| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java 7
JSR 166y - Fork-Join-Framework Teil 1: Interals
Java Magazin, Februar 2012
|
Dies ist die Überarbeitung eines Manuskripts für einen Artikel, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Wir setzen unser Reihe über Neuerungen in Java 7 mit dem Fork-Join-Framework fort. Der Framework ist Teil des JSR 166y. Die Abstraktionen des JSR 166 werden traditionell von Doug Lea entwickelt und zur Verfügung gestellt. Der Original-JSR 166 ging in Java 5 ein und erste Ergänzungen als JSR 166x in Java 6. Weitere Ergänzungen sind nun als 166y in Java 7 gekommen. Die JSR-166-Webseite von Doug Lea findet sich hier / JSR166 /.
Wir wollen uns in diesem Artikel das Design des Fork-Join-Framework zusammen mit einigen Implementierungsdetails genauer ansehen. Im nächsten Artikel diskutieren wir ausgehend von einem Benutzungsbeispiel, welche Rolle der Fork-Join-Framework für einige Erweiterungen in Java 8 spielen wird und wie sich damit die Benutzung von Arrays und Collections in Java zukünftig verändern wird.
Der ThreadPoolExecutor - ein kurzer Rückblick
Bevor wir mit dem Fork-Join-Framework beginnen, wollen wir zur Abgrenzung einen kurzen Blick auf den ThreadPoolExecutor werfen. Der ThreadPoolExecutor ist der Standard-Threadpool, der in Java im Rahmen des JDK zur Verfügung steht. Er war Teil des JSR 166 und ist dementsprechend mit Java 5 Bestandteil des JDK geworden. Wir haben ihm damals einen ausführlichen Artikel gewidmet /TPE/.Für die Diskussion hier ist wichtig, dass alle Tasks, die man zu Ausführung an den Threadpool übergibt, voneinander unabhängig sein müssen. Sie dürfen zum Beispiel nicht im Ergebnis voneinander abhängig sein, in einer festengelegten Reihenfolge abgearbeitet werden müssen, oder sonst wie miteinander korrelieren. Es ist nicht immer ganz einfach, hier die potentiellen Korrelationen zu erkennen. Wenn man zum Beispiel in einem Eventserver das Senden der Events an die Clients über einen ThreadPoolExecutor abwickelt, so scheint dieser Ansatz erst einmal unproblematisch zu sein. Ist er aber leider möglicherweise nicht. Das Problem ist, dass die Reihenfolge der Events für einen Client unter Umständen nicht eingehalten werden kann. Das heißt, es kann vorkommen, dass die Reihenfolge, in der die Events an einen Client versandt werden, nicht mehr der Reihenfolge entspricht, in der die Events an den ThreadPoolExecutor übergeben wurden.
Wir haben also übersehen, dass die Reihenfolge der Events für einen Client eine Abhängigkeit darstellt, die der ThreadPoolExecutor nicht einhalten kann. Konkret kann dieses Reihenfolge-Problem zum Beispiel dadurch entstehen, dass zwei Events für den gleichen Client direkt hintereinander an den ThreadPoolExecutor übergeben werden. Jedem Event wird gleich ein Poolthread zugeordnet. Auf Grund des aktuellen Threadschedulings wird aber der Thread für den ersten Event angehalten und dem Thread für den zweiten Event wird die CPU zugeordnet. So wird dann der zweite Event vor dem ersten an den Client zugestellt.
Lösen kann man das Problem dadurch, dass man nur jeweils einen Event pro Client an den ThreadPoolExecutor übergibt. Wenn mehrere Events für einen Client zu bearbeiten sind, dann lässt man Events in clientspezifische Queues vor dem Threadpool warten, bis der jeweils vorhergehende Event des Clients vom ThreadPoolExecutor verarbeitet worden ist.
Zusammenfassend lässt sich feststellen, dass der ThreadPoolExecutor nicht für Tasks geeignet ist, die irgendwelche Abhängigkeiten untereinander haben. Manchmal kann man aber (wie in unserem Beispiel oben) die Abhängigkeiten eliminieren und so den ThreadPoolExecutor weiter benutzen.
