| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java Performance: Micro-Benchmarking
Was ist ein Micro-Benchmark und was kann man dabei alles falsch machen?
JavaSPEKTRUM, Juli 2005
|
Dies ist das Manuskript eines Artikels, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im JavaSPEKTRUM erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Micro-Benchmarks sind Vergleichsmessungen, bei denen die Performance
verschiedener, alternativer Algorithmen gemessen und anschließend
verglichen wird, um den besseren (d.h. schnelleren) Algorithmus zu bestimmen.
Solche Messungen werden zum Beispiel im Rahmen von Tuningmaßnahmen
gemacht. Auch während der Implementierung werden solche Benchmarks
gelegentlich hilfreich, um zu entscheiden, welcher Algorithmus der schnellere
ist. In diesem Artikel sehen wir uns an, wie ein Micro-Benchmark
in Java gemacht wird und worauf geachtet werden muß, damit er aussagekräftige
Meßergebnisse liefert.
Historie
Diskussionen um Performance haben für Java seit seiner Entstehung immer schon eine große Rolle gespielt. Das liegt sicherlich daran, daß der Name Java nicht nur für eine Programmiersprache, sondern auch für ein Laufzeitsystem steht. Gerade dieses Laufzeitsystem, dessen Kern eine Virtuelle Maschine ist, die auf verschiedensten Systemplattformen zur Verfügung steht, war in den Kindertagen von Java nicht unumstritten was Performance anging.Es war zwar ein überzeugendes Konzept, eine portable Ablaufumgebung zu Verfügung zu stellen und damit die Plattformproblematik ein für alle Mal zu neutralisieren. Skeptiker aber stellten sich die Frage, ob die Performance einer solchen Lösung überhaupt annähernd vergleichbar mit den damals benutzten Programmiersprachen C und C++ sein könnte. Manche glaubten damals, daß Java einen technisch interessanten Ansatz darstellt, aber daß es nur eine Zukunft in einigen Nischen haben werde, in denen die Vorteile besonders zu Geltung kommen.
Mittlerweile hat sich natürlich gezeigt, daß die Performance
von Java ausreicht, um selbst anspruchsvolle Serverlösungen damit
zu realisieren. Die Tatsche, daß Microsoft mit .NET eine in vielen
Aspekten ähnliche Technologie nachgezogen hat, zeigt, daß der
Ansatz von Java heute allgemein akzeptiert ist.
Heute
Trotzdem ist Performance und Java immer noch ein Thema, wenn auch kein so grundsätzliches wie vor zehn Jahren. Heute haben sich die Wogen etwas geglättet und das Thema besteht eher aus einer Fülle von Details. Teilweise sind diese Details an besondere Java-Technologien gebunden. Man denke nur an die geradezu unendliche Diskussion, wie man die performanteste Lösung im Zusammenhang mit EJBs und Persistenz erhält: beans-managed, container-managed, ohne Entity-Beans und stattdessen mit JDO, ... .
Wir wollen in unseren nächsten Artikeln das Thema Performance und
Java genauer unter die Lupe nehmen. Dabei werde wir uns, wie in den Kolumnen
bisher immer, auf die Themen konzentrieren, die zur Kerntechnologie von
Java (sprich dem JDK bzw. J2SE) gehören. Spezifische Themen wie etwa
die Persistenz bei EJBs (Beispiel oben) werden wir hier nicht behandeln.
Messen und Analysieren
Die nicht ausreichende Performance einer Softwarelösung zeigt sich meist erst am (fast) fertigen System. Dann, wenn alle Teile des Systems zum ersten Mal zusammen in Aktion sind, kommt (zumindest bei Systemen mit Benutzeroberfläche) ganz intuitiv das Urteil: schnell genug oder (viel) zu langsam. Wenn das Urteil ‚zu langsam’ lautet, ist in den meisten Fällen erst einmal guter Rat teuer. Denn die Frage, die sich stellt, ist: Wo klemmt es eigentlich? Nur in den seltensten Fällen wird nach dem ersten betretenen Schweigen eine Person aus dem Team schuldbewußt die Stimme erheben und sagen: „Ich hab da noch einen sleep() von zwei Sekunden nach jedem Event drin. Den habe ich reingebaut, weil sonst die Trace-Ausgabe immer so schnell am Bildschirm durchläuft. Vielleicht sollte ich den mal rausnehmen ...“ So einfach lassen sich Performance-Probleme in der Realität leider selten identifizieren und beseitigen.Das heißt, in den meisten Fällen geht es bei Feststellung eines Performance-Problems erst einmal darum, Daten über/aus dem System zu ermitteln und diese intelligent zu analysieren, um das Potential für Tuningmaßnahmen zu finden. Diese Tätigkeit des System-Profiling, speziell in einem Java Umfeld, werden wird uns in einer der nächsten Kolumnen genauer ansehen.
