| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java 7
JSR 166y - Fork-Join-Framework Teil 2: Benutzung
Java Magazin, April 2012
|
Dies ist die Überarbeitung eines Manuskripts für einen Artikel, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Der Fork-Join-Framework ist eine der Neuerungen in Java 7. In unserem letzten Beitrag (siehe / JAVA7-5 /) haben wir uns die internen Mechanismen dieses Frameworks angesehen. Diesmal wollen wir ihn in einem konkreten Beispiel nutzen und uns danach anschauen, wie der Framework in zukünftigen JDK Abstraktionen genutzt werden wird.
Der Fork-Join-Framework ist Teil der Erweiterungen, die mit Java 7 neu
dazu gekommen sind. Genau genommen ist er Teil des JSR 166y.
In diesem JSR werden seit Java 5 von Doug Lea immer wieder neue Concurrency
Utilities in den JDK eingebracht (siehe /JSR166/). Der Fork-Join-Framework
ist ein spezieller Threadpool, bei dem die auszuführenden Tasks ganz
spezifische Abhängigkeiten untereinander haben. Diese Abhängigkeiten
sehen so aus, dass es eine Ausgangstask gibt, die in Subtasks (also Unteraufgaben)
aufgeteilt werden kann. Die Subtasks können nun ihrerseits wieder
in weitere Subtasks zerlegt werden. Dies kann sich über beliebig
viele Stufen fortsetzen und bildet die Fork-Phase des Verarbeitungsprozesses.
An einem definierten Punkt, der durch den Lösungsalgorithmus festgelegt
ist, hört die Verfeinerung auf und alle Subtasks der untersten Stufe
werden ausgeführt. Nun startet die Join-Phase. Hier werden
die Ergebnisse der Subtasks jeweils zu einem Ergebnis der Task, aus der
sie hervorgegangen sind, zusammengefasst. Dies setzt sich sukzessive
über alle Stufen fort und am Ende ergibt sich das Gesamtergebnis der
Ausgangstask.
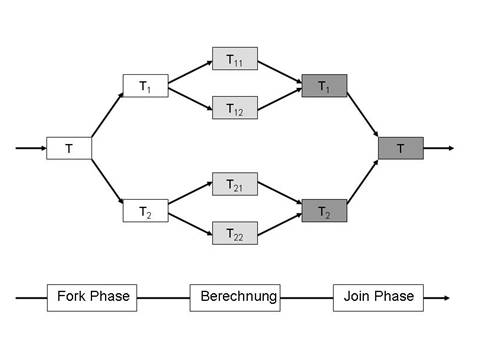
Abbildung 1: Struktur einer Fork-Join-Task
Abbildung 1 veranschaulicht graphisch die Struktur einer Fork-Join-Aufgabe
mit zwei Stufen und zwei Subtasks je Stufe.
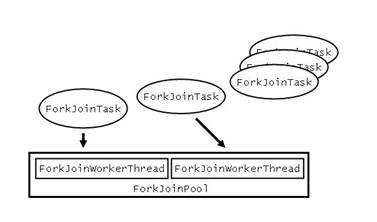
Abbildung 2: Abstraktionen des Fork-Join-Framework
Die Abstraktionen des Fork-Join-Frameworks liegen im Package
java.util.concurrent
.
Es gibt einen
ForkJoinPool
mit
ForkJoinWorkerThread
s,
die auf ganz normale Java Threads abgebildet werden und die
ForkJoinTask
s
ausführen (siehe Abbildung 2).
