt einen
String und macht daraus einen
Stream<String>
.
Wenn wir also den
Stream<String>
mit
den Zeilen der Textdatei hernehmen und mit der
map
-Operation
jeden einzelnen String (d.h. jede Zeile) auf einen
Stream<String>
abbilden, dann erhalten wir insgesamt einen
Stream<Stream<String>>
.
Einen Stream von Streams kann man nicht gut
weiter verarbeiten. Wenn beispielsweise die Zahl der Worte ermittelt
werden
soll, dann würde man dies gern mit der Stream-Operation
count
machen.
Stream<String> lines = Files.lines(Paths.get("poem.txt"), StandardCharsets.UTF_8);
Stream<Stream<String>> words = lines.map(Pattern.compile("[^\\p{L}]")::splitAsStream);
long count = words.
count
();
Wenn allerdings die
count
-Operation
auf den Stream von Streams angewendet wird, dann zählt sie, wie viele
innere Streams der äußere Stream enthält. Das wollen wir aber gar
nicht wissen. Wir wollen die Zahl der Strings in dem
Stream<Stream<String>>
.
Das geht aber mit der
count
-Operation
nur dann, wenn all die Ergebnis-Streams (d.h. die Worte je Zeile) zu einem
einzigen Stream zusammengefasst sind. Genau für diese Verflachung
- also das Vereinigen eines
Stream<Stream<T>>
in einem
Stream<T>
- gibt es die
flatMap
-Operation.
Hier noch einmal das obige Beispiel - dieses Mal mit
flatMap
anstelle von
map
:
Stream<String> lines = Files.lines(Paths.get("poem.txt"), StandardCharsets.UTF_8);
Stream<String> words = lines. flatMap (Pattern.compile("[^\\p{L}]")::splitAsStream);
long wordCount = words.
count
();
Die Abbildung geht immer noch per
splitAsStream
-Methode
von einem String (einer Textzeile) zu einem
Stream<String>
(den Worten in der Zeile). Anders als die
map
-Operation
macht die
flatMap
-Operation daraus aber
einen einzigen
Stream<String>
, der
alle Worte aus allen Zeilen enthält. Dann liefert die
count
-Operation
endlich die Zahl der Worte in unserer Textdatei.
Ganz allgemein ist die
flatMap
-Operation
für solche Abbildungen gedacht, bei denen aus jedem Sequenz-Element ein
Stream gemacht wird. Wenn man alle Ergebnis-Streams zu einem einzigen
Stream vereinigen will, dann ist
flatMap
die dafür geeignete Operation.
Hier ist noch ein flatMap-Beispiel:
Stream<String> words = lines.flatMap(Pattern.compile("[^\\p{L}]")::splitAsStream);
Stream<IntStream> streamOfIntStreams = words. map (String::chars);
IntStream
characters = words.
flatMapToInt
(String::chars);
Hier bilden wir jedes einzelne Wort mit Hilfe der String-Methode chars auf einen Stream von Zeichen (vom Typ IntStream ) ab. Wenn wir dafür die map -Operation verwenden, dann ist das Ergebnis ein Stream von IntStream s; wenn wir die flatMap -Methode nehmen, dann ist das Ergebnis zu einem IntStream verflacht.
Zusammenfassung
- wie man Streams erzeugt,
- wie die Stream-Operationen klassifiziert (als intermediate / terminal, stateless / stateful und short-circuiting), und
- was die Stream-Operation flatMap im Unterschied zu map macht.
Literaturverweise
| /LAMB/ |
Project
Lambda
|
| /LTUT/ |
Angelika Langer, Klaus Kreft
The
Lambda Tutorial & Reference
URL:
http://www.AngelikaLanger.com/Lambdas/Lambdas.html
|
|
Class
SplittableRandom, Doug Lea
URL:
http://cs.oswego.edu/pipermail/concurrency-interest/2013-July/011579.html
|
![]()
Die gesamte Serie über Java 8:
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
|||||||||||||
Seminar
|
Related Reading
|
||||||||||||