Gehen wir in unserem Fall einfach mal davon aus, daß das Profiling
uns auf eine Stelle im Sourcecode gebracht hat, wo wir durch Benutzung
eines anderen Algorithmus die Performance verbessern möchten. Möglicherweise
ist die Entscheidung für den anderen Algorithmus auch gar nicht so
einfach, weil Kombination aus beiden Algorithmen vielleicht eine noch performantere
Lösung sein könnte.
Benchmarking
Um hier den richtigen Ansatz auszuwählen, werden wir nicht um erneute Messungen mit den verschiedenen Alternativen herumkommen. Dazu wollen wir natürlich ungern je eine vollständige Lösung auf Basis der verschiedenen Algorithmen implementieren, um dann damit jeweils ein System-Profiling durchzuführen. Stattdessen würden wir gerne ganz isoliert die Performance der verschiedenen Algorithmen in einer für unser System relevanten Benutzungsform messen. Dies ermöglicht es, die Algorithmen bezüglich der Performance zu vergleichen und den für uns besten auszuwählen. Ein solches Vorgehen nennt sich Micro-Benchmarking. ‚Micro’ deshalb, weil die Messung sich nur auf einen kleinen, aber für unsere augenblicklichen Untersuchungen wichtigen Teil des Gesamtsystems bezieht.
Da stellt sich natürlich die Frage, was ist dann Macro-Benchmarking?
Ein Macro-Benchmark ist ein Benchmark, bei dem das ganze System betrachtet
wird, nicht nur ein einzelner Aspekt oder Algorithmus wie beim Micro-Benchmarking.
Solche Macro-Benchmarks werden zum Beispiel benutzt, um die Ablaufumgebung
(JVM, EJB Container, etc.) für das System auszuwählen. In einem
Macro-Benchmark würde dann beispielsweise die Performance des gesamten
Systems auf einer JVM gemessen und mit der Performance auf einer anderen
JVM verglichen.
Micro-Benchmarking
In dieser Kolumne wollen wir uns aber jetzt im Detail mit dem Micro-Benchmarking befassen. Bei einem Micro-Benchmark wird versucht, die Essenz verschiedener alternativer Implementierungen in je einem kleinen Programmstück zu erfassen. Dann läßt man diese kleinen Programmstücke wiederholt ablaufen, typischerweise mit einem sehr hohen Wiederholungsfaktor, um Meßungenauigkeiten auszugleichen. Dabei werden Zeitmessungen gemacht. Die gemessenen Zeiten geben anschließend Auskunft über die Performanz der alternativen Implementierungen.
Beim Aufsetzen eines Micro-Benchmarks kann man allerlei Fehler machen.
Die Fehler können unterschiedlicher Natur sein. Einige Fehlerquellen
haben oft gar nichts Java zu tun, sondern sind ganz allgemeiner Natur.
Andere Fehlerquellen sind Java-spezifisch.
Fehler beim Micro-Benchmarking – ganz allgemein, unabhängig von Java
Sehen wir uns zunächst die allgemeinen Fehler beim Micro-Benchmarking an.Falsche Annahmen über das Problem.
- Man muß darauf achten, daß nicht von falschen Annahmen ausgegangen wird. Wenn sich zum Beispiel eine Anweisung wie println ("bla-bla" + x + y + "more bla-bla" + z + "even more") beim System-Profiling als Performance-Bremse herausgestellt hat, dann könnte man auf den Gedanken kommen, daß das println Schuld ist und einen Benchmark für Alternativen zu println machen. Möglicherweise ist das aber völlig falsch, weil das eigentliche Problem die String-Konkatenierung ist. Man muß sich also gut überlegen, ob man auch das eigentliche Problem erwischt hat und nicht etwa versehentlich einen völlig irrelevanten Aspekt.