Beispiel: Suche des größten Elements in einem Array
Wir wollen nun an einem Beispiel die Benutzung des Fork-Join-Frameworks erläutern. Mithilfe des Fork-Join-Frameworks wollen wir in einem int-Array das größte Element finden. Im ersten Schritt geht es darum, das Problem der Suche auf eine Fork-Join-Task-Struktur zurückzuführen. Hier bietet sich eine Lösung an, die auf der Binären Suche ( binary search ) basiert. In unserem Fall bedeutet es, dass wir in der ersten Stufe das Array halbieren und mit je einer Sub-Task in jedem Teil-Array das größte Element suchen. Dieses Halbieren des Array-Intervalls, auf dem die Subtask die eigentliche Suche durchführen soll, kann man rekursiv weiter fortsetzen. So ergibt sich die Fork-Phase. Wenn das Intervall klein genug ist, suchen wir dann sequentiell das größte Element in diesem kleinen Intervall. Im Sinne der Bezeichnung aus Abbildung 1 ist dies die Berechung . In der anschließenden Join-Phase wird jede Task die Ergebnisse ihrer beiden Subtasks hernehmen, vergleichen und das größere von beiden Ergebnissen als eigenes Ergebnis weiterreichen. Die Join-Phase setzt sich fort, bis man zum Ergebnis der Ausgangstask kommt.Kommen wir zur eigentlichen Implementierung. Für rekursive Probleme wie unseres wird man nicht die ForkJoinTask direkt nutzen. Vielmehr gibt es im Fork-Join-Framework bereits die Abstraktionen RecursiveAction und RecursiveTask . Beides sind Subklassen der ForkJoinTask . Die RecursiveTask steht für Tasks zur Verfügung, die ein Ergebnis produzieren, die RecursiveAction für Tasks, die kein Ergebnis haben. Das heißt, die RecursiveAction wartet zwar beim Join auf ihre Subtasks; die Subtasks produzieren aber kein Ergebnis – anders als bei der RecursiveTask , wo die Subtasks Ergebnisse zurückliefern.
In unserem Problem hat die Task eigentlich ein Ergebnis, nämlichen den maximalen Wert in dem Intervall, das ihr zugeteilt worden ist. Also müssten wir die RecursiveTask für unsere Implementierung hernehmen. Die RecursiveTask ist eine generische Klasse, deren Typparameter der Typ des Ergebnisses der Task ist. Das heißt, in unserem Fall wäre dies der Typ Integer und wir müssten eine RecursiveTask<Integer> verwenden. Da wir die Suche auf einem int -Array durchführen wollen, wird für das Ergebnis immer eine Umwandlung von int in Integer ( Boxing ) notwendig. Aus Performancegründen wollen wir aber gerne auf dieses zusätzliche Boxing verzichten. Deshalb verwenden wir in unserer Implementierung die RecursiveAction und kümmern uns um die Ergebnisübergabe selbst.
Noch eine Designüberlegung, bevor wir uns den Source-Code ansehen wollen: Man findet Lösungen mit dem Fork-Join-Framework, bei denen die eigene von RecursiveAction oder RecursiveTask abgeleitete Klasse zusammen mit dem ForkJoinThreadPool das API für die Benutzung bildet. Wir haben das Gefühl, dass bei einer solchen Lösung der Fork-Join-Framework zu sehr nach außen sichtbar ist, und verwenden deshalb bei unserer Lösung zwei Klassen. Dies ist zum einen die API-Klasse MaxFinder , die nur eine Methode find() hat. Zum anderen gibt es die Klasse MaxInInterval , die von RecursiveAction abgeleitet ist. MaxInInterval ist also die Fork-Join-Task in unserer Implementierung. Sie ist als Inner Class von MaxFinder implementiert.
Fangen wir mit der API-Klasse MaxFinder an. Ihre Implementierung ist ziemlich übersichtlich:
public class MaxFinder {Im Konstruktor werden übergeben:
private class MaxInInterval extends RecursiveAction { ... };private final int[] theArray;
private final int intervalThreshold;
private final ForkJoinPool fjPool;public MaxFinder(int[] a, int iT, ForkJoinPool p) {
theArray = a;
intervalThreshold = iT;
fjPool = p;
}public int find() {
MaxInInterval task = new MaxInInterval(0, theArray.length);
fjPool.invoke(task);
return task.result;
}
}
- das Array, auf dem gesucht werden soll,
- der Schwellenwert der Arraygröße, unterhalb dem die Suche sequentiell durchgeführt werden soll, sowie
- der ForkJoinPool auf dem die Tasks verarbeitet werden sollen.