Der Fork-Join-Framework in der Übersicht
Der Fork-Join-Framework ist nun ein spezieller Threadpool, bei dem die Tasks ganz spezifische Abhängigkeiten untereinander haben. Dabei sind die Abhängigkeiten so verzahnt, dass eine Abbildung auf den ThreadPoolExecutor nicht möglich ist. Deshalb gibt es den Fork-Join-Framework als Erweiterung im JDK.Fangen wir mit einem Blick auf die Struktur der Tasks beim Fork-Join-Framework an, um ihre spezifische Verzahnung zu verstehen. Die Idee beim Fork-Join ist, dass es eine Ausgangstask gibt, die in Subtasks (also Unteraufgaben) aufgeteilt werden kann. Die Subtasks können nun ihrerseits wieder in weitere Subtasks zerlegt werden. Dies kann sich über beliebig viele Stufen fortsetzen und bildet die Fork-Phase des Verarbeitungsprozesses. An einem definierten Punkt, der durch den Lösungsalgorithmus festgelegt ist, hört die Verfeinerung auf und alle Subtasks der untersten Stufe werden ausgeführt. Nun startet die Join-Phase. Hier werden die Ergebnisse der Subtasks jeweils zu einem Ergebnis der Task, aus der sie hervorgegangen sind, zusammengefasst. Dies setzt sich sukzessive über alle Stufen fort und am Ende ergibt sich das Gesamtergebnis der Ausgangstask.
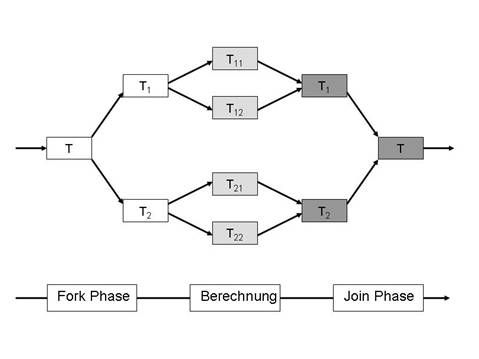
Abbildung 1: Struktur einer Fork-Join-Task
Die Anzahl der Subtasks sowie die Anzahl der Aufteilungsstufen ergeben sich aus dem spezifischen Algorithmus, mit dem die jeweilige Aufgabe gelöst wird. Abbildung 1 veranschaulicht graphisch die Struktur einer Fork-Join-Aufgabe mit zwei Stufen und zwei Subtasks je Stufe. Typischerweise lassen sich mit dem Fork-Join gewisse mathematische Probleme (zum Beispiel Matrix-Operationen) aber auch softwaretechnische Algorithmen wie etwa die Binäre Suche ( binary search ) lösen. Für eine Binäre Suche, bei der man in einem int -Array das größte Element sucht, würde man in der ersten Stufe das Array halbieren und sich vornehmen, das größte Element in jedem der beiden Teil-Arrays zu suchen. Dieses Halbieren des Array-Intervalls, auf dem die Subtask die eigentliche Suche durchführen soll, kann man rekursiv weiter fortsetzen. So ergibt sich die Fork-Phase. An einem gewissen Punkt, wenn das Intervall klein genug ist, sucht man sequentiell das größte Element in jedem Intervall. Im Sinne der Bezeichnung aus Abbildung 1 ist dies die Berechung . In der anschließenden Join-Phase wird jede Task die Ergebnisse ihrer beiden Teilintervalle hernehmen, vergleichen und das größere von beiden als eigenes Ergebnis weiterreichen. Die Join-Phase setzt sich fort, bis man zum Ergebnis der Ausgangstask kommt und so das größte Element im Ausgangsarray gefunden hat.
Angesichts der Struktur eines Fork-Join-Problems stellt sich die Frage, warum man zu seiner Implementierung einen neuen Framework benötigt. Der erste naive Ansatz wäre doch, jede Task als eigenen Java-Thread zu implementieren. Subtasks können dann einfach durch den Aufruf von start() auf dem Thread -Objekt gestartet werden. Auch das Warten auf die Beendigung von Subtasks bekommt man quasi umsonst: dazu ruft man die join() -Methode des Subtask-Threads auf. Im Prinzip sind also alle Mechanismen, die man benötigt, schon in der Thread -Klasse vorhanden. Okay, für das Ergebnis der Task sollte man vielleicht noch einmal von Thread ableiten und ein Feld, das den Ergebniswert speichert (zusammen mit einem Getter für das Feld) hinzufügen. Aber das wär's dann auch schon.