- Das für den Benchmark erstellte Programmstück muß einen repräsentativen Testfall darstellen. Beispielsweise muß darauf geachtet werden, daß etwaige Input-Daten korrekt und sinnvoll sind. Wenn man zum Beispiel die Serialisierung eines String-Arrays benchmarken will, dann macht es wenig Sinn, wenn man als Testdaten ein Array verwendet, bei dem alle Elemente gleich sind, während in einer echten Anwendung die Elemente typischerweise alle verschieden sind. Die so erhaltenen Meßergebnisse werden wenig Aussagekraft haben, weil der Testfall nicht repräsentativ war.
- Es kann passieren, daß versehentlich Setup-Tätigkeiten oder Initialisierungen mit in die Messung einbezogen werden und das Meßergebnis verfälschen. Das gleiche gilt für Cleanup-Tätigkeiten. Solch eine Verfälschungen kann beispielsweise vorkommen, wenn ein Objekt seine Attribute per Lazy Evaluation initialisiert, d.h. die Initialisierung wird nicht gleich im Konstruktor gemacht, sondern erst später, wenn das Attribut zum ersten Mal benutzt wird. Das macht man gerne, wenn die Attribut-Initialisierung recht teuer und aufwendig ist. Dann kann es passieren, daß diese aufwendige, verzögerte Initialisierung mit in die Messung einbezogen ist, obwohl man nicht die Initialisierung, sondern ganz etwas anderes messen wollte.
- Die Erzeugung der Testdaten für eine Messung ist meistens recht aufwendig und sollte nicht versehentlich mit in die Messung einbezogen werden. Das kann leicht passieren. Das zu messende Programmstück wird in der Regel in einer Schleife wiederholt ausgeführt. Wenn die Testdaten in jeder Iteration neu erzeugt werden, dann geht unweigerlich die Testdaten-Erzeugung in die Messung ein und verfälscht das Ergebnis.
Wie man sieht, sind diese Fehlerquellen überhaupt nicht Java-spezifisch.
Aber natürlich hat das Micro-Benchmarking von Java-Programmen auch
sprachspezifische Aspekte. Beispielsweise die Zeitmessung.
Wie messe ich die Zeit in Java?
Zeitmessung fürs Micro-Benchmarking
Für eine Performancemessung im Rahmen eines Benchmarks will man vor und nach dem Ausführen des interessanten Programmstücks die jeweils aktuelle Zeit nehmen. Die Differenz liefert dann die Ausführungszeit des zu messenden Programmteils.Für die Ermittlung der aktuellen Zeit sollte man auf keinen Fall die Klasse java.util.Date verwenden. Zwar bekommt man über den No-Argument-Konstruktor, d.h. mit new Date(), eine Repräsentation der aktuellen Zeit, aber es muß ein relativ schwergewichtiges Date-Objekt erzeugt werden. Die Allokation und Initialisierung des Date-Objekts verfälschen u.U. das Meßergebnis.
Die bessere Alternative ist die Methode java.lang.System.currentTimeMillis(). Sie liefert in Millisekunden die Differenz zwischen der aktuellen Zeit und Mitternacht am 1. Januar 1970. Gegenüber der Konstruktion eines Date Objekts ist die Ermittlung eines long-Werts über System.currentTimeMillis() sehr schnell und erzeugt keinen nennenswerten Overhead.
Hier ein Beispiel für einen Micro-Benchmark, der die Performance des Schreibens über einen BufferedWriter mißt:
Writer os = new BufferedWriter(new FileWriter(FILENAME), bufsize);
long start = System.currentTimeMillis();
for (int i=0; i<LOOP_SIZE; i++)
os.write( (int) 'A');
long diff = System.currentTimeMillis() - start;
os.close();
Man sieht, daß der Setup (das Erzeugen des BufferedWriter Objekts) und der Cleanup (das Schließen des BufferedWriters) nicht in die Messung einbezogen sind. Man sieht auch, daß der zu messende Aufruf der write()-Methode in einer Schleife häufig wiederholt wird. Diese Wiederholung gleicht mögliche Schwankungen aus, die durch andere Aktivitäten im System hervorgerufen werden können, und führt zu einem Mittelwert, der aussagekräftiger ist, als es bei einer einzelnen Messung möglich wäre.