Kommen wir nun zur Implementierung unserer Fork-Join-Task MaxInInterval :
private class MaxInInterval extends RecursiveAction {Im Konstruktor werden die Indizes übergeben, die das Intervall festlegen, für das die Task verantwortlich ist. Das Array, auf das die Indizes sich beziehen, wird nicht übergeben. Da MaxInInterval eine Inner Class von MaxFinder ist, kann sie auf das Array theArray direkt zugreifen. Der konkurrierende Zugriff von verschiedenen Tasks auf das Array ist ungefährlich, da alle Tasks nur lesend zugreifen.
private static final long serialVersionUID = 4201137417063777426L;private final int start;
private final int end;
private volatile int result;private MaxInInterval(int s, int e) {
start = s;
end = e;
}private int findMaxSequentially() {
int max = Integer.MIN_VALUE;
for (int i=start; i<end; i++) {
int n = theArray[i];
if (n > max)
max = n;
}
return max;
}protected void compute() {
if (end - start < intervalThreshold) {
result = findMaxSequentially();
}
else {
int middle = (end - start) / 2;
MaxInInterval taskA = new MaxInInterval(start, start + middle);
MaxInInterval taskB = new MaxInInterval(start + middle, end);
invokeAll(taskA, taskB);
result = Math.max(taskA.result, taskB.result); }
}
}
Wesentlich für die Implementierung von MaxInInterval im Sinne des Fork-Join-Frameworks ist das Überschreiben der protected Methode compute() . Diese Methode enthält die eigentliche Funktionalität unserer Fork-Join-Task (vergleichbar mit der der run() Methode bei einem Thread). In unserem Fall ist dies zuerst die Prüfung, ob das Intervall, für das die Task zuständig ist, unter der Vorgabegrenze liegt. Wenn ja, wird das größte Element sequentiell im Intervall gesucht. Diese Funktionalität ist in die private Methode findMaxSequentially() ausgelagert.
Wenn das Intervall noch nicht klein genug ist ( else -Fall), wird es in der Mitte geteilt und zwei neue Subtasks erzeugt, die je für eines der Teilintervalle zuständig sind. Mit invokeAll() werden diese Subtasks zur Ausführung freigegeben. Dabei markiert der Aufruf von invokeAll() den Übergang von der Fork-Phase zur Join-Phase, denn der Aufruf kehrt erst zurück, wenn die beiden Subtasks (sowie deren Subtasks) ausgeführt worden sind. Am Ende wird noch das Ergebnis der Task als Maximum der beiden Subtasks in result gespeichert.
Was geschieht, wenn in der compute() Methode der RecursiveAction / RecursiveTask ein Fehler erkannt wird und eine Exception geworfen wird? Dann kann dies nur eine Runtime Exception oder ein Error sein. Eine Checked Exception lässt die Signatur der Methode nicht zu. In unserem Beispiel könnte es eine IndexOutOfBoundsException sein, wenn wir auf Grund eines denkbaren Fehlers bei der Implementierung versehentlich außerhalb unseres int -Arrays zugreifen. Was passiert nun, wenn für eine der Tasks die compute() Methode eine IndexOutOfBoundsException wirft? Wie beeinflusst dies unsere gesamte Berechung?
Das Verhalten aus Benutzersicht des Fork-Join-Frameworks ist sehr einfach
und übersichtlich. Unser Aufruf in den Fork-Join-Framework,
mit dem wir auf das Fertigwerden der Ausgangstask warten:
fjPool.invoke(task);
wird mit einer Exception vom gleichen Typ (also in unserem Fall:
IndexOutOfBoundsException
)
abgebrochen. Das heißt, wir werden durch diese Exception davon
informiert, dass unsere Berechung in einen Fehler gelaufen ist und alle
daran beteiligten Tasks und Threads abgebrochen wurden. Dies ist
eine Leistung des Frameworks, denn eigentlich ist nur einer der Poolthreads
bei der Ausführung einer
compute()
-Methode in eine Exception
gelaufen; der Framework sorgt dann dafür, dass die gesamte Berechnung
abgebrochen wird.
Um die Suche nach dem Ursprung des Fehlers zu unterstützen, enthält
die Exception, die aus
invoke()
geworfen wird, die ursprünglich
in
compute()
geworfene Exception als Cause. Der Stack Trace
der ursprünglichen Exception hilft dann dabei, die Ursache für
den Fehler in compute() zu finden.
Und was ist, wenn wir in
compute()
Methoden aufrufen, die
Checked Excepetions werfen? Die Checked Exceptions werden ja nicht
so ohne weiteres von
compute()
zu
invoke()
durchgeschleust.