Bei kleinen Aufgaben (wenig Stufen, wenig Subtasks) ist dieser direkte Ansatz ganz sicher noch praktikabel. Bei größeren Aufgaben ergeben sich aber ernste Nachteile. Zum einen benötigt man bei vielen Tasks viele Threads und damit viele Systemressourcen. Unter Umständen stößt man bei sehr großen Aufgaben sogar an die maximale Anzahl von Threads, die von einem Prozess oder im Gesamtsystem gestartet werden können. Zum anderen ergibt sich aus dem Erzeugen und Beenden der Threads ein erheblicher Overhead, besonders wenn die eigentliche Berechung innerhalb der Task nur aus ein paar Zeilen Code besteht. Um noch mal den Bogen zum ThreadPoolExecutor zu schlagen: dieser Overhead ist eines der Argumente, warum wir unabhängige Tasks von einem ThreadPoolExecutor ausführen lassen und nicht als eigenen Thread starten.
Schauen wir uns nun den Fork-Join-Framework im Detail an, um zu sehen,
wo er die Performance betreffend besser ist als der oben diskutierte direkte
Ansatz mithilfe der
Thread
-Klasse.
Der Fork-Join-Framework im Detail
Grundsätzlich ähnelt die Struktur des Fork-Join-Frameworks der eines normalen Threadpools. Es gibt einen ForkJoinPool , dessen ForkJoinWorkerThread s auf ganz normale Java Threads abgebildet werden. Die ForkJoinWorkerThread s führen die ForkJoinTask s aus (siehe Abbildung 2). Die Abstraktionen des Fork-Joins-Frameworks in Java 7 befinden sich übrigens alle im Package java.util.concurrent .
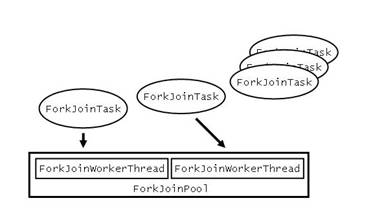
Abbildung 2: Abstraktionen des Fork-Join-Framework
Der Vollständigkeit halber sei noch erwähnt, dass man auf der JSR-166Webseite von Doug Lea (/ JSR166 /) auch eine Version des Fork-Join-Frameworks herunterladen kann, die unter Java 6 benutzt werden kann. In dieser Version sind die Abstraktionen des Frameworks dann im Package jsr166y .
Um eine gute Performance zu garantieren, sind das Design und die Implementierung des Fork-Join-Frameworks mit das Ausgeklügeltste, was es im gesamten JDK gibt. Wichtig für das Design ist die Strategie, nach der ForkJoinTask s den ForkJoinWorkerThread s zugeordnet werden. Das zentrale Element bei der Zuordnung sind dabei die Auftragsqueues, von denen je eine pro ForkJoinWorkerThread existiert. In der Auftragsqueue stehen die ForkJoinTask s, die ein ForkJoinWorkerThread zu bearbeiten hat.
Genau genommen ist die Auftragsqueue aber gar keine Queue sondern eine Deque, also eine Double-Ended-Queue. Während im strengen Sinne eine Queue nur das Lesen am Anfang und das Schreiben am Ende unterstützt, kann man bei der Deque sowohl am Anfang als auch am Ende lesen und schreiben. Es ist also in gewisser Weise eine Queue, die sich zusätzlich an beiden Enden wie ein Stack verhält.
