| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Memory Management
Old Generation Garbage Collection – Concurrent-Mark-Sweep (CMS)
Java Magazin, August 2010
|
Dies ist das Manuskript eines Artikels, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Im letzten Beitrag (siehe /
GC3
/) haben wir diskutiert,
wie die Garbage Collection auf der Old Generation funktioniert und habe
den seriellen und parallelen Mark-and-Compact-Algorithmus erläutert.
Dieser Algorithmus hat viele Vorteile, aber einen gravierenden Nachteil:
er führt zu „Stop-the-World“-Pausen, die die Applikation blockieren.
Deshalb gibt es eine Alternative, die die Pausenzeiten reduziert, indem
der Garbage Collector so viel wie möglich konkurrierend zur Applikation
erledigt, ohne die Applikations-Threads anzuhalten. Diesen konkurrierenden
Algorithmus wollen wir uns in diesem Beitrag ansehen.
Concurrent Mark-and-Sweep
Unter konkurrierender Garbage Collection versteht man Algorithmen, die konkurrierend zur Anwendung ablaufen, ohne deren Threads anzuhalten. Das geht natürlich nicht vollständig. Die Markierung der erreichbaren Objekte wird zumindest zu einem kleinen Teil ungestört ablaufen müssen, damit der Garbage Collector durch Verfolgung der Referenzbeziehungen verlässlich alle überlebenden Objekte bestimmen kann. Dies ist nicht verlässlich möglich, solange die Anwendung die Referenzbeziehungen gleichzeitig ändert. Eine konkurrierende Garbage Collection ist daher immer quasi-konkurrierend.
In der JVM von Sun ist der konkurrierende Algorithmus auf der Old Generation
ein Mark-and-Sweep-Algorithmus, d.h. er führt keine Kompaktierung
durch. Das liegt daran, dass das Verschieben von Objekten und das
Anpassen der Referenzen auf die verschobenen Objekte konkurrierend zur
Applikation nicht sinnvoll machbar sind. Deshalb ist bei diesem Algorithmus
die Fragmentierung des Speichers mit allen bereits diskutieren Nachteilen
unvermeidlich (siehe /
GC2
/).
Der Concurrent-Mark-and-Sweep-Algorithmus (kurz „CMS“ genannt) verläuft
in 4 Phasen:
- Initial Marking.
- Concurrent Marking.
- Remarking.
- Concurrent Sweep.
Concurrent Marking . Danach folgt eine konkurrierende Markierungsphase, in der alle erreichbaren Objekte markiert werden. Das Ergebnis ist allerdings nicht exakt. Während die Referenzen verfolgt werden, entstehen durch die Aktivitäten der Anwendung neue Root-Referenzen und neue Referenzbeziehungen, die bei der Markierung nicht berücksichtigen wurden. Das heißt, es können mittlerweile Objekte erreichbar sein, die nicht markiert worden sind, z.B. weil sie von der Anwendung neu erzeugt wurden und ihre Referenzen existierenden Objekten zugewiesen wurden. Um mit dieser Situation fertig zu werden, müssen die Anwendung und der Garbage Collector kooperieren. Bei Referenzzuweisungen, die in der Anwendung ausgelöst werden, wird eine sogenannte Write Barrier ausgeführt; dabei wird Informationen für die nachfolgenden Phasen der Garbage Collection hinterlegt.
Remarking . Nach dem konkurrierenden Markieren erfolgt eine abschließende nicht-konkurrierende Re-Markierungsphase, in der versucht wird, die erwähnten Defizite der vorangegangenen konkurrierenden Phase auszubügeln. Es werden insbesondere die von der Anwendung zwischenzeitlich geänderten Referenzen verfolgt, weil sie auf neu entstandene, bislang noch nicht markierte Objekte verweisen könnten. Dabei geht es um genau die Referenzen, die zuvor mittels der Write Barrier vermerkt worden sind. Nach diesen Remarkierungsarbeiten ergibt sich ein Referenzgraph, der garantiert alle lebendigen Objekte enthält. Darüber hinaus enthält er möglicherweise aber auch Objekte, die zwischenzeitlich unerreichbar geworden sind. Sie werden fälschlicherweise als „lebendig“ beurteilt, obwohl sie schon „tot“ sind. Man bezeichnet diese Zombies als Floating Garbage Sie stellen kein großes Problem dar; sie bleiben einfach länger im Speicher als nötig und werden erst bei der nächsten Garbage Collection freigegeben.