Genau betrachtet kann eine solche Implementierung von
compute()
gar nicht übersetzt werden, da die Signatur der Methode keine Checked
Exceptions zulässt. Wir müssen in einem solchen Fall die
Checked Exception in
compute()
fangen, sie in eine Runtime Exception
als
Cause
einpacken und die Runtime Exception dann werfen.
Sie wird dann wie oben beschrieben durch den Fork-Join-Framework geschleust
und löst eine Exception in
invoke()
aus. Das heißt,
dass wir da, wo wir die
Throwable
s aus dem
invoke()
fangen,
durch Weiterverfolgen der Causes dann auch unsere ursprüngliche Checked
Exception wieder finden.
Bewertung der Fork-Join-Lösung
Die Funktion der Methode MaxInInterval.findMaxSequentially() entspricht der Funktionalität, die man implementiert, wenn man in einem Java-Programm sequentiell in einer for -Schleife den größten Wert in einem int -Array suchen würde. Das sind nur neun Zeilen Code. Worin liegt nun der Vorteil, der mit deutlich höherem Aufwand zu implementierenden Fork-Join-Lösung? Die kurze Antwort ist: Beim Ablauf der Fork-Join-Lösung kann diese von mehreren Threads ausgeführt werden und ist deshalb bei hinreichend großem Array auf einer Multicore-Hardwareplattform performanter als die for-Schleife in findMaxSequentially() , die inhärent sequentiell ist.
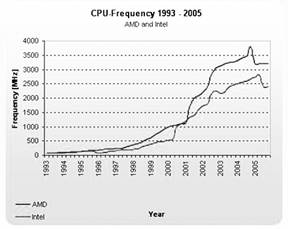
Abbildung 3: Entwicklung der Prozessorgeschwindigkeit
(Quelle: Tom's Hardware
- Testbericht: "Benchmark-Marathon: 82 CPUs von AMD und Intel" vom 3. November
2005)
Für die lange Antwort müssen wir etwas ausholen und einen Blick auf den Trend bei der CPU Entwicklung werfen. Bis ca. 2005 hat sich die Prozessorgeschwindigkeit stetig erhöht (siehe Abbildung 3). Seitdem stagniert sie. Stattdessen erhöht sich nun die Anzahl der Prozessorkerne, die in einem Prozessor verbaut werden ( Multicore CPU ). War es bis 2005 so, dass ein Prozessor zumeist nur einen Kern hatte, so gibt es heute Standard-Desktop-Systeme mit sechs bis acht Kernen. Auf Serverplattformen (weil dies Multiprozessor-Systeme sind) stehen noch deutlich mehr Kerne zur Verfügung. Berücksichtigt man dazu noch, dass es Systeme gibt, die es erlauben, mehr als einen Betriebssystem-Thread auf einem Kern parallel auszuführen, so wird deutlich, dass eine Herausforderung für die Softwareentwicklung heute darin besteht, alle parallelen Threads, die von der Hardware zur Verfügung gestellt werden, auch zu nutzen, denn nur so lässt sich performante Software erstellen. Da der Trend zu mehr Kernen pro Prozessor auch weiter anhalten wird, ist die Fähigkeit von Software-Lösungen, möglichst viele Threads parallel zu nutzen, auch ein Garant für die Zukunftssicherheit dieser Lösungen.
Unter diesem Gesichtspunkt wird dann auch klar, wann sich der Aufwand der Fork-Join-Lösung gegenüber der einfachen sequentiellen for -Schleife lohnen kann. Es ist dann der Fall, wenn die Software auf einer Multicore-Plattform abläuft und dabei genügend Prozessorkerne für die ForkJoinWorkerThread s in unserem ForkJoinPool zur Verfügung stehen. Erwähnt werden sollte unbedingt auch noch, dass das Array eine hinreichende Größe haben muss, so dass sich der Overhead für die Nutzung des Fork-Join-Frameworks (Erzeugen von Objekten, Anfordern von Systemressourcen, usw.) überhaupt lohnt.
