| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
Output Iterators
Why they differ from other iterators.
C++ Report, June 1998
Klaus Kreft & Angelika Langer
![]()
In our last two columns we explained (among other topics) the implementation of two iterators from the output iterator category: the insert_interator and the ostream_iterator . (See [ 1 ] and [ 2 ] for further details.) While it is natural that both implementations were highly similar, the way certain member functions were implemented is surprising if not confusing. Typical examples are the implementations of operator++() , operator++(int) , and operator*() , which all do nothing but return *this . In those columns, we explained these peculiarities in the context of each iterator implementation. This time, we want to dig a bit deeper. We want to see if there is a reason for the surprises, and what this reason is. Before we start these examinations let's pass in review iterator implementations in general, in order to point out in which aspects insert_interator and the ostream_iterator differ from a ‘normal’ iterator.
Recap: Implementing An Iterator For The Standard Library
According to interface they support, iterators fall into five different categories:
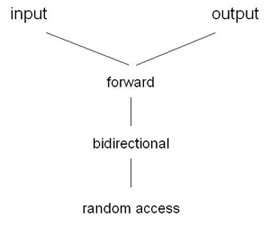
Each category adds new features to the previous one. In brevity:
- Input iterators allow algorithms to advance the iterator and give "read only" access to the value.
- Output iterators allow algorithms to advance the iterator and give "write only" access to the value.
- Forward iterators combine read and write access, but only in one direction (i.e., forward).
- Bidirectional iterators allow algorithms to traverse the sequence in both directions, forward and backward.
- Random access iterators allow jumps and "pointer arithmetics".
Despite the abundance of options that exist for implementing an iterator type, there is a common, canonical approach for implementing iterators. We will demonstrate it using an example: traceIter . The traceIter is an iterator adapter that falls into the forward iterator category in our example. The functionality of the traceIter is quite simple: It adapts an existing iterator and traces when any of its operations get invoked.
The traceIter ’s implementation is given is Listing 1.
class traceIterator : public iterator<forward_iterator_tag,
iterator_traits<Iter>::value_type,
iterator_traits<Iter>::difference_type,
iterator_traits<Iter>::pointer,
iterator_traits<Iter>::reference>
{
public:
traceIterator() {}
traceIterator(Iter fi) : myIter(fi) {}
// plus compiler generated copy constructor
reference operator*() const
{
trace ("operator*() called !");
return (myIter.operator*());
}
pointer operator->() const
{
trace ("operator->() called !");
return (myIter.operator->());
}
traceIterator& operator++
{
trace ("operator++() called !");
myIter.operator++();
return (*this);
}
traceIterator operator++(int)
{
trace ("operator++(int) called !");
traceIterator tmp = *this;
myIter.operator++(0);
return (tmp);
}
private:
bool compare(traceIterator rhs) const
{
trace ("operator==() called !");
return (myIter == rhs.myIter);
}
friend bool operator==<Iter>(const traceIterator<Iter>&, const traceIterator<Iter>&);
void trace(string txt) const { cout << txt << endl; }
Iter myIter;
};
template <class Iter>
inline bool operator==(const traceIterator<Iter>& x, const traceIterator<Iter>&
y)
{ return x.compare(y);
}
using rel_ops::operator!=;
The Base Class Template: Iterator
Any iterator of non-built-in type should be derived from the base class template iterator . The iterator base class is defined as:
class Pointer = T*, class Reference = T&>
struct iterator
{
typedef T value_type;
typedef Distance difference_type;
typedef Pointer pointer;
typedef Reference reference;
typedef Category iterator_category;
};
- its iterator category,
- its value type, which is the type of the value referred to by the iterator,
- the difference type, which is a type that is capable to express the difference between two iterators,
- types associated with the value type: the value’s pointer and reference type.
As we have already mentioned, the traceIter shall be a forward iterator. For this reason, the first template argument for the base class template iterator is forward_iterator_tag , which is a type that is already defined in the standard library. For all other template parameters we use the types that come with the iterator that is adapted.
Operations Required By The Forward Iterator Category
Because the traceIter shall be a forward iterator, the standard requires that at least the following operations can be applied to this iterator:
- Default construction.
- Copy construction.
- The operator * .
- The operator -> .
- The postfix and prefix increment operators.
- Operators == and != which allow to compare two iterators for equality and inequality.
Operations that give access to the referenced value.
The operators * and -> are those operations that give access to the value that is referenced by the iterator. They are typically implemented as the iterator’s public members: operator*() and operator->() . The operator*() returns a reference to the value, while the operator->() returns a pointer to it. Their return types are denoted by the inherited nested types reference and pointer . Note, that for an input iterator (which is similar to a forward iterator except that it allows only read access to the value) the return types are the const reference respectively the const pointer to the value. Their nested type names, however, are still reference and pointer .
Operations that move the iterator.
For a forward iterator, the postfix and prefix increment are the only two operations that can be used to move the iterator. They are typically implemented as the iterator’s public members: operator++() and operator++(int) . They return a reference to the iterator itself so that other iterator operations can be chained to an increment operation. Other iterator categories support additional operations to move the iterator. Bidirectional iterators for example can also be decremented, and random access iterators allow to add and subtract values of the difference type to and from the iterators. They are generally implemented in a similar way as the increment operators.