Interessant ist nun, wie die Auftragsqueue verwendet wird. Der Thread bearbeitet die Tasks aus seiner Queue in FIFO-Reihenfolge (FIFO = first in, first out ). Das heißt, er beginnt mit der Task, die vorne in der Queue steht. Zu Beginn in der Fork-Phase wird diese Task neue Subtasks erzeugen. Diese Subtasks werden nacheinander vorne in der Queue abgelegt und zwar in der Reihenfolge, in der sie erzeugt werden. Das führt dazu, dass die Subtasks dann in LIFO-Reihenfolge (LIFO = last in, first out ) verarbeitet werden. Dies gilt natürlich genauso für die weiteren Stufen von Subtask-Verfeinerungen. Threads, die nichts zu tun haben, d.h. deren Auftragsqueue leer ist, holen sich eine neue Task aus der Queue eines anderen Threads ( Workstealing ). Dabei nehmen sie sich die Task, die hinten am Ende in der Queue steht.
Die Idee hinter diesem Designansatz ist es, mit Hilfe von Workstealing eine möglichst gleiche Auslastung aller zur Verfügung stehenden Threads zu erreichen. Die Auftragsqueue wird dabei in der oben beschriebenen Weise als Deque genutzt. Der Effekt ist, dass ein Thread seine Tasks erst einmal in die Tiefe verfeinert (Fork-Phase). Sollte ein anderer Thread aus der Queue des ersten Threads eine Task per Workstealing übernehmen, so ist dies eine Task, die hinten in der Queue steht. Das bedeutet wiederum, dass diese Task früh abgespalten worden ist, höchstwahrscheinlich schon auf der ersten Verfeinerungsstufe. Auf diese Weise sind erst einmal beide Threads längere Zeit unabhängig voneinander damit beschäftigt, ihre "große" Task in "kleinere" Subtasks zu zerlegen. Anschließend sammeln sie in der Join-Phase die Teilergebnisse ihrer eigenen Subtasks und erst am Ende müssen die Threads aufeinander warten. Die Folge dieses Workstealings ist also, dass Threads in der Join-Phase eher selten auf die Ergebnisse von Tasks warten müssen, die in anderen Threads ausgeführt wurden. Alle Threads können relativ unabhängig von einander ihre Tasks bearbeiten.
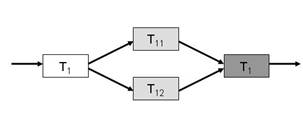
Abbildung 3: Struktur der Fork-Join-Task T1
Das ist soweit der theoretische Ansatz. Im Detail gibt es aber
noch ein paar kleine Optimierungen. Schauen wir uns deshalb den Ablauf
(einschließlich Optimierungen) an einem Beispiel an. Nehmen
wir an, die relativ einfache Task
T1
aus Abbildung 3 wird von
einem
ForkJoinPool
mit zwei Threads verarbeitet.
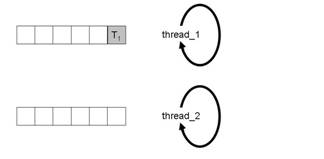
Abbildung 4a: Ausgangssituation
Nach dem Start befindet sich die Task T1 in der Queue von thread_1 (Abbildung 4a).
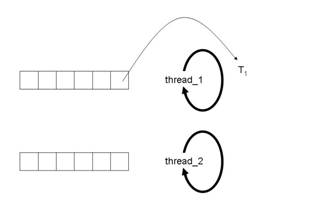
Abbildung 4b: Start der Bearbeitung von Task
T1
thread_1 liest die Task T1 vorne aus der Queue und beginnt mit ihrer Bearbeitung (Abbildung 4b).
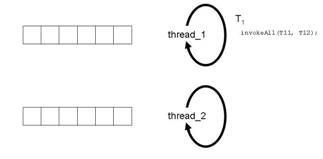
Abbildung 4c: Aufruf von
invokeAll(T11,T22)
Irgendwann im Code der Task T1 kommt die Stelle, an der gesagt wird, dass die beiden Subtasks T11 und T12 abgespalten ( fork ) und ausgeführt werden sollen. Es gibt dazu verschiedene Methoden der ForkJoinTask . Wir verwenden hier in unserem Beispiel invokeAll(T11, T12) (Abbildung 4c). ).