Kommen wir noch zu einem Aspekt, den wir bisher noch nicht untersucht haben: wie viele Tasks und wie viele Threads sollte man bei einer Fork-Join-Lösung verwenden? Klarerweise richtet sich dies nach dem eigentlichen Problem und der genutzten Hardware Plattform (Anzahl der Kerne, die zur Verfügung stehen). Deshalb sind diese Werte in unserem Beispiel oben variabel und zwar der zweite und dritte Parameter des Konstruktors von MaxFinder . Dabei hängt vom zweiten Parameter (dem Schwellenwert für die Intervallgröße, ab der eine sequentielle Suche durchgeführt werden soll) die Anzahl der Tasks ab: je kleiner der Schwellenwert, desto mehr Tasks.
Der folgende Code ist ein Ausgangspunkt:
int nCores = Runtime.getRuntime().availableProcessors();Mit Hilfe der Klasse java.lang.Runtime bekommt man die Anzahl der Prozessorkerne, die der Java Virtuellen Maschine zur Verfügung stehen. Wir gehen davon aus, dass es keine anderen Aktivitäten gibt, die parallel ablaufen sollen, deshalb nutzen wir alle Kerne. Der dritte Parameter des Konstruktors ist also gleich der Anzahl der verfügbaren Prozessorkerne. Wenn es andere parallele Aktivitäten gibt, die eigene Threads brauchen, sollte man den Wert von nCores entsprechend verringern. Als Schwellenwert für das Intervall hat sich in der Praxis: 1+((myArray.length+7)>>>3)/nCores bewährt. Das heißt, man hat auf der untersten Ebene der Rekursion (in der sequentiellen Berechungsphase) mindestens acht Tasks pro Prozessorkern.
int maxValue = new MaxFinder(myArray, 1+((myArray.length +7)>>>3)/nCores, nCores).find();
Noch eine Bemerkung zur Anzahl der ForkJoinWorkerThread s: Wenn die Tasks Funktionalität enthalten, die nicht permanent die CPU nutzt (z.B. Dateizugriffe, Netzwerk I/O), kann es sinnvoll sein, die Anzahl der Threads im ForkJoinPool auch deutlich größer als availableProcessors() zu wählen.
Fork-Join-Framework und Java 8
Für Problemstellungen, wie im Beispiel betrachtet, wird es ab Java 8 standardisierte JDK-Abstraktionen geben, die auf den Fork-Join-Framework aufsetzen. Beschrieben sind diese Abstraktionen im JEP 107: Bulk Data Operations for Collections (/ JEP107 /). JEPs (= JDK Enhancement Proposals) sind relativ neue Elemente in der Entwicklung des OpenJDK. Man kann sie als Arbeitspakete der OpenJDK-Entwicklung betrachten. Details sind im JEP 1 beschrieben (/ JEP1 /).Kommen wir zu den Collection-Erweiterungen, die im JEP 107 beschrieben sind. Diese Erweiterungen basieren auf der sogenannten internen Iteration. Bisher hatten wir bei Java Collections eigentlich immer externe Iteration. Das heißt, wir haben uns einen Iterator von der Collection geben lassen und haben mit diesem explizit auf jedes Element der Collection zugegriffen. Im Gegensatz dazu erfolgt die interne Iteration dadurch, dass wir der Collection eine spezifische Funktionalität übergeben, die die Collection auf jedes ihrer Elemente anwendet. Dieser Ansatz ermöglicht es, dass die Collection die spezifische Funktionalität parallel, d.h. gleichzeitig, auf mehrere Elemente der Collection anwendet. Der Vorteil dieses Ansatzes ist auf einer Multicore-Plattform die bessere Performance im Vergleich zur externen sequentiellen Iteration.
Die Technik der internen Iteration, bei der die Funktionalität von Außen an die Collection übergeben wird, stammt aus der Funktionalen Programmierung. In Java fehlten bisher Sprachelemente, mit denen das Übergeben von Funktionalität auf einfache Art und Weise möglich war. Das wird sich mit Java 8 ändern, wenn Java um Lambda-Expressions (siehe / PL /) erweitert wird.
Schauen wir uns an, wie die Erweitungen der Collections konkret aussehen, soweit man das heute auf Grund der Beschreibung im JEP 107 vor der Freigabe von Java 8 schon sagen kann.