Concurrent Sweep
. Nach den Markierungsphasen folgt eine konkurrierende
Sweep-Phase. Wie schon erwähnt, wird nicht kompaktiert.
Das liegt daran, dass die Kompaktierung Synchronisation zwischen dem Garbage-Collector
und den Threads der Anwendung erfordern würde. Beide arbeiten
ja gleichzeitig auf dem Heap und müßten sich koordinieren.
Für einen Sweep hingegen, also die einfache Freigabe der „toten“ Objekte,
ist keine Koordination nötig, weil die „toten“ Objekte von der Anwendung
aus ohnehin nicht mehr zu erreichen sind.
Ohne die Kompaktierung besteht natürlich wieder die Gefahr der
Speicherfragmentierung und die Speicherallokation wird teuer. Damit
möglichst rasch Speicher in der richtigen Größe gefunden
wird und die Löcher möglichst lückenlos geschlossen werden,
werden separate Free-Listen für unterschiedliche Objektgrößen
verwaltet. Im Zusammenhang mit der Verwaltung der Free-Listen wird
auch versucht, nebeneinander liegende kleine Speicherbereiche zu einem
größeren Bereich zusammen zu fassen, um zu vermeiden, dass es
am Ende nur noch Platz für Objekte geringer Größe gibt.
Die verschiedenen Phasen der konkurrierenden Garbage Collection können anhand der JVM-Ausgaben über die Optionen –verbose:GC und –XX:+PrintGCDetails verfolgt werden (siehe Abbildung 1).

Abbildung 1: Information zur Concurrent Mark-and-Sweep (CMS) Garbage Collection per JVM-Option –XX:+PrintGCDetails
Preclean . In der Ausgabe sieht man, dass es zusätzlich noch eine konkurrierende Preclean-Phase vor der nicht-konkurrierenden Remark-Phase gibt. Diese Phase dient dem Zweck, die nachfolgende Stop-the-World-Pause der Remark-Phase zu verkürzen.
Während der konkurrierenden Markierungsphase werden, wie oben bereits geschildert, von der Applikation die Referenzbeziehungen geändert und diese Änderungen werden mittels einer Write Barrier für die spätere Remark-Phase vermerkt. Dieser Merker für die Remarkierung wird in Form eines Dirty-Bits für den Bereich abgelegt, in dem sich das Objekt befindet, von dem die geänderte Referenzbeziehung ausgeht. Die Referenzen aus diesen „dirty“Bereichen heraus werden in der Remark-Phase erneut verfolgt, weil über sie bislang noch nicht markierte Objekte erreichbar geworden sein könnten.
Zwischen der initialen Markierung und der späteren Remarkierung vergeht in der Regel viel Zeit. Wenn die Applikation in dieser konkurrierenden Markierungsphase sehr aktiv ist und sehr viele „dirty“-Bereiche entstehen, dann gibt es in der nicht-konkurrierenden Remark-Phase sehr viel zu tun und die Stop-the-World-Pause wird entsprechend lang werden. Um die Arbeitsmenge beim Remarking zu reduzieren und die Stop-the-World-Pause zu verkürzen, gibt es die zusätzliche Preclean-Phase.
In der Preclean-Phase wird ähnlich wie in der anschließenden Remark-Phase ein Remarking durchgeführt, das aber anders als das eigentliche Remarking konkurrierend abläuft. Weil die Anwendung dabei weiterhin die Referenzbeziehungen ändert, werden natürlich während der Preclean-Phase wieder neue „dirty“-Bereiche entstanden sein. Trotzdem sollte die Menge der „dirty-Bereiche“ kleiner geworden sein, da die Preclean-Phase verglichen mit der konkurrierenden Markierungsphase sehr viel kürzer ist; die Anwendung hat einfach nicht so viel Zeit gehabt, „dirty“-Bereiche zu produzieren. Damit bleibt für die anschließende nicht-konkurrierende Remark-Phase weniger zu tun und die Pause fällt entsprechend kürzer aus, als sie ohne die zusätzliche Preclean-Phase gewesen wäre.
Das Precleaning verläuft wenn nötig iterativ, d.h. es läuft sogar mehrmals ab, bis in Summe ein Zeitlimit erreicht ist, das man mit der Option –XX:CMSMaxAbortablePrecleanTime=<millis> einstellen kann; der Default ist 5000 ms. Abbildung 2 zeigt den Abbruch des Precleaning bei Erreichen des Zeitlimits.