Bei der Zeitmessung über System.currentTimeMillis() muß man beachten, daß die Zeitangabe zwar in Millisekunden ausgedrückt ist, die Angabe aber unter Umständen nicht auf Millisekunden genau ist. Das liegt daran, daß manche Betriebssysteme und Hardware die Systemzeit nur mit einer Genauigkeit von 10 oder 50 msec messen. In einem solchen Fall ist darauf zu achten, daß das zu messende Programmstück lang genug läuft, damit der Meßwert nicht durch die Ungenauigkeit der Zeitmessung verfälscht ist.
Seit dem JDK 5.0 gibt es die Methode System.nanoTime(), die den aktuellen Wert des System-Timers mit höherer Präzision, nämlich in Nanosekunden, liefert. Genauso wie bei System.currentTimeMillis() ist nicht garantiert, daß sich die Systemzeit tatsächlich im Nanosekunden-Takt ändert.
Beide Methoden liefern einen Zeitwert, mit dem sich die sogenannte Elapsed Time (= die tatsächlich vergangene Zeit) messen läßt. Man kann alternativ aber auch die verbrauchte CPU-Zeit messen. Dazu gibt es seit dem JDK 5.0 die Methode getCurrentThreadCpuTime() der Management-Bean java.lang.management.ThreadMXBean. Diese Methode liefert die CPU-Zeit des aktuellen Threads in Nanosekunden. Wie bei System.nanoTime() ist die Genauigkeit der Angabe abhängig von der Genauigkeit, mit der das jeweilige Betriebsystem bzw. die Hardware die Zeit mißt, und muß keineswegs auf Nanosekunden genau sein.
Ob ein Unterschied zwischen verbrauchter CPU-Zeit und der Elapsed Time besteht, hängt von der Art der gemessenen Tätigkeit ab. Für eine sehr CPU-intensive Tätigkeit, wie etwa eine numerische Berechnung, wird die verbrauchte CPU-Zeit sehr nah an der Elapsed Time liegen, wenn der Benchmark im wesentlichen die einzige Aktivität auf der Testhardware ist. Für eine I/O oder netzlastige Aufgabe wird das anders sein; da wird wesentlich mehr Zeit vergehen als CPU-Zeit beansprucht wird, d.h. die Elapsed Time wird deutlich größer als die CPU-Zeit sein. Wenn man CPU-Zeit und Elapsed Time vergleicht, bekommt man Aussagen über die Charakteristik des ausgemessenen Algorithmus: nutzt er die CPU gut aus oder wartet er die meiste Zeit auf irgend etwas.
Da es beim Micro-Benchmarking um den Vergleich von zwei Algorithmen geht, kann man sowohl die CPU-Zeit als auch die Elapsed Time für den Vergleich heranziehen. Beim Micro-Benchmark geht es um einen Vergleichswert für zwei verschiedene Algorithmen - und den liefern beide Meßarten.
Wer nicht mit Java 5.0 arbeitet, sondern mit älteren JDK-Versionen,
kann sich die CPU-Zeit auch über Funktionen des unterliegenden Betriebsystems
besorgen, indem diese über JNI aufgerufen werden. Eine solche
Lösung ist in /
JNI
/ beschrieben. Alternativ
kann man die CPU-Zeit auch über das Java Virtual Machine Profiler
Interface (JVMPI) besorgen. Eine solche Lösung ist in /
JVMPI
/
gezeigt.