Auf alle Collections wird man nun Methoden für die interne Iteration ( forEach() , filter() , map() , reduce() ), wie sie aus der Funktionalen Programmierung bekannt sind, anwenden können. Diese Methoden werden in dem neuen Interface java.lang.util.stream.Stream angeboten. Zusätzlich werden im Interface java.lang.util.Collection die Methoden stream() bzw. parallelStream() mit Hilfe von Default-Implementierungen (sogenannten Extension Methods , auch neu in Java 8 (siehe / PL /)) hinzugefügt. Mit diesen Methoden kann man aus einer Collection einen sequentiellen bzw. parallelen Stream erzeugen.
Die Grundlage für die Implementierung des parallelen Streams bildet dabei der Fork-Join-Framework.
Um aus einer Collection von String-Elementen (zum Beispiel einer ArrrayList<String> ) die Strings herauszufiltern, die mit "abc" beginnen, können wir (unter Verwendung von Lambda Expressions) folgendes schreiben:
myCol.stream().filter(s -> s.startWith("abc"))
, oder
myCol.parallelStream().filter(s -> s.startWith("abc"))
.
Im ersten Fall wird der Filter sequentiell auf ein Element nach dem anderem angewandt, im zweiten Fall immer parallel auf mehrere Elemente gleichzeitig. Wenn unsere Collection hinreichend groß ist und der Code auf einer Multicore-Plattform mit genügend freien Cores ausgeführt wird, ist die zweite Alternative schneller als die erste.
Um parallele Funktionalität auch auf built-in Arrays anwenden zu können, erhält die Klasse java.util.Arrays zusätzlich die statische Methoden
Stream<T> stream(final T[] array)
und
Stream<T> parallelStream(final T[] array)
,
die ein built-in Array von generischem Typ T[] einen sequentiellen bzw. parallelen Stream konvertiert.
Wir würden jetzt gerne die Methode nutzen, um unser ursprüngliches Fork-Join-Beispiel (Suche nach dem größten Element in einem int -Array) zu lösen. Leider geht das nicht, da wir ein int -Array haben und kein Integer -Array. Deshalb gibt es spezielle Streams: IntStream , LongStream , DoubleStream für die primitiven Typen: int , long , double , sowie weitere überladene Konvertierungsmethoden stream() bzw. parallelStream() in java.util.Arrays für die Arrays dieser primitiven Typen.
So können wir das größte Element in einem int -Array einfach durch
int max = Arrays.parallel(myIntArray).reduce(Integer.MIN_VALUE, java.lang.Math::max(int,int));
parallel suchen, indem wir das reduce() in Kombination mit der max() Methode aus java.lang.Math als IntOperator nutzen. Die Syntax mit den zwei Doppelpunkten ( :: ) zwischen Typ und Methode ist übrigens auch neu in Java 8. Es handelt sich hierbei um eine Method Reference (siehe / PL /).
Genau genommen geht das Suchen nach dem größten Element sogar noch etwas einfache, da alle Streams eine max() Methode enthalten:
int max = Arrays.parallel(myIntArray).max().get();
Zusätzlich zum JEP 107 wird auch der JEP 103: Parallel Array Sorting (siehe / JEP103 /) parallele Funktionalität auf Basis des Fork-Join-Frameworks in Java 8 anbieten. Dazu gibt es in java.util.Arrays überladene statische parallelSort() -Methoden, die Arrays mit Elementen von primitivem oder generischen Typ parallel sortieren. Der Algorithmus, der den parallelSort() -Methoden zu Grunde liegt, sieht dabei folgendermaßen aus: Das Array wird in der Fork-Phase halbiert (wie in unserem Beispiel bei der Suche nach dem größten Element auch). In der Berechnungsphase werden alle Teil-Arrays parallel sortiert und in der anschließenden Join-Phase werden dann jeweils zwei sortierte Teil-Arrays so zusammengeführt, dass das daraus resultierende Array wieder sortiert ist.
Wir können also unser Ausgangsproblem: das größte Element in einem int -Array zu finden, auch so lösen, dass wir das Array erst parallel aufsteigend sortieren und dann das letzte Element lesen:
Arrays.parallelSort(myIntArray);
int max = myIntArray[myIntArray.length-1];
Dies ist aber nicht besonders effizient, da das parallele Sortieren einen gewissen algorithmischen Overhead hat, der sich durch das Zusammenführen der sortierten Teil-Arrays ergibt. Laut JEP 103 soll die Geschwindigkeitssteigerung bei Verwendung des parallelen Sortierens gegenüber sequentiellem Sortieren auf einer Dual-Core-Plattform immerhin noch bei Faktor 1,3 liegen.