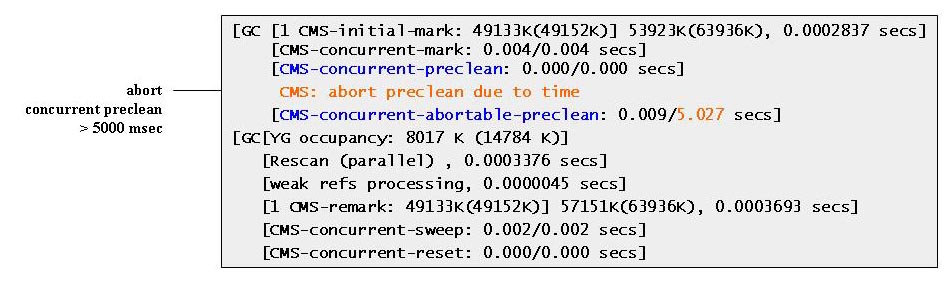
Abbildung 2: CMS-Zyklus mit abgebrochener Preclean-Iteration
Parallele Threads in CMS
Die nicht-konkurrierende Remark-Phase wird übrigens seit Java 5 von mehreren Garbage-Collection-Threads parallel ausgeführt, vorausgesetzt die Maschine hat mehrere CPUs oder Kerne. Dadurch wird die Stop-the-World-Pause während der Remarkierung weiter verkürzt. Die Remark-Phase ist automatisch parallel, wenn die Maschine mehrere CPUs oder Kerne hat. Per Default ist die Zahl der verwendeten Threads gleich der Zahl der verfügbaren Prozessoren bzw. Prozessorkernen. Man kann die Zahl der parallelen Threads aber auch mit der Option -XX:ParallelGCThreads=<n> selbst bestimmen. Falls auf der Maschine noch andere Applikationen laufen, wird man die Zahl der parallelen Garbage-Collection-Threads eventuell reduzieren wollen.Seit Java 6 kann auch in der konkurrierenden Markierungsphase parallel mit mehreren Garbage-Collection-Threads gearbeitet werden. Das Ziel ist dabei, die Zeit zwischen den Sweep-Phasen zu verkürzen, um so die Belastung für den CMS-Collector zu reduzieren. Man kann diese Parallelität während der konkurrierenden Markierungsphase mit der Option –XX:+CMSConcurrentMTEnabled einschalten und die Zahl der parallelen Threads mit der Option -XX:ParallelCMSThreads=<n> selbst bestimmen. Dabei sollte man aber bedenken, dass jede CPU, die in dieser Phase vom Garbage Collector verwendet wird, anderseits der Applikation fehlt, weil beide gleichzeitig laufen. Wenn man die Option -XX:ParallelCMSThreads=<n> nicht angibt, wird der Default für die Zahl der in dieser konkurrierenden Markierungsphase verwendeten Garbage-Collection-Threads abhängig von der Zahl gewählt, die mit der Option -XX:ParallelGCThreads=<n> angegeben wurde: es wird in etwa ein Viertel der ParallelGCThreads verwendet. Details zur Zahl der verwendeten Threads findet man in / MASA /.
In den anderen Phasen – Initial Marking und Sweep - ist nur jeweils ein Garbage-Collection-Threads aktiv.
Synchronisationsbedarf und Interaktion mit der Young-Generation-Garbage-Collection
Einige Komplikationen und Aufwände ergeben sich in den konkurrierenden Phasen dadurch, dass nicht nur die Applikation weiterarbeitet und die Referenzbeziehungen ändert, sondern auch eine Young-Generation-Garbage-Collection laufen kann, die durch Promotion neue Objekte in der Old Generation anlegt. Diese neuen Objekte müssen bei der Markierung berücksichtigt und korrekt verfolgt werden. Auch dürfen sie nicht versehentlich in der Sweep-Phase für „tot“ gehalten und weggeworfen werden. Das heißt, sie müssen korrekt in die Datenstrukturen des CMS-Collectors übernommen werden.Das geht relativ einfach, wenn die Young-Generation-Garbage-Collection nicht nur alle Threads der Anwendung anhält, sondern auch alle Threads des CMS-Collectors. Dann entstehen neue Objekte in der Old Generation nicht konkurrierend, sondern in den Stop-the-World-Pausen der Young-Generation-Garbage-Collection. Sie werden sofort nach der Promotion in die Old Generation als „lebendig“ markiert, in die Datenstrukturen entsprechend eingetragen und in den anschließenden CMS-Phasen korrekt weiter verarbeitet.