Operations that allow to compare iterators.
Forward iterators allow to be compared for equality and inequality.
Typically an
operator==()
is implemented
as a global function, because as a public member it would not allow to
behave symmetrically with respect to the two operands. No
operator!=()
is provided because the standard supplies a global template operator
operator!=()
based on the negation of
operator==()
’s
result. Other iterator categories can support more sophisticated ways for
iterator comparison. Random access iterators, for instance, are required
to define an ordering, that is
operator<(),
etc.
Further Reading
This recap is quite brief and focused on those areas where the typical
iterator implementation differs from those of an output iterator. For further
information, take a look at some of our older articles. [
4
]
explains in more detail and with additional background information (including
iterator_traits
)
how iterators from the standard library are implement. [
3
]
explains the same issues about iterators from the original STL. An comprehensive
example for a user defined iterator, which can work with the STL and the
standard library, is given in [
5
].
Output Iterators Are Different
The source code of the insert_iterator given in Listing 2 reveals some differences compared to the general rules for iterator implementation given above.
class insert_iterator :
public iterator<output_iterator_tag,void,void,void,void>
{
public:
typedef Container container_type;
insert_iterator<Conatiner>(Container& c, typename Container::iterator i)
: container(c), iter(i) {};
insert_iterator<Container>& operator=(typename Container::const_reference value)
{
iter = container->insert (iter, value);
iter++;
return *this;
}
insert_iterator<Container>& operator*() { return *this; }
^insert_iterator<Container>& operator++() { return *this; }
insert_iterator<Container>& operator++(int) { return *this; }
protected:
Container* container;
typename Container::iterator iter;
};
Output Iterators Allow Only Write Access
Let's start with those operations that give access to the referenced value. No operator->() is provided. The reason for this is simple: It is not required for an output iterator.
The implementation of the operator*() looks highly surprising. One would expect that operator*() gives access to the value referenced by the iterator That is what the canonical implementation of the traceIter in the example above does: it returns a reference to the value. Why do output iterators like insert_iterator return a reference to the iterator itself instead? The crucial point is that an output iterator is only allowed to give write access to the referred value. So, what should it return? There is no way to specify write-only access to an object in C++; solely read-only access can be expressed in C++ by using the qualifier const . The requirements of prohibiting read-access means that an output iterator’s operator*() cannot give direct access to the referred value at all. Obviously we need a work around to implement write-only access. Let’s consider a typical situation in which the write-only access to the output iterator’s value is needed:
- As user defined operators gets invoked from left to right, insert_iterator::operator*() gets invoke first. It does nothing but return *this .
- This allows that insert_iterator::operator=(typename Container::const_reference value) can be invoked on iter . Next the body of this operator (shown in Listing 2) is executed.
- First, traceIter::operator*() gets invoked, which returns a reference to the value referred to by the iterator.
- To handle the assignment of the new value to the returned reference of the old value, the assignment operator for traceIter::value_type is called.
The fact that an output iterator’s operator*() cannot give direct access to the referred to value has another consequence for the implementation of output iterators. It is reflected in the template parameters that are used for the base class template iterator . insert_iterator for example is defined as:
public iterator<output_iterator_tag,void,void,void,void> { ... };
Immovable Output Iterators
While the implementation techniques described above apply to all output iterators, insert_iterator and ostream_iterator have other implementation details in common that are not necessarily typical for all output iterators. These are their implementations of the prefix and postfix operator ++ , which all do nothing but return *this . The reasons is that both iterators cannot really be advanced.
- The insert_iterator has truly static semantics: It indicates the fixed position before which new elements are inserted. Hence its ++ operators should not have any real effect.
- The ostream_iterator in a way has dynamic semantics: The position of the underlying stream changes whenever an object is assigned to the de-referenced ostream_iterator . This position change is caused automatically when the ostream_iterator ‘s special assignment operator uses the value type’s stream inserter, and there is no task left for the ostream_iterator ‘s ++ operators.
Summary
The implementations of the insert_iterator and ostream_iterator from our last columns showed some interesting similarities. Some of them stem from the fact that output iterator’s operator*() cannot grant direct access to the value referred by the iterator, because there is no way to specify write-only access in C++. The result is an implementation for output iterators that is different from other iterators' implementation. Other similarities are based on the coincidental commonality that insert_iterator and ostream_iterator cannot be advanced.
References
- Insert Iterators
- Stream Iterators
- Iterators in the Standard Template Library (STL)
- Iterators in the Standard C++ Library
- Building an Iterator for STL & Standard Library
Klaus Kreft & Angelika Langer
C++ Report, February 1999
Klaus Kreft & Angelika Langer
C++ Report, April 1999
Klaus Kreft & Angelika Langer
C++ Report, July 1996
Klaus Kreft & Angelika Langer
C++ Report, Nov./Dec. 1996
Klaus Kreft & Angelika Langer
C++ Report, February 1997
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||||
Seminar
|
||||