Java-spezifische Fehler beim Micro-Benchmarking
Wir haben oben auf ganz allgemeine, sprachunabhängige Fehlerquellen beim Micro-Benchmarking hingewiesen. Was bedeuten diese allgemeinen Hinweise, wenn ein Stück Java-Code einem Benchmark unterzogen wird? Wir haben oben beispielsweise gesagt, daß repräsentative Testdaten gebraucht werden. Aber was heißt das im konkreten Fall? Um zu beurteilen, was ein repräsentativer Testfall ist, muß man die Implementierung dessen verstehen, was im Micro-Benchmark gemessen wird. Zur Illustration betrachten wir das oben schon erwähnte Beispiel der Serialisierung von String-Arrays.Nehmen wir also an, wir wollen ausmessen, wie lang die Serialisierung von Strings dauert. Dazu muß müssen Testdaten erzeugt werden, nämlich sehr viele Strings, die dann über einen ObjectInputStream mit readObject() gelesen und über einen ObjectOutputStream mit writeObject() geschrieben werden. Dieses Ein- und Auslesen wird getrennt gemessen und damit erhält man Zahlen über die Performance der Serialisierung von Strings. Das Testprogramm könnte etwa so aussehen:
public class Test {
private static final int SIZE = 1024;
private static String[] createStringArray(int size) {
…
}
public static void main(String[] args) {
try {
String[] sa = createStringArray(SIZE);
ObjectOutputStream out = new ObjectOutputStream(
new BufferedOutputStream(
new FileOutputStream("test.txt")));
long start = System.currentTimeMillis();
out.writeObject(sa);
long diff = System.currentTimeMillis() - start;
out.close();
System.out.println("Writing " + SIZE + " String elements
took: " + diff);
ObjectInputStream in = new ObjectInputStream(
new BufferedInputStream(
new FileInputStream("test.txt")));
start = System.currentTimeMillis();
sa = (String[]) in.readObject();
diff = System.currentTimeMillis() - start;
in.close();
System.out.println("Reading " + SIZE + " String elements took: " + diff);
} catch (Exception e) {
System.err.println("exception occurred " + e);
e.printStackTrace();
}
}
}
Nun ist die Frage: wie sollen die Testdaten aussehen? Das könnte
man jetzt so machen:
|
private static final String TEST_STRING
= "Hello world!";
private static String[] createStringArray(int size) {
for (int i=0; i<size; i++) {
return ar;
|
|
Oder aber auch so:
|
private static final String TEST_STRING
= "Hello world!";
private static String[] createStringArray(int size) {
for (int i=0; i<size; i++) {
return ar;
|
|
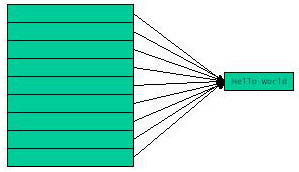
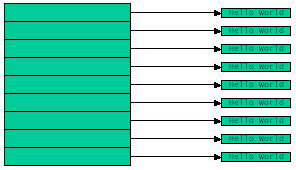
Im einen Fall wird derselbe String verwendet, d.h. es wird ein Array serialisiert, das lauter Referenzen auf ein einziges String-Objekt enthält. Im anderen Fall werden verschiedene Strings verwendet, d.h das Array enthält Referenzen auf verschiedene Strings. Macht das einen Unterschied oder ist es völlig egal? Immerhin wird in beiden Fällen ein Array mit 1024 Strings serialisiert; es könnte also egal sein.
Um beurteilen zu können, ob da ein Unterschied ist, muß der Tester wissen, was er testet, nämlich wie die Serialisierung funktioniert. Die Meßergebnisse sind nämlich drastisch verschieden und es macht sehr wohl einen Unterschied, ob man ein Array mit Referenzen auf einen einzigen oder auf jeweils verschiedene Strings serialisiert. Hier ein mögliches Meßergebnis:
1. Fall: Referenzen auf ein einziges String-Objekt
Writing 1024 String elements took: 70
Reading 1024 String elements took: 10
2. Fall: Referenzen auf verschiedene String-Objekte
Writing 1024 different String elements took: 20
Reading 1024 different String elements took: 40
Beim Schreiben ist die Serialisierung eines Arrays mit Referenzen auf
ein einziges String-Objekt offenbar sehr viel langsamer als die Serialisierung
eines Arrays mit Referenzen auf verschiedene String-Objekte. Das
liegt daran, daß bei der Serialisierung das Geflecht der Referenzen
erfaßt und entsprechend abgebildet werden muß. Wenn ein
Objekt mehrfach referenziert wird, dann soll es nur einmal serialisiert
werden und die Referenzbeziehung soll bei der Deserialisierung wieder so
hergestellt werden, wie sie im Original war. Man spricht in diesem
Zusammenhang von einer homomorphen Abbildung der Objekt-Struktur.
Die homomorphe Abbildung erfordert, daß der Serialisierungsalgorithmus
Meta-Information sammelt, damit er die Mehrfach-Referenzen erkennt und
korrekt umsetzt. Das Anlegen der Meta-Information kostet offenbar
reichlich Performance, wie man an den Meßergebnissen sieht.