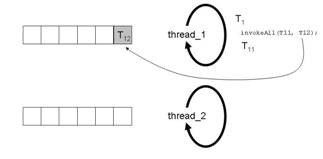
Abbildung 4d: Effekte des Aufruf von
invokeAll(T11,T22)
invokeAll(T11,T12) hat zur Folge, dass die Subtask T12 vorne in der Queue von thread_1 abgelegt wird. Anders als oben in der Grobbeschreibung dargestellt, wird T11 aber gar nicht erst in die Queue gelegt. thread_1 führt vielmehr T11 gleich selbst aus (siehe Abbildung 4d). Dies ist natürlich eine Optimierung, damit thread_1 die Task T11 nicht erst in die Queue legen muss, um sie dann sofort wieder heraus zu holen.
Um Sonderfälle (bei denen die Tasks keine Fork-Join-Struktur haben) zu unterstützen, kann das in Abbildung 4d beschriebene Verhalten so umkonfiguriert werden, dass die neue Tasks hinten in der Queue abgelegt werden. Dies sei nur der Vollständigkeit halber erwähnt; wir werden im Weiteren aber nicht mehr darauf eingehen.
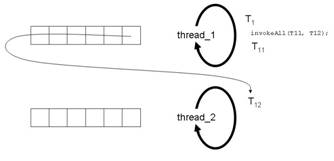
Abbildung 4e: Workstealing von Task
T2
Der thread_2 findet in der Queue von thread_1 die wartende Task T12 . Er nimmt diese hinten aus der Queue ( Workstealing ) und führt sie aus (siehe Abbildung 4e).
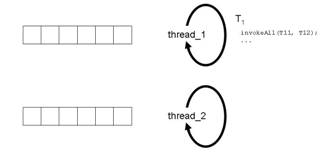
Abbildung 4f: Join-Phase von Task
T1
Der Aufruf von invokeAll(T11,T12) kehrt zurück, wenn T11 und T12 vollständig ausgeführt worden sind. Nun kommt die in unserem Beispiel recht kurze Join-Phase. T1 sammelt die Ergebnisse von T11 und T12 ein und wertet sie aus (siehe Abbildung 4f).
Für die Implementierung der Auftragsqueue wird keine der Datenstrukturen aus dem JDK verwendet, die ein Deque-Verhalten unterstützt. Stattdessen sind die Elemente der Queue, wie das Array, das die ForkJoinTask s speichert, die Indizes, die auf den Anfang bzw. das Ende der Daten in der Queue verweisen, usw. Felder in der Klasse ForkJoinWorkerThread . Hier spielt Performance die höchste Priorität bei der Implementierung. Zugriffe auf den Inhalt des Arrays, das die Queue repräsentiert, werden zum Beispiel mit Hilfe der Klasse sun.misc.Unsafe gemacht, die einen direkten, ungecheckten Speicherzugriff ähnlich wie in C oder C++ durchführen. Das ist natürlich äußerst performant aber gemessen an den sonst üblichen Java-Sicherheitsstandards ziemlich gefährlich. So wird etwa beim direkten, ungecheckten Speicherzugriff nicht geprüft, ob der Zugriff wirklich innerhalb der Array-Grenzen liegt.
Auch die Thread-Synchronisationsmechanismen fallen so leichtgewichtig wie möglich aus. Entsprechend werden die Garantien des Java-Memory-Modells bis ins Letzte ausgenutzt. Kommentare im Source-Code wie: "Variable queueTop need not be volatile because non-local reads always follow those of queueBase ." machen dies deutlich.
Doug Lea scheint es selbst etwas unwohl bei dem gewählten Trade-Off
zugunsten der Performance und gegen die Wartbarkeit zu sein. Der
Satz, der die Beschreibung dieser
Hacks
im Kommentar des Source-Codes
einleitet, lautet nämlich: "Efficient implementation of these algorithms
currently relies on an uncomfortable amount of
unsafe
mechanics."