Es gibt aber Situationen, in denen der CMS-Collector nicht unterbrechbar ist, weil seine internen Datenstrukturen gerade in einem inkonsistenten Zustand sind. Außerdem gibt es noch den Sonderfall, dass ein Objekt direkt mit new in der Old Generation angelegt wird; das geschieht, wenn das zu allozierende Objekt zu groß für die Young Generation ist. In diesen beiden Fällen ist bei Zugriff auf die internen Datenstrukturen des CMS-Collectors die Synchronisation zwischen den CMS-Threads und den Applikations- bzw. Young-Generation-Garbage-Collector-Threads erforderlich.
Im Allgemeinen wird bei allen Garbage Collection Algorithmen versucht, Synchronisation zu vermeiden, wo immer es geht, weil die Synchronisation sowohl die Garbage Collection als auch die Applikation verlangsamt. Wie aber sieht, lässt sich der Synchronisations-Overhead nicht in allen Fällen vermeiden. Ebenfalls unvermeidlich ist der Rückgriff auf die serielle Full Garbage Collection mit ihrer gigantischen Stop-the-World-Pause.
Rückfall in die serielle Garbage Collection
Wenn der konkurrierende Mark-and-Sweep-Algorithmus es nicht mehr schafft, schnell genug ausreichend viel Speicher freizugeben, dann droht der Programmabbruch mit einem java.lang.OutOfMemoryError. Ehe das passiert, wird auf den seriellen Mark-and-Compact-Algorithmus zurückgegriffen. Deshalb beobachtet man bei extremen Speicherengpässen (vor einem Out-of-Memory-Abbruch) einige ganz lange Stop-the-World-Pausen, in denen die JVM versucht, den Abbruch zu verhindern, indem sie dem unkomplizierten seriellen Algorithmus eine Chance gibt. Abbildung 3 zeigt die Ausgaben einer JVM in einer solchen Situation.

3: Serielle Full GC im Falle von Speicherengpässen (JVM-Ausgaben
per Option
–XX:+PrintGCDetails
)
Vor- und Nachteil des CMS-Collectors
Der Vorteil der konkurrierenden Garbage Collection auf der Old Generation ist die erhebliche Verkürzung der Stop-the-World-Pausen. Natürlich hat der CMS-Algorithmus auch eine Reihe von Nachteilen.- Geringerer Durchsatz. Der Concurrent-Mark-and-Sweep-Algorithmus ist aufwändig, wie man schon an der Vielzahl der Phasen und den oben angedeuteten Komplikationen erahnen kann. Die Anwendung als Ganzes wird deshalb insgesamt mehr Zeit mit Garbage Collection verbringen und weniger mit der eigentlichen Anwendungslogik.
- Längere Young-Generation-Pausen. Die Allokation von Speicher in der Old Generation muss wegen der fehlenden Kompaktierung über Free-Listen gemacht werden. Das ist deutlich teurer als die Allokation aus einem zusammenhängend freien Speicherbereich heraus. Deshalb dauert die Promotion von Objekten aus der Young Generation in die Old Generation beim Concurrent-Mark-and-Sweep länger als beim seriellen oder parallelen Mark-and-Compact-Algorithmus.
- Mehr Speicherverbrauch. Die konkurrierende Markierungsphase des CMS-Algorithmus dauert viel länger als die Markierungsphase des Mark-and-Compact-Algorithmus. Entsprechend vergeht mehr Zeit zwischen den Phasen, in denen tatsächlich aufgeräumt und Speicher freigegeben wird. In dieser vergleichsweise langen Zeitspanne hat die Applikation länger Gelegenheit, um neue Objekte zu allozieren. Das führt insgesamt dazu, dass sich beim Concurrent-Mark-and-Sweep mehr Garbage ansammelt als beim seriellen oder parallelen Mark-and-Compact-Algorithmus. Damit der Anwendung zwischen den Sweep-Phasen nicht schon vorzeitig der Speicher ausgeht, muss der Heap größer sein, als es beim Mark-and.Compact erforderlich ist. Hinzu kommt, dass die konkurrierende Markierung nicht so exakt ist wie die serielle Markierung und deshalb Floating Garbage entsteht. Diese Zombie-Objekte werden zwar im nächsten Garbage-Collection-Zyklus weggeräumt, führen aber in jedem Zyklus zu einem erhöhten Speicherverbrauch.