Die Serialisierung des Arrays von 1024 Referenzen auf ein einziges String-Objekt
dauert 70 msec, wohingegen das Serialisierung des Arrays mit 1024 Referenzen
auf jeweils verschiedene String-Objekte nur 20 msec dauert.
Umgekehrt ist das Deserialisieren des Arrays mit von 1024 Referenzen
auf ein einziges String-Objekt sehr flott, verglichen mit der Deserialisierung
des Arrays mit 1024 Referenzen auf jeweils verschiedene String-Objekte.
Das liegt natürlich daran, daß im einen Fall nur ein einziges
String-Objekt restauriert werden muß, während im anderen Fall
1024 verschiedene String-Objekte erzeugt werden müssen.
Dieses Beispiel illustriert, daß der Tester sehr genau verstehen
muß, wie die unterliegende Implementierung aussieht. Ohne dieses
Verständnis ist es schwierig zu beurteilen, ob ein Testfall repräsentativ
und aussagekräftig ist, oder nicht. Die gezeigte Messung der
Performance der Serialisierung wird ja gemacht, um diesen Serialisierungsalgorithmus
mit einem anderen Serialisierungsalgorithmus, zum Beispiel über Externalizable
statt Serializable, zu vergleichen. Benutzer-definierte Algorithmen
über Externalizable sind oft nicht homomorph. Dann ist vielleicht
genau der erste Testfall von Interesse. Es kann aber auch sein, daß
Mehrfachreferenzen überhaupt nicht repräsentativ sind.
Dann ist Homomorphie wenig relevant. Welche Testdaten nun letztlich repräsentativ
sind, hängt völlig vom Kontext ab. Aber zunächst einmal
muß ein Verständnis darüber da sein, daß die beiden
Testfälle ganz unterschiedliche Ergebnisse liefern und keineswegs
gegeneinander austauschbar sind.
Hot Spot Optimierung
Weitere Unwägbarkeiten für die Aussagekraft eines Micro-Benchmarks hält die Virtuelle Maschine bereit, wenn sie mit HotSpot-Technologie arbeitet, und das tun heutzutage eigentlich alle JVMs. Java funktioniert prinzipiell so, daß die Virtuelle Maschine zur Laufzeit den sogenannten Java Byte Code interpretiert, den der Compiler aus dem Java Source Code erzeugt hat. Bei den HotSpot-Optimierungen geht es darum, daß die Virtuelle Maschine während des Programmablaufs ein Profiling durchführt, um besonders häufig durchlaufene Programmteile zu identifizieren – die sogenannten Hot Spots. Für diese Hot Spots werden dann während des Programmablaufs Optimierungen durchgeführt. Die Optimierung besteht darin, daß der HotSpot in die Maschinensprache der betreffenden Plattform übersetzt wird. Das bezeichnet man als Just-In-Time-Compilierung. Daher stammt auch der Begriff JIT-Compiler (JIT = Just In Time). Die HotSpot-Technik wurde nämlich anfangs unter dem Begriff JIT-Compiler eingeführt; später hat sich der Begriff HotSpot-Optimierung durchgesetzt.Wann die HotSpot-Optimierung zuschlägt, was sie dann im einzelnen tut und wie sich die Optimierung auf die Messung auswirkt, ist ungemein schwer vorherzusagen. Die Schwierigkeiten rühren zum einen daher, daß die Details der HotSpot-Optimierung abhängig von der Implementierung der jeweiligen Virtuellen Maschine sind. Die HotSpot-Technologie gehört, ähnlich wie die Garbage Collection, nicht zum standardisierten und spezifizierten Teil von Java und seiner Ablaufumgebung. Das heißt, jeder JVM-Hersteller macht, was er will. Zum anderen ist die HotSpot-Optimierung so komplex und kontextabhängig, daß es sehr schwierig ist, einen Micro-Benchmark aufzusetzen, der aussagekräftig ist. Der Kontext, in dem die zu vergleichenden Algorithmen in einem Micro-Benchmark ablaufen, wird immer anders als der tatsächliche Kontext im fertigen System sein. Geringe Unterschiede im Kontext können aber bereits zu einer ganz anderen Optimierung und damit zu ganz anderen Performance-Werten führen.