Wie man sieht, sind mit dem Fork-Join-Framework die Grundlagen für die komfortable Unterstützung von feingranular parallelisierten Operationen in Java 8 geschaffen worden.
Zusammenfassung
In diesem Beitrag haben wir uns am Beispiel einer Binären Suche die Benutzung des in Java 7 hinzugekommenen Fork-Join-Pools angesehen. Generell lassen sich mit dem Fork-Join-Pool rekursiv zerlegbare Aufgaben einfach und bequem parallelisieren. Die Parallelisierung lohnt sich um so eher, je mehr Prozessoren bzw. Prozessorkerne zur Verfügung stehen und je größer die zu zerlegende Aufgabe ist.
Wie wir gesehen haben, ist der Fork-Join-Framework dabei aber nicht
nur wichtig für die direkte Nutzung, sondern auch um wieder verwendbare
Abstraktionen zu implementieren, die von sich aus feingranular parallele
Funktionalität zur Verfügung stellen. Dies ist natürlich
insbesondere für den JDK relevant. JEP 103 und 107 sind die
ersten Ansätze, solche Abstraktionen auf Basis des Fork-Join-Frameworks
in Java 8 zur Verfügung zu stellen.
Literaturverweise
| /JEP1/ |
JDK Enhancement-Proposal & Roadmap Process
URL: http://openjdk.java.net/jeps/1 |
| /JEP103/ |
JDK Enhancement Proposal 103: Parallel Array Sorting
URL: http://openjdk.java.net/jeps/103 |
| /JEP107/ |
JDK Enhancement Proposal 107: Bulk Data Operations for Collections
URL: http://openjdk.java.net/jeps/107 |
| /JSR166/ |
Doug Lea: Concurrency JSR-166 Interest Site
URL: http://gee.cs.oswego.edu/dl/concurrency-interest/ |
| / PL/ |
OpenJDK: Project Lambda
URL: http://openjdk.java.net/projects/lambda/ |
Die gesamte Serie über Java 7:
| /JAVA7-1/ |
Java 7 - Überblick
Klaus Kreft & Angelika Langer, Java Magazin, Juni 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/57.Java7.Overview/57.Java7.Overview.html |
| /JAVA7-2/ |
JSR 334 - "Project Coin" (Strings in switch,
Exception Handling, ARM, numerische Literale)
Klaus Kreft & Angelika Langer, Java Magazin, August 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/58.Java7.Coin1/58.Java7.Coin1.html |
| /JAVA7-3/ |
JSR 334 - "Project Coin" (Sprachneuerungen im
Zusammenhang mit Generics)
Klaus Kreft & Angelika Langer, Java Magazin, Oktober 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/59.Java7.Coin2/59.Java7.Coin2.html |
| /JAVA7-4/ |
JSR 203 - "NIO2" (Erweiterung der I/O Funktionalität)
Klaus Kreft & Angelika Langer, Java Magazin, Dezember 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/60.Java7.NIO2/60.Java7.NIO2.html |
| /JAVA7-5/ |
JSR 166y - Fork-Join-Framework (Teil 1: Internals)
Klaus Kreft & Angelika Langer, Java Magazin, Februar 2012 URL: http://www.angelikalanger.com/Articles/EffectiveJava/61.Java7.ForkJoin.1/61.Java7.ForkJoin.1.htm |
| /JAVA7-6/ |
JSR 166y - Fork-Join-Framework (Teil 2: Benutzung)
Klaus Kreft & Angelika Langer, Java Magazin, April 2012 URL: http://www.angelikalanger.com/Articles/EffectiveJava/62.Java7.ForkJoin.2/62.Java7.ForkJoin.2.htm |
| /JAVA7-7/ |
Thread-Synchronisation mit Hilfe des Phasers
Klaus Kreft & Angelika Langer, Java Magazin, Juni 2012 URL: http://www.angelikalanger.com/Articles/EffectiveJava/63.Java7.Phaser/63.Java7.Phaser.htm |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||||
Seminar
|
||||