- Fragmentierung . Da der CMS-Collector keine Kompaktierung macht, kann die Fragmentierung überhand nehmen, Wenn dies geschieht oder wenn an sich nicht mehr genug Heap-Speicher zur Verfügung steht, dann fällt die konkurrierende Garbage Collection wieder auf den nicht-konkurrierenden Mark-and-Compact-Algorithmus mit seinen langen Pausen zurück.
Zusammenfassung
In diesem Beitrag haben wir die konkurrierende Garbage Collection auf der Old Generation erläutert. Das Ziel der konkurrierenden Garbage Collection ist die Verkürzung der Stop-the-World-Pausen. Es wird versucht, so viel wie möglich konkurrierend zur Applikation zu erledigen, ohne deren Threads zu blockieren, und nur in möglichst kurzen Phasen die Applikations-Threads anzuhalten. Der konkurrierende Algorithmus ist ein Mark-the-Sweep-Algorithmus, der keine Kompaktierung macht und deshalb zur Fragmentierung des Speichers führen kann. Im Notfall - bei extremen Speicherengpässen - greift er auf einen seriellen Mark-and-Compact-Algorithmus mit sehr langen Stop-the-World-Pausen zurück. Der konkurrierende Mark-the-Sweep-Algorithmus ist komplex und reduziert den Durchsatz, ist aber auf Multi-Prozessor-Maschinen für viele Anwendungen empfehlenswert.Literaturverweise
| /SUN/ |
Memory Management in the Java HotSpot™ Virtual Machine
Sun Microsystems, April 2006 URL: http://java.sun.com/j2se/reference/whitepapers/memorymanagement_whitepaper.pdf |
| /PRIN/ |
A Generational Mostly-concurrent Garbage Collector
Tony Printezis and David Detlefs URL: http://research.sun.com/techrep/2000/smli_tr-2000-88.pdf |
| /MASA/ |
Did You Know ...
Jon Masamitsu's Weblog, Oct 26, 2007 URL: http://blogs.sun.com/jonthecollector/entry/did_you_know |
Die gesamte Serie über Garbage Collection:
| /GC1/ |
Generational Garbage Collection
Klaus Kreft & Angelika Langer, Java Magazin, February 2010 URL: http://www.angelikalanger.com/Articles/EffectiveJava/49.GC.GenerationalGC/49.GC.GenerationalGC.html |
| /GC2/ |
Young Generation Garbage Collection
Klaus Kreft & Angelika Langer, Java Magazin, April 2010 URL: http://www.angelikalanger.com/Articles/EffectiveJava/50.GCYoungGenGC/50.GC.YoungGenGC.html |
| /GC3/ |
Old Generation Garbage Collection – Mark-and-Compact
Klaus Kreft & Angelika Langer, Java Magazin, June 2010 URL: http://www.angelikalanger.com/Articles/EffectiveJava/51.GC.OldGen.MarkCompact/51.GC.OldGen.MarkCompact.html |
| /GC4/ |
Old Generation Garbage Collection – Concurrent-Mark-Sweep
(CMS)
Klaus Kreft & Angelika Langer, Java Magazin, August 2010 URL: http://www.angelikalanger.com/Articles/EffectiveJava/52.GC.OldGen.CMS/52.GC.OldGen.CMS.html |
| /GC5/ |
Garbage Collection Tuning – Die Ziele
Klaus Kreft & Angelika Langer, Java Magazin, Oktober 2010 URL: http://www.angelikalanger.com/Articles/EffectiveJava/53.GC.Tuning.Goals/53.GC.Tuning.Goals.html |
| /GC6/ |
Garbage Collection Tuning – Die Details
Klaus Kreft & Angelika Langer, Java Magazin, Dezember 2010 URL: http://www.angelikalanger.com/Articles/EffectiveJava/54.GC.Tuning.Details/54.GC.Tuning.Details.html |
| /GC7/ |
Der Garbage-First Garbage Collector (G1) - Übersicht
über die Funktionalität
Klaus Kreft & Angelika Langer, Java Magazin, Februar 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/55.GC.G1.Overview/55.GC.G1.Overview.html |
| /GC8/ |
Der Garbage-First Garbage Collector (G1) - Details
und Tuning
Klaus Kreft & Angelika Langer, Java Magazin, April 2011 URL: http://www.angelikalanger.com/Articles/EffectiveJava/56.GC.G1.Details/56.GC.G1.Details.html |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||||
Seminar
|
||||