Auf die Schwierigkeiten, die beim Aufsetzen eines Micro-Benchmark für eine JVM mit HotSpot-Technologie auftreten, wollen wir im nächsten Beitrag eingehen.
Zusammenfassung
Bei einem Micro-Benchmark wird versucht, die Essenz verschiedener alternativer Implementierungen in je einem kleinen Programmstück zu erfassen und die Performance dieser alternativen Implementierungen zu messen und zu vergleichen.Micro-Benchmarking ist ein Tätigkeit, die typischerweise nach dem Profiling eines fertigen Systems im Rahmen von Tuning-Maßnahmen durchführt wird. Micro-Benchmarks sind aber auch während der Implementierung bereits hilfreich und sinnvoll, wenn man sich zwischen mehreren alternativen Implementierungstechniken entscheiden muß..
Das A und O eines erfolgreichen Micro-Benchmarks ist das Aufsetzen eines Testfalls, der zu einem aussagekräftigen Meßergebnis führt und Verfälschungen der Meßwerte vermeidet. Dabei ist eine Vielzahl von Aspekten zu beachten.
- Ganz wichtig ist ein genaues Verständnis der Algorithmen, die gemessen werden sollen (korrekte Annahmen über den Algorithmus, korrekter Testfall, korrekte Testdaten).
- Die Messung selbst muß richtig gemacht werden (effektive Zeitmessung in Java, Ausklammern von Setup/Cleanup, Testdatengenerierung, Protokollierung, etc.).
- Die Ablaufumgebung für den Micro-Benchmark muß die realen Verhältnisse korrekt abbilden (Einkalkulieren von Optimierungen (HotSpot/JIT) und Plattformabhängigkeiten). Das sehen wir uns im nächsten Artikel noch genauer an.
Literaturverweise
| /PERF/ |
Java Performance
URL: http://java.sun.com/docs/performance/ |
| /JNI/ |
Profiling CPU usage from within a Java application - Roll your own
CPU usage monitor using simple JNI
Vladimir Roubtsov URL: http://www.javaworld.com/javaworld/javaqa/2002-11/01-qa-1108-cpu.html |
| /JVMPI/ |
Use the JVM Profiler Interface for accurate timing - Improve performance
analysis by measuring Java thread CPU time
Jesper Gørtz URL: http://www.javaworld.com/javaworld/javatips/jw-javatip92.html |
Die gesamte Serie über Java Performance:
| /KRE1/ |
Java Performance, Teil 1: Was ist ein Micro-Benchmark?
Klaus Kreft & Angelika Langer Java Spektrum, Juli 2005 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/21.MicroBenchmarking/21.MicroBenchmarking.html |
| /KRE2/ |
Java Performance, Teil 2: Wie wirkt sich die HotSpot-Technologie
aufs Micro-Benchmarking aus?
Klaus Kreft & Angelika Langer Java Spektrum, September 2005 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/22.JITCompilation/22.JITCompilation.html |
| /KRE3/ |
Java Performance, Teil 3: Wie funktionieren Profiler-Tools?
Klaus Kreft & Angelika Langer Java Spektrum, November 2005 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/23.ProfilingTools/23.ProfilingTools.html |
| /KRE4/ |
Java Performance, Teil 4: Performance Hotspots - Wie findet man
funktionale Performance Hotspots?
Klaus Kreft & Angelika Langer Java Spektrum, Januar 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/24.FunctionalHotSpots/24.FunctionalHotSpots.html |
| /KRE5/ |
Java Performance, Teil 5: Performance Hotspots - Wie findet man
Memory Hotspots?
Klaus Kreft & Angelika Langer Java Spektrum, März 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/25.MemoryHotSpots/25.MemoryHotSpots.html |
| /KRE6/ |
Java Performance, Teil 6: Garbage Collection - Wie funktioniert
Garbage Collection?
Klaus Kreft & Angelika Langer Java Spektrum, Mai/Juli 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/26.GarbageCollection/26.GarbageCollection.html |
| /KRE7/ |
Java Performance, Teil 7: Garbage Collection - Das Tunen des Garbage
Collectors
Klaus Kreft & Angelika Langer Java Spektrum, September 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/27.GCTuning.html/27.GCTuning.html |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||
Seminar
|
||