Zusammenfassung und Ausblick
In diesem Beitrag haben wir die Prinzipien des Fork-Join-Frameworks angeschaut. Es handelt sich um einen speziellen Threadpool für Tasks, die sich in einer Fork-Phase in Teilaufgaben zerlegen lassen und für die anschließend in einer Join-Phase die Ergebnisse dieser Teilaufgaben aufgesammelt und zu einem Gesamtergebnis zusammen geführt werden. Aufgaben mit solchen speziellen Abhängigkeiten lassen sich weder mit normalen Threads noch mit dem Standard ThreadPoolExecutor sinnvoll und performant abarbeiten. Deshalb gibt es den ForkJoinPool als neue Abstraktion in Java 7. Wir haben uns die Interna des ForkJoinPool s näher angesehen, insbesondere die Technik des Workstealings, die für eine möglichst gleichmäßige Verteilung der Tasks auf die verfügbaren Poolthreads sorgt.Wichtig ist der Fork-Join-Framework als Instrument für eine feingranulare Parallelisierung von Aufgaben. In den heute vorherrschenden Multicore-Architekturen besteht eine zentrale Aufgabe beim Software-Design darin, dutzende (oder zukünftig hunderte) von Prozessorkernen zu nutzen. Mit der Aufteilung der Arbeit in relativ grobgranulare Tasks lassen sich nur relativ wenig Cores auslasten. Deshalb geht der Trend dahin, nach feingranularen Tasks zu suchen, um möglichst viele Verarbeitungen in möglichst viele parallele Teilaufgaben zu zerlegen. Der Fork-Join-Framework leistet hier einen Beitrag, indem er die Möglichkeit bietet, eine spezielle Art von Aufgaben von mehreren Threads (und somit von mehreren Cores) parallel auszuführen.
Im nächsten Beitrag werden wir dies noch ausführlicher diskutieren,
wenn wir den Fork-Join-Framework an einem Beispiel nutzen. Zusätzlich
werden wir uns ansehen, welche Rolle der Framework bei der Implementierung
zukünftiger JDK-Abstraktionen spielen wird.
Literaturverweise
| /JSR166/ |
Doug Lea: Concurrency JSR-166 Interest Site
URL: http://gee.cs.oswego.edu/dl/concurrency-interest/ |
| /TPE/ |
Klaus Kreft & Angelika Langer
Java Multithread Support: Threadpools URL: http://www.angelikalanger.com/Articles/EffectiveJava/20.ThreadPools/20.ThreadPools.html |
Die gesamte Serie über Java 7:
| /JAVA7-1/ |
Java 7 - Überblick
Klaus Kreft & Angelika Langer, Java Magazin, Juni 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/57.Java7.Overview/57.Java7.Overview.html |
| /JAVA7-2/ |
JSR 334 - "Project Coin" (Strings in switch,
Exception Handling, ARM, numerische Literale)
Klaus Kreft & Angelika Langer, Java Magazin, August 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/58.Java7.Coin1/58.Java7.Coin1.html |
| /JAVA7-3/ |
JSR 334 - "Project Coin" (Sprachneuerungen im
Zusammenhang mit Generics)
Klaus Kreft & Angelika Langer, Java Magazin, Oktober 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/59.Java7.Coin2/59.Java7.Coin2.html |
| /JAVA7-4/ |
JSR 203 - "NIO2" (Erweiterung der I/O Funktionalität)
Klaus Kreft & Angelika Langer, Java Magazin, Dezember 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/60.Java7.NIO2/60.Java7.NIO2.html |
| /JAVA7-5/ |
JSR 166y - Fork-Join-Framework (Teil 1: Internals)
Klaus Kreft & Angelika Langer, Java Magazin, Februar 2012 URL: http://www.angelikalanger.com/Articles/EffectiveJava/61.Java7.ForkJoin.1/61.Java7.ForkJoin.1.htm |
| /JAVA7-6/ |
JSR 166y - Fork-Join-Framework (Teil 2: Benutzung)
Klaus Kreft & Angelika Langer, Java Magazin, April 2012 URL: http://www.angelikalanger.com/Articles/EffectiveJava/62.Java7.ForkJoin.2/62.Java7.ForkJoin.2.htm |
| /JAVA7-7/ |
Thread-Synchronisation mit Hilfe des Phasers
Klaus Kreft & Angelika Langer, Java Magazin, Juni 2012 URL: http://www.angelikalanger.com/Articles/EffectiveJava/63.Java7.Phaser/63.Java7.Phaser.htm |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||||
Seminar
|
||||